
|
Table of Contents:
|
||||||||||
Editor: Michael Orr
Technical Editor: Heather Stern
Senior Contributing Editor: Jim Dennis
Contributing Editors: Michael "Alex" Williams, Don Marti, Ben Okopnik
| TWDT 1 (gzipped text file) TWDT 2 (HTML file) are files containing the entire issue: one in text format, one in HTML. They are provided strictly as a way to save the contents as one file for later printing in the format of your choice; there is no guarantee of working links in the HTML version. |
|||
![[tm]](../gx/tm.gif) , http://www.linuxgazette.com/ , http://www.linuxgazette.com/This page maintained by the Editor of Linux Gazette, Copyright © 1996-2001 Specialized Systems Consultants, Inc. |
|||
Write the Gazette at
|
Contents: |
Send tech-support questions, answers and article ideas to The Answer Gang <>. Other mail (including questions or comments about the Gazette itself) should go to <>. All material sent to either of these addresses will be considered for publication in the next issue. Please send answers to the original querent too, so that s/he can get the answer without waiting for the next issue.
Unanswered questions might appear here. Questions with answers--or answers only--appear in The Answer Gang, 2-Cent Tips, or here, depending on their content. There is no guarantee that questions will ever be answered, especially if not related to Linux.
Before asking a question, please check the Linux Gazette FAQ to see if it has been answered there.
 Firewall access...
Firewall access...Hi all,
I have a webserver on our internal LAN that I would like to make accessible to the Internet. I have setup a firewall (RH6.2) using ipchains to allow Internet access from my LAN through an ADSL connection.
The firewall has two NIC's, one for the external (Internet) connection and one for the internal (LAN) connection. The adsl modem/router is setup to NAT the static IP of the router to the IP of the internal server.
i.e.
-->static IP [ADSL modem/router] 1.2.3.4 ----> 1.2.3.5 [ Firewall ]
10.11.12.13 ---> LAN ( webserver=10.11.12.20)
NAT static IP:443 -> 10.11.12.20:443
I know attempts to access the internal server via the static IP are getting to my firewall and being accepted by the input rule, but I don't know what I need to do from there on in to get the request to the LAN ?
On the firewall if I issue the following:
ipchains -C input -p tcp -i eth1 -s <internet address> 443 -d 10.11.12.20 443
it is accepted.
If I issue the following:
ipchains -C forward -p tcp -i eth1 -s <internet address> 443 -d 10.11.12.20 443
it is accepted.
If I issue the following:
ipchains -C output -p tcp -i eth1 -s <internet address> 443 -d 10.11.12.20 443
it is accepted.
Do I need to bridge the two NIC's on the firewall ? Do I just put in some routing entries ? DO I have to do anything more to the forward and/or output rule to get the packets through ?
As you've probably concluded by now I new to ipchains, although I have read many of firewall/ipchains/bridge HOWTOs, so any help would be gratefully accepted
Thanks
Gavin.
This is a tiny sample - a number of other home/SOHO packet filtering and defensive firewall questions are in the queue to be answered. But it would be really nice to see an article for ipchains... or especially, the new netfilters, since they are a bit different... which is aimed for readers who are not already network administrators. -- Heather.
Mandrake Linux and Cable modemsI am running a home peer to peer net work of 3 PS's running Win98 and internet sharing to access the internet through my cable modem (Telewest Blueyonder). On the PC that acts as the gateway to the internet, I have two removable drives, one runs win98 (obviously...lol) and the other is running Mandrake 7.1. What I would like to do is to Dump Win98 from the gateway PC and go over to Linux completely, while the other two PC's will continue to run win98. Now what I want to be able to do is have a similar set-up to my win98 network, where the three PC's all have access the internet.
Have you a complete numpties' guide to doing this, bearing in mind that I have little or no Linux experience. i.e. the definitive guide to getting cable modems to run under Mandrake 7.1.
Many thanks
Ian Garvie
There is a quiet little utility called Masqdialer which is supposed to be for exactly this purpose. However, I've never used it, though I've been tempted to give masqmailer a try ... that's a mailer that might be good for people on dialups, because it's smart about whether you're online, and via what ISP.
An article on either of these, or the general case of a sometimes-disconnected setup, would be a good read for newbies and old hands alike.
Trying to build a crash course for myself...Hi there. As you probably gathered from the subject header, I'm a fairly new Linux user--I used it for a few months a while back with a RH 6.0 install, but ended up back in MSFT land when I had trouble replacing my NIC. In any event, I just installed Mandrake 7.2, and I've been doing pretty well getting the system to do everything I need/want it to do over the last several days.
HOWEVER: I'm using it almost exclusively inside X/KDE, and I'm well aware that I'm really not learning anything about how to properly setup/use/maintain a Linux system. So I've been browsing about the web, IRC channels, newsgroups, etc., and reading pretty much any documentation that's aimed at new users. The problem is that just reading everything doesn't teach one all that much when it comes to actually trying to use the system.
What all this buildup is leading to is: what would you recommend as practical projects to undertake as learning exercises for a fairly new user? At the risk of sounding immodest, I'm quite comfortable and conversant with computers and computing in general, hardware setup, programming, etc.--but only in a MSFT world. I'm not terrifically afraid of breaking my system--everything is well backed-up, and I've been working with Windows products for long enough that the prospect of reformat/reinstall isn't even vaguely daunting. I just don't know what it is I should be -trying- to do such that succeeding in the endeavor would involve gaining understanding of the system.
Sincerely, Matt "sorry for the SPAM" Cherwin
Better answers than "read back issues of the Gazette" will be published, if you copy them to .
reading tapes from another operating systemThanks for taking time to answer questions.
I have some tapes (1/4" cartrage - 120MB format) that I would like to make copies of. Now, I know that they were made on an AS/400, But as I see it; data is data - if I can figure out what format it is in.
The hardware is an AMD-K6/II 500 with an Adaptec AIC-7850 narrow SCSI controler connected to the PCI bus. There are 3 devices connected to this SCSI controler. 1 TANDBERG SLR1 150MB tape drive (device ID 6 /dev/st1). 1 TANDBERG SLR2 525MB tape drive (device ID 0 /dev/st0) and 1 philips CDD 2600 (device ID 4 /dev/scd0) which is at the end of the cable with the termination jumper installed.
The software is a heavily modified RedHat 5.0. The kernel version is 2.2.15 (with the needed network utility updates) gcc(egcs)2.95. With all the updates I figured that the old mt command probably didn't support the current IOCTLS on the st driver - so I deleted it and got the source code for mt-st v. 0.6 (the old one was 0.4)
At this point I can create tapes under linux and read them back reliably. however, This is all working with default settings.
Now for the interesting part. when I try to read a tape created on my as/400 (the same drive that is now in my linux machine as st0) I get the complaint st0: Incorrect block size. the mt status command shows Tape Block Size = 512, Density code 0x11(525 tape) Begining of tape and Write Protect.
If I try to change the block size - I first do a rewind(as per the tandberg manual) then I do a setblk 32768 (does the same thing with setblk 512) and the response is: st0: Error with sense data: [valid=0] Info fld=0x0, Current st09:00 sense key Illegal request aditional sense indicates End-of-partition/medium detected. When I follow the procedure on the tape I made under linux and use a block size of 512 everything works fine. What am I missing? PS although IBM provides no documentation their tape file listing program seems to indicate that the block size might be 32768 bytes.
Layton
We have a lot of good people, but not so many with AIX experience. If any of you with experience in an IBM/Linux heterogenous environment ... or who know about what tapes are really saying when they do this... have some good hints for Layton, send them to .
PS. A big thank-you to the answer guy for some of his answers a year or two ago that have gotten me this far. Especially on the SCSI termination which I should have remembered from my macintosh days (only 10 years ago).
You're welcome, of course!
PPS. I hope USA.net sends a plain text version of this since I am not at work where I have an e-mail account that will let me specify what I want to send.
It came through fine.
Memory mysterysetup: mainboard PC Chips M807, kernel 2.2.15 (Mandrake 7.1), memory 2 stick of 128MB PC100
If I put insert only one memory stick BIOS finds correctly 128MB but Linux only 64MB. After addition append = "mem=128M" to lilo.conf Linux finds 64MB again. If I insert 2 memory sticks BIOS finds correctly 128MB but Linux only 15MB! After addition of append= "mem=256M" to lilo.conf Linux finds 64MB. Any suggetion? BTW Win98 see always correct RAM size.
Thanks Jan Jakubik
Someone with a good memory ![]() can slip us a tip in the right direction by mailing .
can slip us a tip in the right direction by mailing .
The cardboard box.on 29 mar 2000 the question was asked who invented the cardboard box. The answer is Robert Gair. I found this information at http://www.europen.be/basics/understand/und6_types.html
I am doing research for a School speech on the inventer of the cardboard box. (this is no joke) Your website is great and I will visit often. I am glad I found you.
[Heather] You're doubly lucky as well; one of the Gang decided to answer it, and it was sufficiently amusing that we published it even though it's off topic. If you end up with any questions about a free computer operating system whose mascot is a cute penguin, don't hesitate to ask.
Happy New Year !!! - huh ?Heya Heather,
better late than ...
Happy New Year and all best wishes to you and all of Linux Gazette !
Yours linuxely,
Wilf (French/English => German translations)
HiOn Wed, Jan 24, 2001 at 10:47:23AM -0700, Spicer wrote:
I just ran across a link to one of your messages and was wondering... do I just ask you a question?
If it's related to Linux technical support, yes. There are about ten people in The Answer Gang, and if any of us feel qualified to respond, we'll e-mail you back. Then, the question and answers will be considered for publication in the next issue of Linux Gazette. The submission address is .
We'd appreciate it if you'd peruse a few back issues of Linux Gazette first to see if your question has already been answered. (The LG search engine is useful for this.)
Also, if you have any Linux tips that might be helpful for other readers, please send them in too. Both beginner and advanced tips are appreciated, because we have a wide variety of readers.
RE: "What's a smoothwall?" from issue 61 TAGRE: http://www.linuxgazette.com/issue61/lg_answer61.html#tag/36
Mike Orr asked "What's a smoothwall?"
Smoothwall is a browser administered, Linux-based, open-source, ppp firewall and router appliance. It's targeted at older 386 and 486 systems gathering dust in a closet.
See http://sourceforge.net/projects/smoothwall -or- http://www.smoothwall.org
The sourceforge page has links to the mailing lists and forums where Jim Watkins' original question about diald on the smoothwall has been discussed and answered many times...
BTW- Smoothwall would make a great subject for an upcoming Linux Journal article! ![]()
"Take a look at one's desktop config. That'll give you an idea where they are with Linux." - an unidentified O'Reilly author @ ALS 2000.
e-mail thread on 'su not working' in gazetteWay back in time the editor wrote: "Regarding the e-mails: they're still worth printing because they may help somebody else." from: http://www.linuxgazette.com/issue47/lg_mail47.html
And by jove, they did. Thanks a bunch, it has lifted a weight from my shoulders, I had the same problem.
Glad the archives ares still up.
Regards
Etienne Posthumus
Monitor goes blankThanks for your help!
-- Marius Andreiana
Will Windows or Linux be "The Road Not Taken"?The Answer Gang,
Hello! My name is Terrell Phillips and as a "newbie", I've been learning Linux via KeyStone Learning Systems video training series.
I sincerely hope that my ongoing Linux training will not have been in vain as I can find no postings for any entry-level workstation jobs here in Atlanta for newbies. Even if I were to have attained my RHCE, the only Linux jobs I've seen posted on the Internet require a working UNIX background foremost.
Attending my local Atlanta Linux Enthusiasts user group meetings, it seems that advanced users attending the meetings are not thrilled at the prospect of helping newbies acquire initial work experience, but rather give every impression that somehow Linux will blossom someday into the corporate world. Apple Computer made the same mistakes early on by marketing their OS to new users and user groups as the best choice for getting work done efficiently. Later, Apple began boasting that their platform was the best and most rapid developer for cross-platform apps. But there was just one little problem. Apple didn't want anyone especially new users to know upfront. No instructor-led training programs for software development were/are in place, nor did Apple partners care to offer the same. And you could count the non-graphics jobs using Apple Computers on one finger.
The point is, that unless the entire Linux community decides to truly help their own, "newbies" will retreat back to using Microsoft for careers. A mature forest of Linux trees lacking little new tree saplings growing all around them won't be a forest for long.
It is a very smart move on the part of the various Windows user groups to see to it that their "newbies" find entry work quickly.
Tonight, I have set my Linux notes printed off various websites along with my training videos aside in favor of learning Visual Basic, MS Access 2000 and SQL. With some training and initiative on my part, I can find entry-level work in a Windows world.
I wish I had better news.
Sincerely,
Terrell Phillips
1000 thanks!Dear answerguy,
I am incredibly happy that I could save one of my Linux-installs with the help of an answer you gave to one of those people before (retrieved with a search-engine) on lost root-passwords!! All the other stuff that I had found before didn't make it ('linux single' always ended at the login-prompt!) and the rest said 'new install'. Now I have the task to find out, who had tempered with the machine across the network (Internet), because I have been using this password for ages, I'm a sysadministrator and have clearly never had too many drinks since I had logged on successfully the last time! - The machine is a server behind closed doors ...!!
Have a drink on me!
Uwe
The Gazettethe gazette looks very nice -- sort of a moderated discussion, i guess. like a civilized slashdot, or an old letters to the editor section of a magazine.
john
[[email protected]: "ls -lRat" does not work on FTP server]We seem to have received notes from more than one site about ftp being strange...
Ferg (gferg from sgi.com)
Hi -
I maintain the LDP mirror(s) of the LG, and the last couple of times I've run our 'mirror'based update script, I received a number of errors, such as:
Too many files to delete, not actually deleting (3626 > 3278) Too many directories to delete, not actually deleting (398 > 358)
I'm pretty sure I know how to correct that in the mirror config file. More troublesome are these (from my last run):
Failure on 'RETR pub/lg/www_root/.glimpse-eye.jpg' command
Failed to get pub/lg/www_root/.glimpse-eye.jpg: 550
'pub/lg/www_root/.glimpse-eye.jpg': No such file or directory
Failed to get file 550 'pub/lg/www_root/.glimpse-eye.jpg': No such
file or directory
Failure on 'RETR pub/lg/www_root/404.html' command
Failed to get pub/lg/www_root/404.html: 550
'pub/lg/www_root/404.html':
No such file or directory
There are an enormous number of those errors.
Did anything change on the host site? Was there some massive restructuring done to have caused this?
Here are my configuration parms:
package=LG
site=ftp.ssc.com
comment=Linux Gazette
remote_dir=/pub/lg/www_root
local_dir=/public/html/LDP/LDP/LG
I hope you can help. Thanks in advance.
best regardsm -- Greg Ferguson
Spammers harvesting Email addresses.[Ira Abramov is one of LG's mirrors.] I have been getting spam to an address I gave you as a contact for an LG mirror I was running, yet it was posted to a webpage without my approval, and I have been getting a lot of Spam through it lately.
please remove nospam-lgmirror-20000426 at.the.site ira.scso.com from the mirrors page at http://www.linuxgazette.com/mirrors.html, as well as from your lists. the correct contact from now on is webmaster-nospam-lgmirror-20001205 at.the.site linux.org.il and they won't appreciate spam either. I sugest you somehow cloak the mail addresses on that page, remove the mailto: links or use some other mechanisms, but do not leave the current situation broken like this.
[Heather] I actually tweaked the above so neither would turn into a hotlink. Normally they would.
I have removed the link as you requested. Change visible at 5pm (UTC-0800).
In general, it's our policy to publish the contact addresses of the mirrors because (1) we need the information and this is where we store it, and (2) readers need to be able to contact a mirror if there's a problem using it--that's why it's called a contact address. As for spam, I get it too--30% of the messages to are spam.
[Ira] ok, possible ideas. instead of a mailto: link, put the address plain, maybe even add a space before and after the @ sign. that way one can still cut and paste it for an individual contact but not harvest it automaticly with a robot... there are ways.
for the more advanced ways there are simply CGIs. see the following address (which spammers aren't smart enough to handle)
http://scso.com/cgi-bin/m
the CGI that does this little magic looks like this:
> cat /home/httpd/cgi-bin/m
#!/usr/bin/perl
$address=substr($ENV{'PATH_INFO'},1);
$address=~ s/nospam\@dht/\@/g;
print "Location: mailto:$address\n\n";
exit(0);
4 lines of perl, and spammers never harvest those addresses (tested!)
where there's a will, there's a way... I love ssc for it's great donation to the community, I just ask that you don't repay the kind people mirroring you by exposing them to spam...
[Mike] The trouble is, that requires a CGI script, so it won't run on the mirrors, and it certainly won't work on the CD-ROM version.
Is it time to make all e-mail addresses non-clickable? Your Editor is undecided.
[Heather] You don't want to make it easier for spammers (who use scripts and have delusions of time on their hands) to get ahold of you than the people who would have a legitimate reason to reach you. I suppose we could have various mirrorNN.LocnCode kinds of addresses at SSC, where we could attempt to pre-filter a bit. (are you getting worse than 30 % spam?)
That way you as mirror admin get some possible defense, at least your actual address isn't exposed until you reply, there is the backup that SSC learns about mirror problems sometimes, and some people might actually feel we made it easier to reach somebody in case of errors.
[Don Marti] Hiding email addresses from spammers is letting spammers define the terms of our conversation. I'm against it and don't participate in any list that does this form of "cowardice by proxy" for me.
[Dan Wilder] Though in less absolute terms than Don, I'll add my voice to those not favoring cowardice by proxy.
Let 'em try and spam me. I'll either /dev/null their mail, or hunt 'em down with a rusty bottle opener!
article - game presentationIt was all D&D back then, and Traveller.
Never heard of these... I've started on ZX spectrum, with Dizzy being my favourite(s)
NEVER HEARD OF?? I gotta publish this. The generational difference between games. Do you mind if I publish this letter?
If you publish that I never heard of D&D and Traveller ? no, I don't mind. Maybe you write about these too. (are they still available ?)
I don't do gaming, so I don't know. Cc'ing a gaming friend.
Ogre, this guy is one of my correspondents for the Linux Gazette ezine. He's too young to have heard of Dungeons & Dragons and Traveller, the only role-playing games I ever had the least bit involvement with. Do they still exist or are they long gone?
[Heather] There are an avid batch of Traveller players in my area although I don't game with them, and D&D recently released a new edition. Not only are they available, but you can find traveller players on IRC, a lot of support software for D&D gamemasters... uh, well for some other platform anyway. My traveller playing friend is famous for Penguin Artillery.
LGAfter dropping you a mail about issue 60, I thought I was pen a few lines on my venture in Linux and just why LG has made the transition so painless.
It is redundant of me to mention just how fantastic LG is? I can hear you all muttering now about stating the bleeding obvious. For me, the most curious thing is to note the range of interest, from the rank Linux newbie to input from individuals who are quite clearly among some of the knowledgeable to be found, and all receive the same warm response (unless they happen to be some poor Windoze momo with a Winmodem ![]()
Anyway, I thought I would share my recent real plunge into Linux and perhaps lend some cheer to all the neophytes out their coming to terms with Windoze withdrawal and faced with the murky morass of Linux. I should mention I am not new to computers, I have used a plethora of Uncle Bill's offerings, and in all fairness, I am possibly the only person in the world to never had had any problems at all, I can count my 'Blue Screens of Death' on one hand. Suffice to say, I have no problems with MS, as a bit of a closet gamer, it serves it purpose.
Linux on the other hand, was always something that I presumed was not for me, I had once upon a time installed some ancient Red Hat, and a mouldy Slackware, both of which suffered a format quite promptly. It just all seemed too complicated and of limited appeal to where I was at the time. I tend to spend a lot of time on the Net now, so about 2 weeks ago I decided to have another look. I need to make it very clear, the sum total of my Linux knowledge prior to biting the bullet and trying it again, was the ability to type 'ls - -la, uptime, rm and a few other sundry commands that everyone anywhere normally picks up over the years, in other words it was all virgin territory. With that in mind, thus begins my journey.
A friend of mine mailed me Mandrake 7.2 (along with Storm, Corel, Slackware 7.0, Redhat 6.0 and a bunch of other distros. I had once installed a prehistoric Mandrake, so my victim was preordained. My system is fairly standard, a PIII 850, 192mb ram, Voodoo 3 3000, SB Live, Adaptec 2940 + 2944, network card etc. I chose custom install, and prepared myself for what I was sure would be many hours of getting things to actually work post-install. To say I was impressed was an understatement, Mandrake install was easier and clearer than anything Bill Gates ever threw at me, and HW detection? every thing was 100% up and running without any intervention on my part. I am a console sort of person, and X is just something I will use when I am forced to, but once I booted up, a quick startx a boy was I shocked, X 4.0 and KDE2 all running with full 3d acceleration. I fired up Tux Racer as I was checking things out, and it bodes well, Linux has come a long way since I toyed with it. I have a feeling either MS will be forced to meet Linux head on one of these days, MS Linux maybe? Since from what I see, once the Linux community manages to implement anything akin to DirectX and thus gain wide support from the gaming industry, the Redmond Wunderkind will be on a fast track to oblivion if they don't have some contingency plans.
Ooops back to nub of it all. Ok so X was working, so I quickly exited the session, to get as far away from Netscape as I could. Like most people 'new' to Linux, I was a little overwhelmed at the sheer vastness of it all, and headed as fast as I could for the most speedy route to begin the learning process. Thank god for man pages, info pages, HOWTOs and the like, I was soon starting to feel like this was one mountain I could conquer.
Next up PPP, or was it? No, silly me used fdisk to partition initially and I made Linux one single partition didn't I. tsk tsk, well I wanted to learn more, so.... REINSTALL, this time with Mandrake's own tool, which in a word is awesome for the newer users, result:
Filesystem 1k-blocks Used Available Use% Mounted on /dev/hda5 489992 55987 408705 12% / /dev/hda8 241116 1481 227187 1% /boot /dev/hda10 2514172 150644 2235816 6% /home /dev/hda1 7158976 5588472 1570504 78% /mnt/win_c /dev/hdb1 6285144 1685608 4599536 27% /mnt/win_c2 /dev/hde1 8233232 12 8233220 0% /mnt/win_c3 /dev/hdg1 2498940 12 2498928 0% /mnt/win_c4 /dev/hdh1 2498936 418500 2080436 17% /mnt/win_c5 /dev/hda7 241116 170 228498 0% /tmp /dev/hda11 7937796 3655320 3879248 49% /usr /dev/hda9 489992 65081 399611 14% /var /proc/bus/usb 489992 489992 0 100% /proc/bus/usb
I am happy with that (the Win drives are games + multiple backups), so then on to PPP, unlike many who have sad tales to tell, my small local ISP has a handy dandy tar.gz file to set things up, unpack, run, few quetions like pass, modem and such, type ./ppp-on and viola! Nice some ISP's give a damn about their users... fantastic.
After a day or two, I had devoured every HOTWO, I made life easier for myself too with:
alias ht='cd /usr/share/doc/HOWTO/HTML/en;lynx index.html'
My little superhighway to fast help and my 1st ever alias, oh did I mention Netscape sucks and Lynx is sublime ![]()
Now I was wanting some access to Linux information, time to search the Web. I suppose I was lucky within a minute of two, I came across the Linux documentation Project and thus Linux Gazette. After perusing the online issue, I knew where it need to be, so FTP Mirror here we come and some time later all 60 issues on my HDD.
Ever since for the last week or so, I have been wading through the plethora of tips (Isn't Heather just the living end eh? ![]() I have managed to come to terms with Linux file structure, I have personalised bash and my environment to my liking, I have edited most of my .rc files, for example custom hdparm parameters, along with removing things like telnet and ensuring ssh is up and running. Almost everything I have learnt, is due to Linux Gazette, it never ceases to amaze me how much their is to learn. Only a few days ago, a friend of mine who has been using Linux for four years came over, to help me with a wine.conf issue, and I ended up teaching him a few things and minor commands he had never used nor knew existed. It just goes to show how extensive Linux is.
I have managed to come to terms with Linux file structure, I have personalised bash and my environment to my liking, I have edited most of my .rc files, for example custom hdparm parameters, along with removing things like telnet and ensuring ssh is up and running. Almost everything I have learnt, is due to Linux Gazette, it never ceases to amaze me how much their is to learn. Only a few days ago, a friend of mine who has been using Linux for four years came over, to help me with a wine.conf issue, and I ended up teaching him a few things and minor commands he had never used nor knew existed. It just goes to show how extensive Linux is.
I suppose the point of my taking the time to pen a few words, is to reassure those new to Linux that much of the rubbish that gets bandied about that Linux is "hard" is in practice misguided. Certainly some distros are not as user friendly as say Mandrake or Red Hat to install, and presume a certain working knowledge, but any Linux once up and running, provided you are have a passion for computers and an enquiring mind is most certainly not rocket science, in other words, if you are content to click a mouse, and care nothing for what might live beneath the hood, then perhaps you deserve nothing more than Windoze.
I fit the profile of a normal advanced Windoze user, I can edit registry crap, trouble shoot .dll problems and all that jazz, but I certainly cannot write one line of code, thus I am sure that many newer LG readers wil relate to my experiences as a new Linux user. Sure I have had to stop and run for a man page at times, and been totally stumped at times, for example getting Wine to work (which I use for one prog only) made me tear my hair out, on the other hand VMware was painless. At the end of the day, it is only by overcoming problems that you learn, and the sudden "ZAP" of revelation once you master some problem makes it all worthwhile, Linux certainly lights my fire, a tinkerers delight, and I am sure that in the future, when I look back on my 7 years of Windoze, and compare it to the years of Linux to come (or whatever LInux becomes) I will wonder why I never made the change sooner. One thing I know for certain, I will never be tempted to buy a Winmodem ![]()
Security articles[A guest commentary from our News Bytes editor. I asked him to summarize the controversy on Slashdot regarding SSH/SSL vulnerabilities, and to assess whether we need an article on it. -Mike]
Date: Thu, 28 Dec 2000 16:55:56 +0000 Subject: Re: Late News Bytes additions From: Michael Conry
Hi Mike, please find attached the ( ../issue61/lg_bytes61.html ) news bytes 61 file. I did go through the SSH issues, and summarised them briefly. I kind of skirted around the SSL because it seemed less clear cut, and very much an issue of implementation and protecting users from themselves. Most discussion in the links focussed on SSH in any case.
I would recommend, not an article on Holes in SSH, but rather an article on security in general. Lots of contradictory messages on Slashdot indicate that people still don't really understand what is going on or how exactly to administer a public key system.
The issues are not new, but are inherent in public key systems. pgp,gnupg is the same (how can i be sure the key i think is yours is really yours?). The biggest issue is probably users (lusers) ignoring warning messages.
The new dsniff software is probably worth commenting on also. I included a link in my short discussion, but have not studied it. What could be very interesting would be for an article to highlight how to use tools like this to strengthen your system/network by scrutinising it and probing it. Focus tends to be on how these tools allow malicious people to break other people's systems.
Linux On Your Desktop @ Linux Gazette"Linux On Your Desktop" is an important article. But Linux-Gazette should `edit out' several English mistakes. Syntax and Spelling. This does not help Linux get a professional image.
[Mike] Linux Gazette is not a professional publication--it's a volunteer publication. We do not have the resources to proofread and reword every article. That would take 10-20 hours per issue. Would you like to volunteer to proofread a few articles each issue? If you're willing, it would certainly be welcome.
Linux Gazette LogoIt would be so nice if I could come to your index.html page and not have to load a 40k logo. Wouldn't an 8k do nicely? ![]()
[Mike] We'll consider this for the next version of the Gazette, but most requests have been asking for more graphics, not less. 8 K would get us a logo that's just a bit bigger than the sponsorship logos are now. Since our graphic designer put a lot of time into getting the shape and color of the logo just right, I don't want to ask him to somehow manage to keep the same look while squeezing the file down to a fifth of its size. It is a jpg, which is the most efficient graphics format there is.
In any case, doesn't it just load once in your browser and then the cached version is used thereafter?
Thanks for your feedback.
[Richard Storey] Not knocking the great design of the logo, but aside from slow loading it creates its motif doesn't match that of the rest of the site. As far as graphics go, look at Yahoo. They've managed to keep their site just ahead of text level, which I use most of the time anyway. There's a lot to be said for a site which is designed cleanly, neatly, for fast load times, but is rich because of its content rather than *eye-candy*.
[Heather] You're quite welcome to visit us in lynx, the world's fastest browser, since it wastes no time whatsoever on eyecandy ... unless you absolutely insist on working at it. My normal surfing mode is lynx-ssl with zgv wired into my MIME support, so I can see an occasional photo if I feel like it.
We make a serious effort to be lynx clean around here anyway, since that's how we produce the text version of the download.
 |
Contents: |
Submitters, send your News Bytes items in PLAIN TEXT format. Other formats may be rejected without reading. You have been warned! A one- or two-paragraph summary plus URL gets you a better announcement than an entire press release.

 February 2001 Linux Journal
February 2001 Linux JournalThe February issue of Linux Journal is on newsstands now. This issue focuses on Kernel Internals. Click here to view the table of contents, or here to subscribe. All articles through December 1999 are available for public reading at http://www.linuxjournal.com/lj-issues/mags.html. Recent articles are available on-line for subscribers only at http://interactive.linuxjournal.com/.
CalderaOREM, UT-January 16, 2001- Caldera Systems, Inc., today announced the release of Caldera Volution, a Linux management solution that reduces the cost of implementing and managing Linux systems. With Caldera Volution, administrators can use policies and profiles to manage thousands of Linux systems, without having to individually manage or touch each. Volution is distribution-neutral - designed to work with all major Linux distributions, and provides broad management functions. Volution will significantly benefit anyone needing to manage multiple Linux servers and desktops.
Caldera Volution is a Web-based remote management solution that allows administrators to manage Linux systems from anywhere at anytime. It is directory-based utilizing the inherent strengths of LDAP directories. Directories provide two major benefits: They give administrators a place to not only store information, but a logical and intuitive way of managing network resources. Volution supports three major LDAP directories, Novell's eDirectory, OpenLDAP and iPlanet. OpenLDAP and eDirectory ship with the product. Volution will ship in nine additional languages including Chinese - simplified and traditional, French, Italian, German, Spanish, Japanese, Korean and Portuguese. The suggested list price for Caldera Volution is US $2995. Volution ships with the Volution software, Novell eDirectory and OpenLDAP, a secure Web server and licenses to manage up to 10 nodes. Additional nodes are sold separately.
SuSENuremberg, Germany - January 12, 2001 - Today, SuSE Linux presented the second generation of e-mail solutions for commerce, public administration, workgroups and all others needing professional e-mail communication.
The SuSE eMail Server II is an Open Source solution, based on reliable components consistent with Internet standards such as SMTP, IMAP4, POP3, and LDAP. In accordance with the IMAP standard (Internet Message Access Protocol), the SuSE eMail Server administrates mail on a central server. The server supports all common e-mail clients, including Microsoft Outlook, Outlook Express, Netscape Messenger, and Eudora or via the included Web-Mail Client IMP.
The SuSE eMail Server II can be obtained from SuSE or from software retailers from the beginning of February onwards. The suggested retail price for one server is 255 Euro and includes a manual, 60 days installation support and the server backup solution Arkeia from Knox Software.
Nuremberg, Germany - January 19, 2001 - SuSE Linux and Lotus announced the SuSE Linux Groupware Server. The new server combines the comprehensive functionality of the Domino Messaging and Web Application Server with the cost advantages and the reliability of the Linux operating system. This provides a basis for improved business processing and customer relations.
With more than 50 million users worldwide, the product-integrated Domino Server delivers efficient tools for groupware, workflow, messaging and scheduling. Domino also provides a flexible basis for fast web and messaging application development.
SuSE Linux Groupware Server can be purchased from SuSE or software retailers, beginning February 2001. The suggested retail price is Euro 2.555,00 + VAT.
For further information on SuSE Linux Groupware Server, please visit SuSE's Groupware web page Groupware web page.
Upcoming conferences and events|
|
|
| Linux Expo, Amsterdam |
January 23-24, 2001 Amsterdam, Netherlands http://www.linuxexpoamsterdam.com/EN/home/ |
|
|
|
| 6th USENIX Conference on Object-Oriented Technologies and Systems |
January 29 - February 2, 2001 San Antonio, TX http://www.usenix.org/events/coots01 |
|
|
|
| LinuxWorld Conference & Expo |
January 29 - February 2, 2001 New York, NY http://www.linuxworldexpo.com |
|
|
|
| Linux Expo, Paris |
January 31 - February 2, 2001 Paris, France http://www.linuxexpoparis.com/EN/home |
|
|
|
| Open Source and Free Software Developers' Meeting |
February 3-4, 2001 Brussels, Belgium http://www.osdem.org |
|
|
|
| Internet World Canada/ISPCON |
February 5-8, 2001 Toronto, Canada http://www.internetworld.com |
|
|
|
| The O'Reilly Peer-to-Peer Conference |
February 14-16, 2001 San Francisco, CA http://conferences.oreilly.com/p2p/index.html |
|
|
|
| Internet Appliance Workshop |
February 20-21, 2001 San Jose, CA http://netapplianceconf.com |
|
|
|
| Bang!inux |
March 5-7, 2001 Bangalor, India http://www.Banglinux.com/ |
|
|
|
| LINUX Business Expo |
March 7-9, 2001 Sydney, Australia http://www.linuxexpo.com.au |
|
|
|
| Computerfest |
March 10-11, 2001 Dayton, OH http://www.computerfest.com |
|
|
|
| Internet World Spring |
March 12-16, 2001 Los Angeles, CA http://www.internetworld.com |
|
|
|
| COMDEX Canada West |
March 13-15, 2001 Vancouver, B.C. http://www.key3media.com/comdex/canadawest2001 |
|
|
|
| Game Developers Conference |
March 20-24, 2001 San Jose, CA http://www.gdconf.com |
|
|
|
| CeBit |
March 22-28, 2001 Hannover, Germany http://www.cebit.de |
|
|
|
| 3rd USENIX Symposium on Internet Technologies and Systems |
March 26-28, 2001 San Francisco, CA http://www.usenix.org/events/usits01 |
|
|
|
| LinuxBazaar |
March 28-29, 2001 Prague, Czech Republic http://www.linuxbazaar.cz |
|
|
|
| Colorado Linux Info Quest Conference & Expo/CLIQ 2001 |
March 29-30, 2001 Denver, CO http://thecliq.org |
|
|
|
| Association of C/C++ Users (ACCU) |
March 29-31, 2001 Oxford, England http://www.accuconf.com/ |
|
|
|
| LINUX Business Expo |
April 2-5, 2001 Chicago, IL http://www.linuxbusinessexpo.com |
|
|
|
| Linux Expo, Madrid |
April 4-5, 2001 Madrid, Spain http://www.linuxexpomadrid.com/EN/home |
|
|
|
| Linux Expo Road Show |
April 23-27, 2001 Various Locations http://www.linux-expo.com |
|
|
|
| Linux for Industrial Applications 3rd Braunschweiger Linux-Tage |
May 4-6, 2001 Braunschweig, Germany http://braunschweiger.linuxtage.de/industrie |
|
|
|
| Linux@Work Europe 2001 |
May 8 - June 15, 2001 Various Locations http://www.ltt.de/linux_at_work.2001 |
|
|
|
| Linux Expo, Sao Paulo |
May 9-10, 2001 Sao Paulo, Brazil http://www.linux-expo.com |
|
|
|
| SANS 2001 |
May 13-20, 2001 Baltimore, MD http://www.sans.org/SANS2001.htm |
|
|
|
| 7th Annual Applied Computing Conference |
May 14-17, 2001 Santa Clara, CA http://www.annatechnology.com/annatech/HomeConf2.asp |
|
|
|
| Linux Expo, China |
May 15-18, 2001 Shanghai, China http://www.linux-expo.com |
|
|
|
| SITI International Information Technologies Week OpenWorld Expo 2001 |
May 22-25, 2001 Montreal, Canada http://www.mediapublik.com/en/ |
|
|
|
| Strictly e-Business Solutions Expo |
May 23-24, 2001 Minneapolis, MN http://www.strictlyebusinessexpo.com |
|
|
|
| Linux Expo, Milan |
June 6-7, 2001 Milan, Italy http://www.linux-expo.com |
|
|
|
| USENIX Annual Technical Conference |
June 25-30, 2001 Boston, MA http://www.usenix.org/events/usenix01 |
|
|
|
| PC Expo |
June 26-29, 2001 New York, NY www.pcexpo.com |
|
|
|
| Internet World Summer |
July 10-12, 2001 Chicago, IL http://www.internetworld.com |
|
|
|
| O'Reilly Open Source Convention |
July 23-26, 2001 San Diego, CA http://conferences.oreilly.com |
|
|
|
| 10th USENIX Security Symposium |
August 13-17, 2001 Washington, D.C. http://www.usenix.org/events/sec01/ |
|
|
|
| HunTEC Technology Expo & Conference Hosted by Hunstville IEEE |
August 17-18, 2001 Huntsville, AL URL unkown at present |
|
|
|
| Computerfest |
August 25-26, 2001 Dayton, OH http://www.computerfest.com |
|
|
|
| LinuxWorld Conference & Expo |
August 27-30, 2001 San Francisco, CA http://www.linuxworldexpo.com |
|
|
|
| Linux Lunacy Co-Produced by Linux Journal and Geek Cruises |
October 21-28, 2001 Eastern Caribbean http://www.geekcruises.com |
|
|
|
| LinuxWorld Conference & Expo |
October 30 - November 1, 2001 Frankfurt, Germany http://www.linuxworldexpo.de/linuxworldexpo/index.html |
|
|
|
| 5th Annual Linux Showcase & Conference |
November 6-10, 2001 Oakland, CA http://www.linuxshowcase.org/ |
|
|
|
| Strictly e-Business Solutions Expo |
November 7-8, 2001 Houston, TX http://www.strictlyebusinessexpo.com |
|
|
|
| LINUX Business Expo Co-located with COMDEX |
November 12-16, 2001 Las Vegas, NV http://www.linuxbusinessexpo.com |
|
|
|
| 15th Systems Administration Conference/LISA 2001 |
December 2-7, 2001 San Diego, CA http://www.usenix.org/events/lisa2001 |
|
|
|
Linux Journal CompetitionCome up with cover ideas for fun and prizes! The LJ crew's brains are growing fatigued after six years of coming up with ideas to put on the cover of Linux Journal, so they'd like to expand the thinking pool by soliciting cover ideas from LJ readers. They need cover ideas for the following issues and editorial foci:
Linux4ChemistryNikodem Kuznik, the creator of the site, says that the goal of this web-site is to provide the most up-to-date links to chemical software running on Linux. As the field is still under an intensive development, the web-site will also be continuously under construction and you may even find some not-up-to-date URLs there for this same reason. In that case the author will be very glad of your feedback. Nikodem says that you are very welcome to send your comments, new URLs and so on.
International Support for Linux Job SiteMojolin has added international support to its full featured online Job/Resume database. Job listings and resumes can now be entered with full location specifics. This new ability is complemented by a feature that allows an individual to search by countries, and by states and provinces in the United States and Canada. In addition, links have been provided to BabelFish for translation of the site into five different languages: German, French, Italian, Spanish and Portuguese. Other features include a nightly email agent which informs job seekers of the latest opportunities, and the ability for Webmasters to include Mojolin's job listings on their own sites.
LinuxIT acquires 01linux SolutionsLinuxIT, a European Linux Solution Provider, has announced that it has signed an agreement to acquire the business interests of 01Linux Solutions Ltd, a UK-based Linux Support and Consulting company.
LinuxIT has a Linux portal that includes directories for software, hardware, documentation, job postings and user forums, offering services for Linux users and professionals.
This acquisition strengthens LinuxIT's position as one of the leading Vendor-neutral solution providers in Europe. 01Linux has marketed itself extensively as a solutions and services provider and has acquired a reputation for quality offerings based around excellent technical expertise.
Peter Dawes, Managing Director of LinuxIT commented, "The integration of 01Linux into LinuxIT will further add to our Support and Professional Services offerings. We are now offering Total Linux support for all types of customers ranging from one server through to corporates with hundreds of mission critical systems. Combined with our bespoke development, porting of applications to Linux and our educational offerings, this means that LinuxIT is in a unique position to service the growing demand for Linux and Open Source know-how."
Books, Books, and More BooksWriting GNOME Applications
by John R. Sheets
ISBN: 0-201-65791-0
Writing GNOME Applications will help Linux programmers learn the basics of GNOME and understand how to write real-world applications using this important programming environment. Focusing on the essentials, this book guides you through GNOME's fundamental elements and explains how and why these elements function as they do. Rather than serving as an exhaustive reference, the book offers detailed discussion on the most important function calls, demonstrating how to put them to work in application development. This book should appear soon under the OpenBook licence. Keep an eye on the OpenBooks website for updates on this and other titles.
PostgreSQL: Introduction and Concepts
by Bruce Momjian
ISBN: 0-201-70331-9
PostgreSQL: Introduction and Concepts, written by a founding member of the PostgreSQL Global Development Team, provides a much-needed tutorial and real-world guide to understanding and working with this complex yet essential system. The book is also available on-line from the PostgreSQL website, at this location.
Manning Books have brought a new title: Data Munging with Perl to our attention. They say: "The transformation of data from one format to another, colloquially 'munging', is one of the most common programming tasks. The new Manning book, Data Munging with Perl, examines this important process in detail and shows how well suited Perl is for these tasks. The book is aimed at programmers using any programming language who carry out data munging as part of their daily routine. Programmers who are more experienced in Perl may learn a number of new Perl techniques to make their jobs easier."
For a closer look at Data Munging with Perl, Manning offers components of the book online: the table of contents, two sample chapters, the index and source code can be viewed at www.manning.com/cross/. As an added perk, the publisher runs an Author Online discussion forum for discussions between readers and the author, Dave Cross.
The book can be bought now, in PDF format at a discount to the paper version which will soon be for sale. Printed Edition - Softbound, 304 pages, $36.95 Ebook Edition - PDF format, 2 MB, $13.50
Programming KDE 2.0
By Lotzi B�l�ni
ISBN: 1-929629-13-3, Price: US$39.95 Trade Paper with CD-ROM, 265 pp.
CMP say that this book aims to explain all aspects of developing applications to run on the K Desktop Environment (KDE). It describes KDE development from the ground up, starting with fundamentals of event-driven programming and object/component-oriented systems. It progresses through design and management of GUI widgets and dialogs, and ends with the details of font and text controls and picture display. The author shows how to use the Applications Programming Interface (API), manage multitasking applications and build embedded applications using object/component models and the new Kannosa shared library techniques.
ZF Linux DevicesZF Linux Devices has just created what they like to call the "littlest PC", the MachZ. The MachZ fits on an inch square chip, yet is a complete computer, loaded with Linux. More than 60 companies are designing products around the Mach Z, from medical devices and farm equipment to home appliances and vending machines.
Applications for the MachZ PC-on-a-chip include:
Linux LinksWith recent comments on this web-page on the subject of security, it would probably be worthwhile for anyone whose interest has been piqued to peruse the Linux Security FAQ (as pointed to by /.)
ShowMeLinux's January Issue Now Available with a mix of features, news and support.
The Duke of URL have a couple of items that may be of interest to you:
Finally, Slashdot have an article where you can read how Steve Ballmer says Linux is the top threat to MS.
Linux Server Pages Product for XbaseJanuary 8, 2001 SAN LEANDRO, CA, PlugSys International today announced its new Max Server Pages (MSP) product. This gives Xbase developers a reliable, economical way to migrate to Linux and perform server-side scripting. Using classic Xbase commands and functions, developers can access data stored in DBF files or ODBC databases and blend the results with HTML and Javascript. Max Server Pages development focuses on creation of HTML templates with embedded Xbase control structures, expressions, commands and functions. MSP Professional also allows developers to precompile source code for even faster loading libraries. The final phase of beta test is in progress. Beta testers are encouraged to apply. The company is particularly interested in Xbase developers with some web development experience and access to a web server machine running Red Hat 6.2.
Try Linux Online with RunawareOakland, CA (January 10, 2000) - Runaware, the world's first Evaluation Service Provider for software vendors and consumers, today announced a partnership with SlashTCO, a U.K.-based open source services provider, to promote Linux awareness through online testing and supplementary resources.
Runaware will enable software purchasers to test Linux products through the web browser without downloads or installation. Support materials such as reviews and explanatory articles provided by SlashTCO will enhance the evaluation process.
WordWalla Enters Linux PartnershipFREMONT, Calif. (January 17, 2001) WordWalla, Inc., a leading global language software provider, has joined three key industry organizations to participate in the development and understanding of new, emerging technologies and markets the Embedded Linux Consortium, LISA and the Unicode Consortium
As members of these three leading organizations, WordWalla will help contribute to the latest developments in Linux applications and Unicode standards as it relates to the use and proliferation of new font technologies, and will support and evangelize globalization initiatives.
VMware Release GSX ServerPALO ALTO, Calif., January 23, 2001 - VMware, Inc. today announced that it has concluded its GSX Server beta program with more than 300 companies worldwide participating. The company also announced that the product is available for sale today at www.vmware.com
Based on VMware's patent pending MultipleWorlds technology, GSX Server gives information technology (IT) organizations mainframe-class control on Intel based servers. The software helps IT professionals leverage resources in responding to the growing demand for new applications and services by cutting down on the number of servers required, taking the pain out of staging and testing server applications and automating server installation and management.
VMware GSX Server for Linux systems is priced at $2,499 for a single license purchase and is available today via electronic distribution directly from VMware. Premium support at the Silver, Gold and Platinum levels is available on a per incident basis or via subscription. Packaged versions of GSX Server will be available from VMware and from selected resellers and distributors within imminently.
Internet Cafe Management Software OTG Announces DiskXtender for Linux and Support for Red HatBETHESDA, MD, January 3, 2001 - OTG Software, a software developer of online storage, data access and email management solutions, today announced DiskXtender for Linux, new storage software that supports the Red Hat Linux platform. This new product aims to enable true heterogeneous and centralized storage management. OTG is now further extending its expertise in Windows 2000/NT storage systems to Linux, building on its recent announcement of DiskXtender for UNIX.
 The Answer Gang
The Answer Gang 
 Greetings from Heather Stern
Greetings from Heather SternThis month I improved my little scripts so that it does about half the work (the part that becomes the mailbag and Tips) much more efficiently. I even managed to get things back to a level where I can split the messages back out as seperate files again.
Outside of this stuff, one thing on my mind is, how well supported will those new slim Apple notebooks be under Linux for the PPC platform? I hear they finally have a decent battery life, plus, they've got a really nice tough shell. I need that. I'm pretty hard on my stuff. Just ask my Magio.
Oh yeah. Can't do that, I haven't finished making it use Speak Freely yet. Sigh. I'm sure it's not supposed to be very hard, but there's no decent checklist out there. So, it can't talk to you quite yet!
Earlier this week, Mike asked if I could have my script format the Gazette Matters section, since I was doing 2 of the 3 other parts, and he's got an armful of articles. We've both had to defer some of the items until next issue ... Next month is going to be pretty tasty! Meanwhile we hope you enjoy what we've got in here for you.
So, since I didn't have time for a cool editorial (and I missed LWE) here's the backside scoop on how we select where messages end up:
Here it is.
There's one letter where the guy gives a long explanation about his install. I'm not sure if it belongs in the Mailbag or Tips.
[got your attachment on this one]
If he's telling the rest of us his successful answer, but it's really long (eg more than 2 lynx pages) I put in in TAG with a bangbubble. That's what happened to our SuSE/NFS fellow.
If shorter ans esp. if he has some good insightful item that's enough to absorb there, it goes in Tips. Oh yeah, I don't count script length too much against people.
If he has a gnarly question I think the Gang would have trouble with too, it goes in Wanted. "I'd like to see an article on..." also go in wanted, inclu. if that's my own thought sponsored by some question that came through. This is a massively reduced subset of the unanswered souls - I just like to give the readership a flavor of some of the stuff we have overflowing.
If it's a kudo thanking us 'cuz some past issue helped him nail it, it goes in mailbag... possibly edited, but not usually. (mild kudos with lots of tip or answer go in tips or tag respectively.)
Otherwise it goes back in the float, and maybe Jim and I will give a shot at answering it, or maybe he loses the TAG lotto. We don't promise to answer everything. Once in a long while Jim gets bitten by the answer bug and decides to clean out a bunch of backlog, but I don't see that happening for at least a couple of months at least.
To be perfectly honest, Jim's better at keeping the lost ones together, and I'm better at keeping track of which month they came in, but that's a natural side effect of the way we each work on the messages ![]()
I don't know how Ben and the rest keep track of what they like to answer, but as long as it all flows by my desk, everything works great.
[ and if I don't have enough time for it, that's gonna be The Blurb. :D ]
... and of course, Dear Reader, you know that that's exactly what happened. That fellow's message is long, but he just decided that he couldn't give us enough kudos if we didn't see the voyage of discovery he travelled with LG. So it stayed right where it is, and this is The Blurb.
Not Linux of the month for me:
On our local radio show two mornings ago, the PG&E building is right across the street from the station, and the hosts notice that it's "lit like a christmas tree" - every floor, completely on. Except the lobby area, where people would normally come in to pay bills. So... PG&E in California can't pay their bills to buy us enough power, but they haven't ordered their cleaning crew to change its habits about leaving all the lights on in their buildings.
But Jim says Walgreens is a lot easier on the eyes now that they only use a third of the lighting. Just remember -- computers don't eat much!
Enjoy.
Renaming Ethernet DevicesFrom Matthew Keller
Answered By Mike Orr, Heather Stern
Ok, so this is probably a trivial problem, but it's one I've had for years. If I have 3 Ethernet devices (eth0,eth1,eth2), I want to be able to tell Linux WHICH one I want to be which. If they are of different kinds (or at least have different drivers) I can fool Linux by specifying them in /etc/conf.modules (or modules.conf for RH7 users) and defining which card gets which name. How do I do that if they're all the same kind?!
[Mike] I've tried to do that before too, but I haven't found a way. It seems like a glaring ommission. I just use different brands of cards, and then I can decide which order to insmod the modules. Obviously, each card is attached to a different network, and it's important to know card X is eth0 so you can configure the right card for the right network.
The worst part is, if the first card is removed or fizzles out, the second card becomes eth0, and your startup script will initialize the wrong card, and presto, no network.
You may find they get detected in order of hardware address. PCI slots have fixed addresses, so you may be able to move the cards among different slots and get the order you want.
(If they were ISA cards like the 3C509, you would the DOS program 3C5X9.EXE to set the hardware address on each card. Other ISA cards you would set jumpers on, if you're lucky enough to find documentation about which setting is which! Dunno about plug n play, but on the 3C509 you can turn off plug n play using the same program. You could also use LILO's "ether=" parameter to specify which order you want the hardware addresses probed.)
![]() What brings this to mind now, is that I have a new server, fresh install, one on-motherboard Intel NIC and 2 PCI NIC's. Linux picked the first PCI NIC to be Eth0, the second to be Eth1 and the on-board to be Eth2, and I'm just demented enough to argue with it.
What brings this to mind now, is that I have a new server, fresh install, one on-motherboard Intel NIC and 2 PCI NIC's. Linux picked the first PCI NIC to be Eth0, the second to be Eth1 and the on-board to be Eth2, and I'm just demented enough to argue with it. ![]()
Matthew Keller
In many cases it is highly preferred that insmod:ing is done
ONLY with defining an explicit address for the card, AND BY
NOT USING AUTO-PROBING!
...
8390 based Network Modules (Paul Gortmaker, Nov 12, 1995)
--------------------------
(Includes: smc-ultra, ne, wd, 3c503, hp, hp-plus, e2100 and ac3200)
The 8390 series of network drivers now support multiple card systems without
reloading the same module multiple times (memory efficient!) This is done by
specifying multiple comma separated values, such as:
insmod 3c503.o io=0x280,0x300,0x330,0x350 xcvr=0,1,0,1
The above would have the one module controlling four 3c503 cards, with card 2
and 4 using external transceivers. The "insmod" manual describes the usage
of comma separated value lists.
It is *STRONGLY RECOMMENDED* that you supply "io=" instead of autoprobing.
If an "io=" argument is not supplied, then the ISA drivers will complain
about autoprobing being not recommended, and begrudgingly autoprobe for
a *SINGLE CARD ONLY* -- if you want to use multiple cards you *have* to
supply an "io=0xNNN,0xQQQ,..." argument.
Therefore, I'm not certain, but it would be worth the experiment: io=0xXXX,0xYYY and irq=X,Y parameters (where these X's and Y's represent the values for each card respectively) should allow you to make it honor two cards explicitly rather than autoprobing them. If you succeed at that, try swapping card "X" and card "Y" in the settings and see if they switch places in the ethN ring. And in any case you should be able to get the right values for these from your logs, because you said you have the system detecting all 3 cards.
If they were really ISA cards with plug-n-play and/or jumpers, the isapnptools would be the next place I'd look.
I took the lazy route; I have a tulip and a 3com card in my dual ethernet system. With it that way, I can even tell the system to not even automatically bring these interfaces up, and explicitly bind the given drivers into the pre-up and post-down, at least on debian. In SuSE I have it mentioned in modules.conf:
alias eth0 3c59x alias eth1 tulip
Mandrake has what's needed...From Antony, in issue 61 (TAG q.#12)
Answer By Mitchell Bruntel
Hi, I recently attempted to install Linux Mandrake, but I did it wrong and know Windows has been deleted and linux won't work, all I want to do is Delete linux so I can reinstall Windows and be happy again, I cant even install windows at the moment because linux is taking up too much room on the hard drive. Mum is heaps annoyed as she can't use the computer so can you please help me quickly? Thanks
[Mike] Hmm, three questions about uninstalling Linux in two days. I wonder what that means.
Doesn't the Windows setup program allow you to repartition your disk as part of the process? If not, that's a big omission.
Anybody here use Mandrake? Does it come with a boot floppy that can be used as a rescue disk? If so, you should be able to boot from the floppy, press Alt-F2 to go to the second virtual console, run "cfdisk" or "fdisk" and delete the Linux partitions (or all the partitions), and then reboot and run the Windows install program.
3 emails, 2 answers, not too bad I guess...
When Linux installs were harder, anyone who was knowledgeable enough to get Linux installed could also install Microsoft Windows over it and blow it away (including fdisk if necessary)Now that Linux installs are really easy, you don't need to know anything about MBRs and partitions to get Linux going on your machine. But you do need to know something about PCs at the sub-OS level to get other OSs installed.(I'm just waiting for somebody to write a Linux installer as a macro virus...Linux fora will be swamped with angry users of other, insecure OSs and we'll all have to take off to Costa Rica for a year or so.)Any technology distinguishable from magic is insufficiently advanced.
Mitch Bruntel
(16 yrs of desktop and UNIX experience...later)
about Unix command rmFrom Jane Liu
Answered By Mike Orr, Ben Okopnik, Dan Wilder
![]() I have a question about rm command. Would you please tell me how to remove all the files excepts certain files like anything ended with .c?
I have a question about rm command. Would you please tell me how to remove all the files excepts certain files like anything ended with .c?
mkdir /tmp/tdir
mv *.c /tmp/tdir
rm *
mv /tmp/tdir/* .
rmdir /tmp/tdir
My preference would be to use something like
rm $(ls -1|grep -v "\.c$")
because the argument given to "grep" can be a regular expression. Given that, you can say things like "delete all files except those that end in 'htm' or 'html'", "delete all except '*.c', '*.h', and '*.asm'", as well as a broad range of other things. If you want to eliminate the error messages given by the directories (rm can't delete them without other switches), as well as making "rm" ask you for confirmation on each file, you could use a "fancier" version -
rm -i $(ls -AF1|grep -v "/$"|grep -v "\.c$")
Note that in the second argument - the only one that should be changed - the "\" in front of the ".c" is essential: it makes the "." a literal period rather than a single-character match. As an example, lets try the above with different options.
In a directory that contains
testc
test-c
testcx
test.cdx
test.c
".c" means "'c' preceded by any character" - NO files would be deleted.
"\.c" means "'c' preceded by a period" - deletes the first 3 files.
"\.c$" means "'c' preceded by a period and followed by the end of the line" - all the files except the last one would be gone.
Here's a script that would do it all in one shot, including showing a list of files to be deleted:
See attached misc/tag/rmx.bash.txt
For a less interactive script which can remove inordinate numbers of files, something containing:
ls -AF1 | grep -v /$ | grep -v $1 | xargs rm
allows "xargs" to collect as many files as it can on a command line, and invoke "rm" repeatedly.
It would be prudent to try the thing out in a directory containing only expendable files with names similar to the intended victims/saved.
I just put in that "to be deleted" display for, umm, practice. Yeah.
<LOL> Good point, Dan.
![]() Thanks a million! It worked.
Thanks a million! It worked.
I have another question: My shell script is in a file called hw1d.sh. When I run sh hw1d.sh, the output shows on the screen. But the command details won't show. Is there a way I can capture the detailed command lines and output at the same time?
#!/bin/bash -v
This will print out each line as it is read.
#!/bin/bash -v
TOWHOM="world"
echo "Hello"
echo $TOWHOM
# This is a comment.
Now running it:
$ ./hello.sh
#!/bin/bash -v
TOWHOM="world"
echo "Hello"
Hello
echo $TOWHOM
world
# This is a comment.
Now change -v to -x and run it.
$ ./hello.sh + TOWHOM=world + echo Hello Hello + echo world world
The variable was expanded, there's a "+ " before each program line, and the comments are omitted. It looks like -v shows the commands before they're interpreted and -x shows them after.
He got the issue numbers wrong, but no sense worrying about that, here they are. -- Heather
![]() Thanks!
Thanks!
For practice purpose, I create file -cfile and try to rename it to cfile. I figured out one way:
>cat <\-cfile >cfile
But I just couldn't delete the old file -cfile because shell always interprets as option. Is there a way I can do this?
rm -- -cfile
From "man rm":
GNU STANDARD OPTIONS [ ... ] -- Terminate option list.
rm ./-cfile
also works. As you have found out, it's not a good idea to create filenames with non-alphanumeric characters at the beginning: just because you can, really does not mean that you should...
/usr/src/linux symlink considered harmfulWhile it's normally the practice here to state who's asking and who's answering, on this issue, that itself was a hot topic.
While answering "A rather unique query" last month, Mike dispensed some common wisdom... which has, it seems, become unwise, at least unless you are exceedingly careful of the context.
Thanks to Michal Jaegermann from the kernel list for bringing it to more serious attention (can we say flame war here in the land of curmudgeons? knew ya could), everyone from the Gang who hopped in, and, especially, Breen Mullins and Dan Wilder for providing clearer detail into the nature of the problem. And my apologies to anyone who feels a need to get grumpy that I ruined all concept of timeline in this thread, in favor of clarity to the readers.
Distro vendors and anyone who tends to build themselves kernels of different vintages (mixing 2.0 with 2.2, etc) should pay special attention.
![]() [Mike] This is the normal Linux convention. Actually, you can place your build tree anywhere, but you should make /usr/src/linux a symlink to it so that the compiler will find the include files.
[Mike] This is the normal Linux convention. Actually, you can place your build tree anywhere, but you should make /usr/src/linux a symlink to it so that the compiler will find the include files.
I'll spare the readership the flame war on his flight into hyperbole. -- Heather
![]() [Mike] (Is this [headers in /usr/src/linux/include/] still required now that glibc has its own kernel headers?)
[Mike] (Is this [headers in /usr/src/linux/include/] still required now that glibc has its own kernel headers?)
Good question... building a kernel vs. building other things, this link does or doesn't exist or is real instead of a link; some other link named "build" in the modules subtree does or doesn't exist, and if it does, what's a good link look like? [hot topic compression algorithm, kinda lossy but hopefully sufficient.]
![]() [Mike] OK tag, what do you think? Is it time to stop linking /usr/src/linux to /usr/src/linux-VERSION ?
[Mike] OK tag, what do you think? Is it time to stop linking /usr/src/linux to /usr/src/linux-VERSION ?
From the 2.4.0 release, in linux/README:
INSTALLING the kernel: - If you install the full sources, put the kernel tarball in a directory where you have permissions (eg. your home directory) and unpack it: gzip -cd linux-2.4.XX.tar.gz | tar xvf - Replace "XX" with the version number of the latest kernel. Do NOT use the /usr/src/linux area! This area has a (usually incomplete) set of kernel headers that are used by the library header files. They should match the library, and not get messed up by whatever the kernel-du-jour happens to be.
Many userland programs need (or think they need) kernel includes. They usually get these through /usr/include/asm and /usr/include/linux, which are often themselves symlinks:
/usr/include/asm -> /usr/src/linux/include/asm /usr/include/linux -> /usr/src/linux/include/linux
Perhaps this is wrong, and either
In the one case, the application developers are at fault, and should be told to mend their ways. In the other, blame the distributions.
Some source packages indeed search for /usr/src/linux for configuration purposes. If this is not just a default which could, and should, be adjusted then they are simply wrong. Current 2.2 kernels will install 'build' link in its /lib/modules subdirectory to indicate where sources for a given version are/were. This is not a foolproof either but still better than alternatives.
Recent application source trees exhibiting things like
#include <linux/...
include (just for starters) autofs, cdrecord, DOSEMU, gnupg, kde, mysql, ntp, pgp, procps, python, samba, util-linux, wu-ftpd.
Perhaps we need a userland API? oh yeah, right, got that, called glibc. Sigh. I think we can grant that procps has to know what /proc is really up to, though.
![]() [Mike] None of my systems have ever had a /usr/src/linux directory at all. (Otherwise, I would not have been able to make the symlink without erasing stuff first.)
[Mike] None of my systems have ever had a /usr/src/linux directory at all. (Otherwise, I would not have been able to make the symlink without erasing stuff first.)
So the thread at the end of this month still carries some questions:
At the very least, folks, while you're building new kernels out there, here's a few safety tips:
depmod -a -F /path/to/correct/System.mapIf anyone has some good checklist points to look out for when compiling userland apps, or a clearer description of what's going on in glibc's tiny brain when it reaches for "headers", let us know!
The Creed of The QuerentA few of the Answer Gang this month have a special interest in seeing the quality of the incoming questions improve. In good humor, here's some ways to bump up your chances in the "Answer Gang might notice my message and answer me" lotto.
From Querents Everywhere
Answered By Ben Okopnik, Heather Stern
From comp.unix.security's newest reader
Answered By Jim Dennis
[Ben] And Now, Cometh The Rant. Not to worry - it's not directed at anybody; this is just a personal peeve that addresses a common problem, here, in various places on Usenet, in tech support, etc. It also seems to be prevalent in the Linux community at large, and that's a trend I'd like to reverse, or at least contribute to slowing down.
Note that I speak only for myself - neither LG nor the rest of the Answer Gang have contributed their opinions to this (though they'd be more than welcome.)
Being part of the Answer Gang, as well as the Alpha Geek and Supreme Guru in other venues, I get questions about Linux, Life, and the Universe almost daily. Usually, the questions fall into one of two categories:
"Hi, I want to know about [Linux, brain surgery, love, astrophysics]."
"Hi. I have a Pentium 266/64MB/6.4GB running Debian Linux 2.2. I've just installed Mutt (version 1.0.1i) with PGP support built in - I double-checked by running "mutt -v", and it does. I'm getting a message - here, I wrote it down - it says "pgp: ^GRequires a later version", and I can't read the PGP-encoded e-mail that was sent to me. I've checked the PGP site at MIT and I do indeed have the latest version, 2.6.3a-7. Could you help me?"
My response to the first type, if indeed I do make one, is "Go away." My response to the second one is "Marry me!!!" (this has required building a much larger house, but never mind. There are very few of the second kind, anyway.)
The presumption in the first type is extremely annoying. It has driven a number of people, some of them True Gurus of their respective crafts, off Usenet and into virtual e-mail seclusion. There are many, many people out there who think nothing of asking a person they don't know to put in hours of work - it's one of the unfortunate side effects of easy communication provided by Net access. I would suggest that these folks walk into a lawyer's office and demand free help. (I would actually enjoy being a fly on the wall at that conference, short and loud as it may be.) There are indeed a number of us willing to provide free help - but in general, leeches and time moochers aren't welcome. Making sure you aren't one isn't that difficult - it simply takes consideration and common sense.
So, rather than ranting on about the manifold evils of this, let me contribute something substantial here: to wit, a checklist. This applies to TAG questions - and hopefully, to other issues. May it lead to greater consideration for others, a more harmonious life on the Net, and eternal World Peace. Or at least fewer wives and a smaller house.
[x] I have tried my best to resolve this problem with the knowledge and tools that I have at hand.
[x] I have tried my best to extend my understanding of the problem by studying the list of of Linux HOWTOs, searching the Net for relevant keywords, and scanning past issues of LG.
[x] I have performed the above two steps at least twice, in that order.
[x] Now that I can proceed no further, despite all my study and effort, I have done my utmost to put my question into a clear, understandable form. This also means that I have given all applicable information, have been specific about version/type/machine specifics, etc.
[x] I have also considered ways in which other people may misunderstand my question, and have rephrased it to avoid those misunderstandings. I have also used a spellchecker, lest my meaning be unclear in that manner.
[x] I have used the sacred 40 characters of "Subject" wisely, not wasting them on garbage like "NEWBIE NEEDS HELP!!!!" but thoughtfully choosing a good introduction, like "gcc dies with sig11 on kernel compilation".
[x] Only now have I hit the 'send' key. If someone expends their valuable time and effort to help me, I shall show my gratitude, if and when I am able, by helping others as I have been helped.
Selah.
There. Saving the world in seven easy steps. What more can you ask for?
A fair percentage of the Linux world reads our stuff. Every month. You really don't want to know how many questions we get. Our Senior Editor has mentioned that about 28% of the stuff we get is spam.
This is after you consider our procmail defenses; some of the lint trap contents *aren't* spam, it's questions for the Gang, and our sysadmin eventually forwards those to us. (Poor guy. Dan not only reads TAG and answers stuff, he keeps our lists running, our web servers humming, and has to read through all our spam in case it might be a real question. Sigh.)
Of the stuff that isn't "real" spam, I'd say well over 10% is questions which are not about Linux at all. Sometimes not even about computers! (I've stopped publishing any offtopic stuff unless more than one of us thinks it ought to go in.) The remainder is still huge.
So, we can't promise to answer every single question -- and we can't anyway. So while I have to hand it to this guy for his perseverence in the face of silence... we still can't promise to answer every single question!
But I will add for the benefit of those who send us the tricky ones and hope that we'll help them out, that the following features in his mail seriously delayed this fellow's answer:
He used almost no paragraph structure. Even if he'd gotten the paragraphs a little wrong, it would have made the question easier to read.
During formatting of this month's mail I have noticed a nasty trend, some webmail accounts but almost every Outlook Express mail has come in as "quoted printable". Now this is a mail encoding that is supposed to exist to protect special text ... say, something written in spanish ... from being mangled by the mail routers or cheap mail clients while being bounced around. (Hi Felipe!) However, when neither the original mail nor the HTML version has such weird characters, it only serves to annoy the heck out of my scripts.
I have to give credit to a lot of our querents this month who didn't get answers - for many it's not because you've failed at Ben's suggestions, but we of the Gang either didn't feel adept at tackling your question this time around, or we were all busy helping others.
So add to your checklist...
[x] If my message is long and rambly I will insert blank lines when I am changing thoughts. If it's hard for you, you can try a blank line between each of these:
- what type of system and linux I have
- what I'm trying to do
- how it's screwed me up so far
- things I tried to look up so I could fix it
- guesses at what next, and thanks for any clues.
[x] I have turned off the HTML attachment since it sends 3 or 4 times as many bits, and doesn't help when it gets there. I am sending plain ASCII text. (I'm not, however, afraid of using smileys and unhappy faces to express cheer and frustration.)
[x] If I am writing in a foreign language I will use quoted printable to defend my homeland's letterset from being mangled, and if I know any English at all I will tranlate it myself rather than wait a month or so extra for the translators to get to my mail.
In this message he responds to a clueless message in the comp.unix.security newsgroup. Despite his early sarcasm, he later provides a wealth of advice to newbie Solaris sysadmins and show, once again that "It's all just UNIX."
Newsgroups: comp.security.unix Subject: Re: Help References: <[email protected]> Followup-To:
In article <[email protected]>, May Hu wrote:
![]() I'm new to Solaris, can some experts help me with security matters in the Solaris Platform on SUN SPARC.
I'm new to Solaris, can some experts help me with security matters in the Solaris Platform on SUN SPARC.
![]() What are the paths to pay attention to?
What are the paths to pay attention to?
![]() What are the logs or system logs do I require to checked or backup?
What are the logs or system logs do I require to checked or backup?
![]() What are the things to pay more attention to in the Solaris platform?
What are the things to pay more attention to in the Solaris platform?
![]() What are the things to backup for system recovery, if there's any?
What are the things to backup for system recovery, if there's any?
![]() Hope to get some replies from any of you out there who are familiar with the platform.
Hope to get some replies from any of you out there who are familiar with the platform.
![]() Thanks May
Thanks May
So, let's try this:
Go get Unix System Administrator's Handbook by Evi Nemeth et al. (3rd Edition, Prentice Hall) --- that's commonly called the "Grape Book" because the cover is purple. The first two editions were widely referred as "the cranberry book" because the first had a cartoon with a reference to a cranberry patch on it and the second had a modified version of that cartoon (no patch) but was a dark red color that is reminiscent of cranberry juice.
Read it! USAH is not Solaris specific, but it should give you a good overview of UNIX systems administration.
While you're at the book store, get a copy of Essential System Administration (Aeleen Frisch, O'Reilly & Associates, 2nd Ed). This is often called "The Armadillo Book" because, in the O'Reilly tradition, it has a woodcut styled picture of an armadillo on the cover.
Read it! It is also not Solaris specific. See the penultimate (next to last) paragraph.
If I haven't irritated you enough, pick up a copy of my book, Linux System Administration (M Carling, Stephen Degler, and Jim Dennis (me)). It's also not about Solaris, but most of what it says is applicable to all UNIX platforms. My book doesn't duplicate much of what you'd find in Nemeth or Frisch. I wrote it in a context of having read those (and many others) and specifically avoided covering the topics that were adequately covered in the more basic books.
After you have a thorough grounding in systems administration, then you can learn a bit more specifically about UNIX security and then you can focus on Solaris security. If you find a shortcut that's really effective, let us know. However, you should expect to read about a half dozen fairly large books from cover to cover. There will be a test (every day on the job is a bit of a test in our field).
There is an interesting online UNIX SysAdmins Independent Learning (USAIL) project at Indiana University:
http://www.uwsg.iu.edu/usail
It seems to be a reasonable place to learn a bit of our craft. There are chapters that relate to each of your questions, and there are self-quizzes you can take using any web browser (even Lynx; which is still my favorite; all of URLs in this posting were checked in Lynx as I was writing it --- most were yanked in from my Lynx bookmarks file).
On the topic of security I'd recommend three titles to start with: Practical UNIX and Internet Security by Simson Garfinkel, and Gene Spafford (O'Reilly, 2nd Ed.), Building Internet Firewalls by Brent Chapman, Elizabeth Zwicky, and Simon Cooper (O'Reilly, 2nd Ed.) and Firewalls and Internet Security: Foiling The Wily Hacker by Steven Bellovin and William Cheswick (Addison Wesley?). I've heard a rumor that a second edition of the latter title is going to be released soon. (I've been holding out on buying a new copy; mine walked off a few years ago).
(BTW: you might have noticed that most of the books on my list are in second editions or later. I expect that my own book would also benefit from further revision --- but only time will tell if the publishers have the interest).
Read all of those. Then get a few books that are more specific to Solaris. I've read through both of Janic Windsor's books (Solaris System Administrator's Guide and Solaris Advanced System Administrator's Guide) but I mostly don't use Solaris any more. The few Solaris and SunOS boxes I ever professionally administered are fading memories.
You can find more recommended books on the topics of systems administration at:
- SAGE - General reference books for Sysadmins
- http://www.usenix.org/sage/sysadmins/books/general.html
SAGE is the SysAdmin's Guild (the "e" is silent, we stole it from /etc/resolv.conf's filename!)
Once you have a reasonable educational foundation you can make better use of online resources (like this newsgroup). Of course you should start by reading the FAQs (Frequently Asked/Answered Questions) that relate to any topic about which you are tempted to ask a question. There's a very nice collection of FAQs at the obvious URL: http://www.faqs.org (Note: www.faq.org, no "s", is some sort of lame "portal" site that makes no effort to make FAQs available, ARGH!).
Here's a few appropriate FAQs and links for you:
For this newsgroup:
- comp.security.unix and comp.security.misc FAQ
- http://www.faqs.org/faqs/computer-security/most-common-qs
On Solaris:
- Solaris 2 Frequently Asked Questions (FAQ) 1.70
- http://www.faqs.org/faqs/Solaris2/FAQ
... this one is maintained by Casper Dik, who has been quite active on netnews, particularly in comp.unix.admin, for longer than I have.
On various security topics:
- Computer Security Index
- http://www.faqs.org/faqs/computer-security
So, with all of that advice let's review your questions:
![]() What are the paths to pay attention to?
What are the paths to pay attention to?
Since you are asking this in the context of comp.unix.security I can guess that you're really intended to ask something more like:
How would I know if an attacker has compromised my
system? What files are likely to be modified by a cracker?
This suggests that you'd like to install file integrity test system or an intrusion detection system (IDS). You could get a copy of Tripwire (by Gene Kim and Gene Spafford) which started as a free tool and is now maintained as a commercial product by Gene Kim's company at: http://www.tripwiresecurity.com) You could also look at AIDE (which is basically a freeware clone of Tripwire). AIDE (http://www.cs.tut.fi/~rammer/aide.html). is more popular among Linux, and *BSD users, but it will run on Solaris and should run on any other modern UNIX.
![]() What are the logs or system logs do I require to checked or backup?
What are the logs or system logs do I require to checked or backup?
On most forms of UNIX you could even modify your /etc/syslog.conf to force it to copy certain types of messages to another system on your network or to a printer, through a serial line to a terminal or to another system. These sorts of customizations can provide you with a tamper resistant copy of your messages.
Setting up remote loghosts is considered to be a useful security measure. If the loghost is sufficiently hardened and dedicated it can consolidate copies of your logs and prevent the (otherwise successful) attacker from "covering his or her tracks" by editing the evidence out of the logs.
You can also create cron jobs that periodically scan your logs looking for anomalous entries, filtering out all the innocuous messages and mailing, printing or otherwise delivering the summaries to you.
In my book I give a very simple (10 line) awk script that loads a file full of patterns (regular expressions) and filters a file of all of them. It is an extremely simple anomaly detection engine. The hard part of using it is creating a list of patterns to meet your needs. Maintaining the pattern files for each of your logs is made more challenging by the fact that upgrades to your OS and other software can affect the messages that they generate.
On many UNIX systems you can look for a "logger" command (/usr/bin/logger, or /bin/logger) so that your shell scripts can easily post their own syslog messages. There are also modules and extensions to PERL, and Python (and probably others) that let you natively post messages to the system logs from scripts in those languages.
There are also replacements to the stock UNIX syslog system. So you could rip out the Solaris syslog daemon and install syslog-NG or some other package. That might offer better reliability (using TCP rather than UDP) security that conforms more closely to your needs (using encrypted tunnels for example) or more flexibility (letting you dispatch and filter based on regular expression rather than simple facility/level codes).
Obviously none of that last paragraph will make any sense until you understand how the conventional UNIX syslog system works. Go read those books and a few of the man pages on your system!
![]() What are the things to pay more attention to in the Solaris platform?
What are the things to pay more attention to in the Solaris platform?
What parts of Solaris really suck?
My answer is: "I don't know. Read the FAQ." I'm an expert on Linux, and I can tell you the parts of it that can be problematic for UNIX and Solaris users as they adopt it. (For example, if you were among the few people who actually use ACLs --- access control lists --- under Solaris or some other OS than you might find that Linux' lack of them in their standard kernels and distributions "really sucks." You might also hold that having to fetch and apply an unofficial kernel patch, rebuild your kernel, and install an extra set of utilities also "really sucks").
Again, the FAQ (and some strategic lurking in this newsgroup and on some of the mailing lists that are recommended in the FAQs) will answer that question.
![]() What are the things to backup for system recovery, if there's any?
What are the things to backup for system recovery, if there's any?
Recovery planning is one of the most important jobs of a system administrator. Doing backups is a part of a recovery plan, but it's ONLY A PART.
As I've mentioned in this post, I'm not a Solaris expert. I could write a 30 page HOWTO on doing Linux backups (in fact, I did, sort of; it's the latter half of chapter 3 in my book). Most of it would be the same under Solaris --- you have your choice of tar, cpio and dump (ufsdump under Solaris, I guess).
However, it is often as effective to know how to look for answers than to know the answers themselves. In this case I searched the FAQ (see above) and found that Casper had failed me. Apparently it's not frequently asked enough on the Solaris/SunOS newsgroups. There is a passing reference to the Solstice Backup documentation on the "AnswerBook" CDs that ship with Solaris. Perhaps that would be handy.
Next I went to Google. Google (http://www.google.com) is currently the best search engine on the 'net. I used the terms: solaris backup.
Here's the best couple of links I found:
- Solaris Backup FAQ/Top Ten
- http://www.ebsinc.com/solaris/backup.html
- Backup Central: Free Backup Software
- http://www.backupcentral.com/toc-free-backup-software.html
... which includes:
- Backup Central: hostdump.sh
- http://www.backupcentral.com/hostdump.html
... a general purpose full system backup script.
Obviously, I'm not a Solaris expert. Luckily Solaris is UNIX and I am pretty good at that. Most generic UNIX knowlege will serve you as well on Solaris, Linux, FreeBSD, etc as it would on a SCO or other system.
Whether the answers I've given to your specific questions make any sense depends on your background. If my references to tripwire, ufsdump, syslog facilities and levels, FAQs, man pages were confusing then you don't yet have the background to be a professional sysadmin. Go through USAIL, read the books I've suggested. If those are too advanced and confusing then try more basic ones like Mark G. Sobell's Practical Guide to Solaris (http://www.sobell.com) or Unix for the Impatient by Paul Abrahams and Bruce Larson. (Actually if USAIL is too advanced, then give up and start flipping burgers somewhere!).
Meanwhile, for your immediate needs you may want to hire a consultant to audit your current production systems, do AND TEST a full set of backups and to disable any unnecessary networking services and generally configure you system until you've learned enough to manage it yourself.
Unfortunately finding a good consultant is difficult. There are alot of snake oil salesmen and any decent huckster can wow you with technobabble that's indistinguishable from good advice. To the untrained ear; they sound the same. I can't help you much there. (I'm not available as a consultant these days, and I wouldn't be the right person for your Solaris boxes anyway. My wife is a UNIX/Linux consultant and she does offer a "phone technical interview" service --- where she can interview your prospective consultant or sysadmin over the phone and give you an evaluation of their UNIX proficiency).
Lastly: If you're going to become a professional Solaris sysadmin you'll want to have a copy on at least one NON-PRODUCTION system. You want to be able to experiment and to break things without disrupting your real business processes. If you're sure that you want to stick with Solaris then it would make sense to participate in Sun's "Free Solaris[tm] Binary License Program" http://www.sun.com/developers/tools/solaris (although their meaning of "free" is a bit loose since their CD will cost you $75 --- and they don't let you modify/sell copies of that!).
Personally I prefer Linux, FreeBSD (and OpenBSD and NetBSD) where "free" means you can download the ISO image and burn it to your own CD, you can buy the CD sets for prices ranging from $2 to about $100, and most of those you could copy and resell if you wanted to, and you get the source code and the right to make changes and redistribute your own custom versions of the software. That's a version of "free" that seems more liberated n'est ce pas?
For hardware you have two choices: get Solaris x86 and install it on a PC; or get a SPARC system. You can get used SPARC systems on eBay or other online auction sites for anywhere from $50 to $200 for old 32-bit SPARC classics, IPXs etc, to $500-2,000 for 64-bit UltraSPARC I and II systems. Caveat emptor!
So, that's the Linux Gazette "Answer Guy's" guide to becoming a Solaris security and system adminstration professional.
IP ForwardingFrom Cole Ragland
Answered By Mike Orr
![]() I have a Slackware machine acting as a gateway/router between two separate networks e.g. 172.29.17.0 and 10.10.3.0. This machine is mulithomed with eth0=172.29.17.19 and eth1=10.10.3.10. Packets from the 10.10 .3 network cannot get passed eth0. I've enable ip forwarding e.g. "echo 1 ip_forward" but I believe that is only for routing between subnets. How can I route between two separate networks. I'm thinking ip_chains, ipmasq, and routed (which I have to fire up manually -- if I uncomment rc.inet2 lines, machine stalls at boot) but not sure. Thanks for your help.
I have a Slackware machine acting as a gateway/router between two separate networks e.g. 172.29.17.0 and 10.10.3.0. This machine is mulithomed with eth0=172.29.17.19 and eth1=10.10.3.10. Packets from the 10.10 .3 network cannot get passed eth0. I've enable ip forwarding e.g. "echo 1 ip_forward" but I believe that is only for routing between subnets. How can I route between two separate networks. I'm thinking ip_chains, ipmasq, and routed (which I have to fire up manually -- if I uncomment rc.inet2 lines, machine stalls at boot) but not sure. Thanks for your help.
If you're using kernel 2.2.x, the minimal commands required in your startup scripts are:
echo "1" > /proc/sys/net/ipv4/ip_forward # Enable forwarding between eth0 and eth1. /sbin/ipchains -P forward DENY # Forbid all other types of forwarding. /sbin/ipchains -A forward -s 10.0.0.0/8 -j MASQ # Forward and masquerade requests from 10.x.x.x and handle replies back
This will handle ordinary TCP services. FTP, ping, irc, CuSeeme, Quake also require additional modules in order to be masqueraded.
You can also build a more elaborate ipchains ruleset to customize security.
- A similar thread is in last month's The Answer Gang.
- http://www.linuxgazette.com/issue61/lg_answer61.html#tag/5
ess1869 sound card modualFrom Robert Campbell
Answered By Ben Okopnik
![]() I am trying to install a ess1869 sound card.� and I have read in allot of place that the card works with linux but I cannot find the modual that looks right for it....� I want to know where I can download the modual for the ess1869 sound card..�� and is there a site that is dedicated to linux moduals and drivers so I can download others from there when needed?
I am trying to install a ess1869 sound card.� and I have read in allot of place that the card works with linux but I cannot find the modual that looks right for it....� I want to know where I can download the modual for the ess1869 sound card..�� and is there a site that is dedicated to linux moduals and drivers so I can download others from there when needed?
When you say that you "cannot find the modual that looks right for it", what do you mean? I'm not aware of any physical characteristics that would make a module "look wrong" - what criteria are you using? In any case, the module that "looks right" to me, in this case, is 'sb', the SoundBlaster module. I would suggest downloading my "shotgun" script that was published in the current issue of LG as "2-cent tip - module resource detection" and running it with 'sb' as a parameter; if one of the listed switches is "esstype", then ESS support is compiled in, and you simply need to load 'sb' (as well as the modules that are necessary to support it.) In case of problems, I would suggest reading the extensive comments in the source code (/usr/src/linux/drivers/sound/sb_ess.c) Hint: search for the word 'esstype'.
![[ Answer Guy Current Index ]](../gx/dennis/answertoc.jpg) |
1 2 3 4 5 6 7 |
![[ Index of Past Answers ]](../gx/dennis/answerpast.jpg) |
 More 2¢ Tips!
More 2¢ Tips! 2c tip: finding out your home router's ip address using lynx
2c tip: finding out your home router's ip address using lynxSome popular home routers like the Linksys BEFSR41 work well with linux but finding out the external address of the router (e.g. to update some dynamic DNS service) can require manual intervention, like using a web browser and pen and paper. The Linksys device can be automatically queried about its external IP address using the text browser, lynx:
lynx -auth=\ :admin http://192.168.1.1/Status.htm -dump
You can then parse the output for the IP address you need, using PERL or your favourite scripting tool. For example, here is how I chained sed and awk to find the line "IP Address" that comes in the "WAN" section:
lynx -auth=\ :admin http://192.168.1.1/Status.htm -dump | sed "1,/WAN/d" | awk -F: '/IP Address/{print $2}'
Note that there is a single space between "\" and ":admin".
- Matt Willis
2cent tip Available space available on Hd - follow upyes and for those of us who can not do the math include the -h command line option!
here -
df Filesystem 1k-blocks Used Available Use% Mounted on /dev/hda1 2028098 1603178 320098 83% / /dev/hda3 9991422 607203 8865722 6% /home /dev/hdb 60334 60334 0 100% /mnt/cdrom df -h Filesystem Size Used Avail Use% Mounted on /dev/hda1 1.9G 1.5G 313M 83% / /dev/hda3 9.5G 593M 8.5G 6% /home /dev/hdb 59M 59M 0 100% /mnt/cdrom
-- Ted Potter
Tech tip -- removing all files except *.cI have a question about rm command. Would you please tell me how to remove all the files excepts certain files like anything ended with .c?
The easiest way (meaning it will work on any Unix systems anywhere), is to move those files to a temporary directory, then delete "everything", then move those files back.
mkdir /tmp/tdir mv *.c /tmp/tdir rm * mv /tmp/tdir/* . rmdir /tmp/tdir
netscape to read html files ( $0.02 )I usually have netscape open, and I also have several terms open, also some files only have html documentation (e.g., htdig ). I added this bash function to my .bash_profile to send a file to netscape at the command line. (for a list of the options type netscape -help):
function ns () {
if [ "." = "$(dirname $1)" ]; then
argpath=$(pwd)
else
argpath=$(dirname $1)
fi
url_arg=${argpath}/$(basename $1)
netscape -remote "openURL(file://$url_arg)"
unset argpath url_arg
}
export -f ns
So for README its :
me@box] vi README
but for README.html
me@box] ns README
Need info (Need Outlook to speak to Linux) (Issue 61, 2 cent tips)...no less than 5 people mentioned...
It sounded like the poster wanted to provide native MS Exchange services using a UNIX/Linux server. If so, she should look into HP OpenMail (http://www.hp.com/go/openmail).
Anthony
... P Kelly from pksings.com cared to add...
HP openmail, free for under 50 users. Not super easy to install but free....
PK
2-cent tip - module resource detectionWe started doing something interesting in Tips - we have some good scripts to do nice little things. But, a lot of people have reported difficulty doing the necessary cut-and-paste. So I'm sure you'll be glad to know that a number of these will now be completely seperate files with a .txt extension, so that they can be downloaded safely.
Tip: As long as you have a #! line, linux doesn't care in the least whether the filename has a reasonable extension... or any at all, for that matter.
Here's the popularly requested resource detection script.
See attached misc/tips/shotgun.bash.txt
8 Cents Worth[near the tail end of a thread where we are being really careful with rm]
[Dan] It would be prudent to try the thing out in a directory containing only expendable files with names similar to the intended victims/saved.
[Dan] I've more than once had to resort to backups due to a slip of the fingers (the brain?) with an "rm" expression.
Note that he actually has known good backups to resort to.
[Heather] tip: echo (rest of command)
will reveal what globbing is about to inflict on you. Won't solve everything, but at least you'll be safe from the shell's perspective.
[Ben] Good call! It's also well worth checking out the "shopt" built-in command, particularly the "extglob" and "nullglob" options (I sort of wonder why "bash" doesn't default to those being on); they can make dealing with globbing a slightly friendlier experience - as well as slightly more intuitive, in my opinion.
Shebang problemsYou have a question & answer on Linux Gazette with title:
shell cannot see an existing file --or-- ./script: No such file or directory
One possibility you don't mention, which I've just found out the hard way (ie. by using a lot of time) is that the file should not have been written with a dos/windows editor (eg. on a samba share). CRLF at the end of the shebang line causes exactly the chain of frustrations your correspondent describes -- as far as I can be bothered to test (more time) this seems to be completely consistent for bash and python scripts with a shebang line.
Oddly enough removing the shebang line makes the thing work -- the shell exec() which you also describe is not CRLF sensitive.
Paul Mothersdill
about Unix command psIs there a way to find out the date when a process is created?
"ps aux" shows the date and a lot of other information as well. You can use
ps aux | grep DESIRED_COMMAND_NAME
to filter out unwanted processes, or specify the process ID as
ps aux 1234
...so, she tried that, but it wasn't what she needed...
I am using HP unix. ps -aux is the same as ps. It gives only the execution time, but not the elapse time. Any other options?
ps has a bazillion options; see if elapsed time is listed in the manpage.
If the process hasn't started yet and you don't need the time until after it's over, there's the "time" command.
-- Mike Orr
Linux security FAQThe Linux Security FAQ has been slashdotted.
http://www.linuxsecurity.com/docs/colsfaq.html
renaming directorieshow do you rename/change names on directories? thanks
Use the 'mv' command.
Please send follow-ups or future questions in text format rather than HTML. It makes it easier to read them.
hi im a moronOn Sat, Jan 27, 2001 at 01:22:57AM -0500, . wrote:
hi im just wondering how to make a swapfile on my linux sys
I beg to differ about that "moron" part. After all, you knew enough to ask a question in the right place!
I'm assuming you really want a swapfile, as opposed to a swap partition.
A swapfile will be slower than a partition, but it can be a handy thing for that sporadic task that really chews up memory.
The way I usually do it is first to make a zero-filled file of the desired size using "dd":
dd if=/dev/zero of=/usr/tmp/newswapfile bs=1024 count=65536
for a 64M swapfile. Vary "count" as desired. Then
mkswap /usr/tmp/newswapfile swapon /usr/tmp/newswapfile
If you wish to have the swapfile mounted at boot time, find the appropriate place in your init scripts and add the "swapon" command.
See "man mkswap", "man dd", "man swapon" for more info on swapfiles.
-- Dan Wilder
tar on remote file system ...On Mon, Jan 15, 2001 at 07:16:28AM +0000, Hansjoerg Graesslin wrote:
Hi, I read your article about making backup to remote tape devices, but is there any way to make a backup on a remote file system with the tar command ??
I tried :
tar czSf - test | rsh -l operator remotehostand get something strange ...
$ tar czSf - test | rsh -l oracle skye
tar: z: unknown option
Usage: tar {txruc}[vfbFXhiBelmopwnq[0-7]] [-k size] [tapefile]
[blocksize] [exc.
tcgetattr: Invalid argument
ioctl I_PUSH ttcompat: No such device or address
$That's not particularly strange, given that you seem to be using something other than GNU tar. There are many different versions out there; which one do you have? GNU's version has supported "z", the "filter through gzip" switch, since at least early 1997, when I started using it. So, what's happening above is that "tar" fails with fireworks - and pipes something of that to "rsh", which also explodes and screams in agony (hmm. Too many Schwarzenegger movies lately, I guess.) A hint for next time: when you have a problem that involves several programs. separate them in order to find out which one is giving you a problem (or at least, which problem.) It's much easier to troubleshoot things that way.
any ideas ??
Yes. Go to http://www.gnu.org and download the latest version of "tar". Compile it, run it, and if you encounter any problems at that point, write to us again. This time, include the versions of both "tar" and "rsh", as well as which distro and version of Linux you're using. I have a feeling, though, that the first suggestion will fix the problem.
Your article in Linux gazetteHi,
I scanned through your article in Linux gazette today, and having used a configuration similar to this about a year ago, I thought that you might appreciate this information:
Lilo can write the boot sector information directly to a file so the stuff with lilo.dummy and dd is not necessary. E.g. in my configuration, /dev/hda1 contained a vfat partition including the NT loader (mounted to /dos in linux). I had the line:
boot=/dos/bootsect.lin
in my /etc/lilo.conf and provided that the partition is mounted and a file exists (first time do "touch /dos/bootsect.lin") it should work (unfortunately I'm currently using a different configuration so I can't verify if i forgot something).
There can be issues if you have a large hard disk and the linux kernel is not in the beginning; these are better covered in other documents, but to avoid these I also copied my kernel to /dos/linux/vmlinuz. I'm not sure if these are still valid with the current versions of lilo, though.
//jani
Diald and AIMAnswerguy,
I've notice a strange anomaly in the last couple of months when using DIALD to connect to any local ISP. I have a simple setup, boxA (the MASQ, RedHat 5.2) and boxB (private IP, Win98). Everything works great except when I try to use AOL's Instant Messenger. Upon starting AIM the usual happens... Connecting.... Verifying username and password... Starting services.... then the roadblock of "Connection lost. Check your Internet connection". Viewing my log files I get "kernel: MASQ: failed TCP/UDP checksum from 64.12.24.172". However, if I dial up any ISP with a normal pppd script (less the SLIP interfaces involved for diald) it works. At this point I'm not sure what I need to do to resolve this problem. Have any ideas?
Thank you, Michael
... but he solved it!
Answerguy,
I have resolved my problem by passing the following to pppd when starting diald...
/usr/sbin/diald -f /etc/diald/diald.conf -- asyncmap 20A0000 escape FF
Geforce2 and X 4.0.1Lots of people sent help about the Geforce card! Thanks bunches! -- Heather
...
Regarding Ron Nicholls question in "The Mailbag" (January 2001) on using an nVidia Geforce2 card under XFree86 4.0.1
As of today, he has two alternatives:
1. He can download the binary drivers provided by nVidia, which are
designed to work in 4.0.1 replacing XFree's drivers. These drivers will give him improved 2D acceleration and 3D acceleration via GLX. I've been using this setup with an nVidia RIVA TNT2 and a Geforce2 GTS (both 32Mb) with no problems whatsoever.
...another reader noted that the driver has to be compiled to match your kernel version. He must be using the source rpm, I think - Gustavo Alday found a complicated URL which seems to hit paydirt:
http://www.nvidia.com/Products/OpenLinuxDwn.nsf/b99b7f622d429347882568c800771b6c?OpenView&Start=1&Count=30&Expand=2#2
2. He can grab 4.0.2 (compile it himself and/or get binaries) for
very decent 2D acceleration for any nVidia card, including GeForce2s. I tried this the day after 4.0.2 but unfortunately had trouble getting the GLX extensions to work so I switched back to 4.0.1
...Michael Coyne (michael from coyne.tc) noted that Mandrake 7.2 autodetected his card, though he suspects DRI support isn't active, and that he has used his card happily on a continuously upgraded RedHat system with the generic nvidia server.
The instructions included with the nVidia drivers are more than enough to get it to work, so check out the drivers at
http://www.nvidia.com/Products/Drivers.nsf/Linux.html
Hope this helps.
And to the nVidia people: �PLEASE OPEN UP YOUR DRIVERS! -- Ernesto Hern�ndez-Novich
...ah, but Ryan Phillips (ryan.phillips from csus.edu) seems to have exactly what our querent wanted; the same system in good working order, and a pointer to a URL describing how:
http://www.evil3d.net/articles/linux/howto/nvidia/redhat7
Thanks again, everyone!
Setting up print filtersHi Answer Folks!
In issue 61 there was an Answer Guy question on getting an Epson Stylus 670 to work under linux.
Making color printers work seems to be a very common question on the various linux fora and newsgroups with very few answers forthcoming.
I'd like to recommend turboprint from http://www.turboprint.de
It supports a wide variety of Epson, Canon and Hewlett-Packard color printers (including my Canon BJC-3000!).
It's currently at version 0.70 and is free (as far as I can tell from the web-site). No source is provided however.
It installed quite easily from a tar-ball and works like a dream for me.
The install process will even "probe" your system looking for "helper" programs (like enscript, a2ps or html2ps) that the filter uses to handle various sorts of files and let you know what you're missing.
(Actually finding RPMs for the various pieces and getting the dependencies resolved is another issue entirely <g> ![]()
You can set up multiple configurations for a single printer to handle different print media (plain paper, glossy paper, transparencies), different print media sizes, different resolutions and has a whole range of other adjustments for color saturation and absolute page positioning.
The latest version even has a couple of graphical (gtk based I believe) application to do the configuration in addtion to ncurses based tools.
Best of all, the fellow who created turboprint answered my dumb configuration question very promptly and in English!
There is also http://www.linuxprinting.org with a wealth of other information. (Hmm.. I couldn't get there just now <shrug> ![]()
You might also check out the Linux Hardware Database at:
http://lhd.datapower.com
Which has a section on printers.
I hope this information is useful.
Simeon ben Nevel --
More e2label scriptingI was not satisfied with the label display script that I wrote and sent in about 1 week ago because it ignored SCSI devices. This one should be a little more generic.
Allan
See attached misc/tips/label.sh.txt
RE: reading a number in a bash shell script. Here is my final scMy name is Steven and I was wondering if there is an easy way in a bash shell script to tell if the variable you read is numberic?
For example
#!/bin/bash
#set -x
Just a comment here: the above line is unnecessary. The "-x" argument can be used with "/bin/bash" directly to get the same effect.
echo -n 'Enter a number '
read x
????????????
How can I tell if $x is numeric easily? I have read and reread the docs, but I see no number test. I was thinkg about trap but I do not understand how it works.
'trap' has no relation to what you're trying to do; it deals with signals. Here is what you want:
[ $(echo $value|grep -c "[^0-9]") -gt 0 ] && echo "Not a number."
We simply ask "grep" to check for the presence of non-numeric characters, and echo a message if they're present.
Shell variables can be declared as numeric via the "declare" or "typeset" commands; they do fairly well with strings like "abCD43" by reading them as 0, but fail, very loudly, on strings that start with a digit:
value too great for base (error token is "3x")
The "grep" test always returns sensible output.
-- Ben Okopnik
This script will read a tnsnames.ora file ( Oracle stuff ) and connect ou to the appropiate instance in sqlplus. Thanks for your help!!!
Steve
See attached misc/tips/spdist.bash.txt
RE: Trident NTSC driversHeather--
Since I wrote [asking after the trident drivers] I discovered that no additional drivers are needed. What I DID find is Trident's manual is WRONG about the jumper on the card. It says it needs to be off to auto detect whether the card is connected to a vga or composite video device. In fact, it needs to be ON...jumpered to work correctly. Exactly opposite of the manual. If this helps someone, please pass it along.
Later--
Darrick
A rather unique query -- solved!First - THANK YOU to everyone who made suggestions and offered expertise on solving this problem. I was just mucking about in my linux directories - searching for config files when ...
The SOLUTION: Install the GL1 driver package as is. Copy the actual driver file "firegl1" to /dev. Pico XF86Config-4, add the driver name to the video card device, and change the default video depth to 24. Then run startx at the command prompt and inko presto - graphics!
Now I don't have to worry about changing the kernel - thank heavens!
Thank you all so much! Karen Gartner
Shebang problemsYou have a question & answer on Linux Gazette with title:
shell cannot see an existing file --or-- ./script: No such file or directory
One possibility you don't mention, which I've just found out the hard way (ie. by using a lot of time) is that the file should not have been written with a dos/windows editor (eg. on a samba share). CRLF at the end of the shebang line causes exactly the chain of frustrations your correspondent describes -- as far as I can be bothered to test (more time) this seems to be completely consistent for bash and python scripts with a shebang line.
Oddly enough removing the shebang line makes the thing work -- the shell exec() which you also describe is not CRLF sensitive.
Paul Mothersdill
How to hack a proxy (LG #53, Query number 16, I think)Dear Iman,
I would suggest you visit http://www.anonymiser.org or http://www.privatesurfing.com and use their free service. But be careful, your administrator gets suspicious, and even these sites can get blocked. [That is a risk I have to live with when using my ISP-Emirates Internet and Multimedia.]
You can use a good search engine like http://www.google.com and enter "anonymiser" in the search box. Or better yet, use this search engine to search for your topic of interest, and retrieve your page of interest from Google's cached pages. Since Google will fetch the page for you, your proxy will 'be tricked into thinking you are receiving a page from Google'!
Alternatively, you could use one of the online web page caching servers (search for "free ISP" on Google's search engine) to fool your proxy server in a similar way.
And here is a method my friend claims to have used, but I never tested myself. I don't even know the legal implications of using this system. do this at your own risk. Set your http proxy to one that is outside your network. That way, (theoretically) you will use your local network proxy to access the net, use the net to access this other proxy, which in tern you will use to access the hackers' sites.
You might have noticed (and in fact you should have noticed by now, that using any of the methods I gave you, you will simply fool your network proxy, not crack it.
You Wanted To Crack, Not Hack There are great differences between hacking and cracking. Please check out the page, "How to become a Hacker" at http://www.tuxedo.org
Salaam, and Goodbye Faisal Halim
bogoHello,
I tried your little bogo script. I installed bing-1.1.3 and traceroute -1.4a7. However ,when I execute the bogo script I get the following:
(kvh)-(20:15)-(~)> ./bogo
real 0m24.083s
user 0m0.010s
sys 0m0.000s
Ping time to ISP: ms
Measuring speed...If you take a look at the script itself, you'll note that the comment immediately following the script description tells you to change the default ISP name (www.mindspring.com) to your own ISP's URL. Also note that in my 2-cent tip I wrote:
"... it prints the time that is required for the first 'ping' to reach your ISP, as well as the time that it takes to execute that ping. In my experience, if that execution time is much longer than 3 seconds, you've got a poor connection and should try redialing."
24 seconds, as your output above shows, is quite a bit longer than 3 seconds. What it's saying is that the ping is probably not getting through to MindSpring (unless you've modified $ISP) at all - most likely, it's timing out. I recommend that you 1) replace "mindspring" with your ISP's URL, and 2) ping that URL once you're connected to see the results.
Ben_OkopnikWerner Gerstmann wasn't the only person who asked what 'bing' was, but he did have a curious reason to be unsure:
Hallo Ben,
in #61 of LG I found some nice scripts of yours. One question: in the one for measuring a modem connection, a progamme's name is "bing" or "ping" ?? For me it's a bit funny, because in Germany we have a regional slang (the Saxons), they cannot distinguish "d" and "t" or "b" and "p" (the soft and the hard ones), but normally only if they speak ! ! If "bing" is correct please give me a hint where to find it.
Regards Werner
It's "bing", an "empirical stochastic bandwidth tester" as its author calls it, with the 'b' coming from the term "bandwidth". I just think of it as a smarter "ping". In Debian, it's part of the distribution, as part of the "net" category; their source for it was 'bing_1.0.4.orig.tar.gz', available at their site.
<ftp.debian.org/debian/dists/potato/main/source/net/bing_1.0.4.orig.tar.gz>
Measure your modem connection - BogospeedOn Sat, Jan 20, 2001 at 10:27:14AM -0500, Joe St.Clair - KSI Machine & Engineering wrote:
What it "bing" that is needed for the "Bogospeed" script?
A lot of folks have written in to ask this same question. I'll admit to being a bit surprised, but here's some easily-retrieved info.
A search on Google for "bing and linux" brings up over 10,000 hits. The very first of these says
"Debian GNU/Linux -- bing Package: bing 1.0.4-5.3.1. Empirical stochastic bandwidth tester."
For those of you who are left as unenlightened by this as I was, it's just a fancy way of saying "a smarter version of 'ping'".
Yep; that's the dude. In fact, due to the fact that the author of "bing" has unaccountably changed the entire syntax and output of "bing" with the new version, the only one that will work without modifying the script is version 1.0.4. It's easy enough to download and install. <grin> For anyone who has read my series on shell scripting here in the LG, modifying it for the new version should be a trivial task.
As well, here is the "new and improved" version of the "speed" script; due to feedback from several of our readers, I've generalized the IP/time parsing routine, which should make it a bit more useable.
I took the liberty of promoting the warning comment to an actual message, in case anyone finds it useful enough to leave lying around. -- Heather
See attached misc/tips/speed.bash.txt
Technology has changed dramatically over the last few years in terms of computers and their hardware/software, but how has it changed in school and education?
Let's look at one secondary school in the UK. This school used to complete GCSE and A-level work on 386s until just about 2 years ago when they managed to upgrade to brand new PCs, and since then get new PCs quite regularly. So they will now have well over 150 PC's for around 1500 pupils (including 6th form), although some schools would find it hard to get enough for just one class with around 30 pupils.
These systems are good too. They are in working condition by a on-site technician. The specs are good, especially as they are mainly used for teaching the basics to younger pupils. By the time they are doing GCSE/A-level work, it is not necessary for a very high spec as most of the work by then is simple office work, especially a lot of word processing, even so they have some very fast systems.
All these computers are networked, so any pupil can log on and then get their previously-saved documents on any computer in the school. This also prevents pupils from messing about with the BIOS and control panel settings, etc., since they each have a individual name witch can be traced.
But what is at the centre of all this? Well since Windows is seen by many people as easier to get to grips with, that would seem a good choice. But Linux Versions are now just about as easy--they no longer require large amounts of knowledge. Then, since these computers are all networked, Linux would be a good option. Also, what is the whole point of education?- to get qualifications for a job. It is thought Linux is fast becoming more popular (if not already) than Windows, and more and more computers in businesses run Linux, so people going into any area of business would benefit from the experience of Linux. Also, it has good networking features, and is more customisable, also by many people it is thought to be more stable to run than its competitors. Not forgetting the difference in price: you can pick up a full 6-CD version of SuSE Linux 6 for �30 (or less if you know someone who has it already), and make money out of it! Compared to possibly hundreds of pounds for competitors' networking OS's.
Therefore, this school runs Linux Red Hat or SuSE, right? WRONG! It runs Windows! I ask this question to the British government: how are the pupils supposed to survive in the 'big world' of computing nowadays if they don't have at least the opportunity to experience at least the basics of another graphical OS such as Red Hat or SuSE Linux. OK, it is easy to get to grips with Linux, but nowadays potential employers won't look at you twice unless you've experienced it, so what are you supposed to do--lie???
So isn't it about time that the government make new guidelines as to how GCSE and A level are obtained, and allow the support of multi-operating system knowledge? This would also help show the full possibilities of Linux and open sourcing in general. Let's not forget the government money saved by using open-source software instead of the usual software. The benefits are obvious: no more expensive site software licences!
This would also generate more interest in open-sourcing among the younger generations. Also showing that the government and local authorities aren't biased just because they want to collect more TAX, but would support the cheaper software, even though they wouldn't get as much for themselves. But they wouldn't need as much, either, since they would no longer have to spend as much resources investigating software piracy!!!


[Eric also draws the Sun Puppy comic strip at http://www.sunpuppy.com. -Ed.]
Abstract
This document was inspired by my efforts to get a functioning development environment up and running on a Linux machine. Trying to put a development environment together under the Cygwin environment infuriated me so I focused on getting everything working under Linux. This will explain what software needs to be installed which includes an emulator, compiler, and SDK. This will also explain what configuration issues need to be addressed.Introduction
A friend and I one day said, "Wouldn't it be great if we could write our own palm apps?"
It sounded like a great idea, so I started looking into what it would take to get a development environment put together. He is primarily a win32 user, and I am almost soley a *nix user. Since win32 was a common platform available to both of us I began this process by looking into available tools.
For win32 there are two main ways to go for C development. One of these is Metrowerk's CodeWarrior for Palm, which was expensive for our hobby style project. The other option was using the PRC tools that would run under the cygwin environment. If you are not framilliar with the cygwin package, is it available from http://sources.redhat.com/cygwin/ . The cygwin package makes your win32 machine feel a lot more like a *nix machine and provides win32 ports of many common *nix tools (ls, dd, gcc, etc.).
After fighting with the tools on win32 for most of a week and getting nowhere, I decided to scrap the idea of developing on win32. Therefor, Linux, specifically RedHat 6.0 and 6.2, was the next choice and the ultimate solution.
There are several pieces that need to be assembled to get everything working and usable on Linux. Here is a basic list of what is needed:
Getting Started (Installing the Emulator)
The first part of getting everything going is the POSE Palm Emulator. It can be retrieved from http://www.palmos.com/dev/tech/tools/emulator/ along with various skins (graphic representations of the hardware). If you have compiled programs before, than this should be a snap. POSE does require the FLTK library for its menus and all. FLTK is available at http://www.fltk.org. Again, if you have compiled any other programs, then this will be very straight forward.
OK, you've gotten POSE compiled and installed and you think you're ready to go now? Well, not quite. POSE does not contain any ROM images in it. ROM images are the snapshots of PalmOS that reside on the FlashROM in the Palm itself.
We can do two things to get an ROM image. First, there is a Palm app that comes with the emulator that will allow POSE to suck the ROM image right off your PalmOS device. [Pretty cool, huh?] The second way to get a ROM image is to join palm.com's solution provider program at http://www.palmos.com/dev/program/. Once you have joined you have access to the Provider Pavillion at http://www.palmos.com/dev/pavilion/ which contains various ROM images. Some of the images here are testing and debug versions along with the normal images, so be careful which one you grab. Also, the images in this development area are NOT usually meant to be put onto your PalmOS device. There are separate PalmOS upgrades and ROM upgrades available elsewhere on the site.
Well, now you have the emulator up and running. Right-click, File: New and specifiy what ROM file to use, device you are emulating, graphical skin, and ram size. You should see something like this now.

Installing the Compiler and Its Dependents
A few pieces need to be installed for everything to function. These are the PRC tools, a SDK from palm, and the PilRC tool. The PRC tools are a port of the GCC tools we all know and love, but they produce output for the Palm. The SDK is a few libraries and a whole bunch of header files for the Palm API. Finally, the PilRC tool is the resource compiler.
The PRC tools can be found at http://sourceforge.net/projects/prc-tools/. This is a bunch of patches to binutils, gdb, and GCC, and linker tools to support the PalmOS. RPM's are also available at http://www.palmos.com/dev/tech/tools/gcc/dist/prc-tools-2.0-1.Linux-i386.rpm.
Next comes the SDK's. These are available from the palm.com site. The PalmOS 3.5 SDK (the latest as of this writing) is available only to registered developers in palm.com's provider pavillion. Earlier SDK's are available here: http://www.palmos.com/dev/tech/tools/gcc/dist/palmos-1-2-3.1-sdks-1.tar.gz. The 3.5 SDK contains documentation that covers previous SDK's as well. The older SDK's do not contain these docs.
The PRC install will make a directory called /usr/local/palmdev . The sdk's should be untar-ed here. A symbolic link called "sdk" should be made that points to the SDK that you wish to use. For exmaple, this is what my /usr/local/palmdev looks like.
[scooter@scooter scooter]# ls -l /usr/local/palmdev/
total 28
drwxr-xr-x 4 root root 4096 Mar 8 2000 Palm OS 3.5 Support
drwxr-xr-x 3 root root 4096 Nov 1 10:03 doc
drwxr-xr-x 2 root root 4096 Dec 21 1999 include
drwxr-xr-x 3 root root 4096 Nov 1 10:02 lib
lrwxrwxrwx 1 root root 7 Nov 1 10:07 sdk -> sdk-3.1
drwxr-xr-x 3 root root 4096 Feb 9 2000 sdk-1
drwxr-xr-x 3 root root 4096 Feb 9 2000 sdk-2
drwxr-xr-x 3 root root 4096 Feb 9 2000 sdk-3.1
The last tool that is needed is PilRC which compiles all of the resource files to generate a binary. This has most to do with buttons, menus, and placement of graphics on the screen. It can be found at http://www.ardiri.com/index.cfm?redir=palm&cat=pilrc.
Once all of these tools are put together you have a functional development environment. We are used to using gcc for compiling C programs on Linux so the C compiler for PalmOS is m68k-palmos-gcc. Most of the PRC compiler tools are named m68k-palmos-* .
System and network administrators often use Ethernet packet capture tools such as tcpdump [McCa97] and ethereal [Ether00] to debug network applications by. In some cases, a view of all traffic on a circuit is required to determine why applications are running slowly, or why the circuit is running at a high utilization. When the circuit in question is a WAN (Wide Area Network) point-to-point circuit (such as a T-1), or a Frame Relay network access line, there may not be a point where all of the packets can be observed on an Ethernet segment.
In this article we describe a system to record and analyze ``raw'' Frame Relay and point-to-point T-1 packets. The data are captured by ``eavesdropping'' on the HDLC transmit and receive lines between the router and CSU/DSU. Analysis of the data provides circuit and application utilization information on a one-second or shorter time scale. Routine and custom reports are accessible through Web interfaces to provide easy access by our global systems and network staff. The packet data can also be used to debug applications in the same way as conventional packet capture systems.
Frame Relay networks provide organizations with a flexible and economical method of interconnecting sites over a wide range of distances. A major source of the flexibility comes from the ability to connect many circuits over a single access line, such as a T-1 (1.5 Mbps) or E-1 (2Mbps, used in Europe). Each circuit, called a PVC (Permanent Virtual Circuit), has a guaranteed bandwidth, known as CIR (Committed Information Rate). Most Frame Relay carriers allow PVCs to ``burst above CIR'', possibly to the full bandwidth of the access line. The sum of the instantaneous bandwidth for all PVCs can not, of course, exceed the bandwidth of the access line. This leads to interesting traffic management questions.
Complex Frame Relay networks are often laid out in a ``hub and spoke'' arrangement. Multiple hubs may connect subsidiary offices in a geographical area as shown in Figure 1. The hubs are then joined together, usually with higher bandwidth interconnections.
While debugging Frame Relay network problems, for both bandwidth management and application issues, we have used tcpdump to record packets at the Ethernet interface of routers. We often wished, however, that we could see exactly what data were flowing in and out of the T-1/E-1 serial access lines. This was especially true at Frame Relay hub sites where many packets pass through the router, but never appear on the Ethernet side because they are destined for another site on our network. In addition, useful Frame Relay header information is lost once the frames are converted to Ethernet packets.
Figure 1 provides an illustration of the problem. Of the three types of traffic shown, only the ERP (Enterprise Resource Planning) traffic enters the ``UK Data Center''. Packets for the other two applications, LAN mail and Internet, do not appear on the Ethernet segment but they can consume a large fraction of the bandwidth available on the serial access lines at this ``hub site''.
As we did more application debugging and traffic analysis it became clear that we needed a system to record raw frames outside the router, directly from the communications lines. Then we could examine any of the Frame Relay header information and as much of the data, including IP header and payload, as we cared to record.
Commercial systems were reviewed but none were found that met the requirement to record raw Frame Relay packets for more than a few minutes. Our company already used two of the more popular brands of ``WAN Probes'', but they are mostly useful for real-time diagnostics, and RMON (Remote Network Monitoring Management Information Base) type historical data. We considered using Network Flight Recorder [Ranu97], but it does not record data from WAN communications lines.
While most routers count the Frame Relay congestion notification bits (FECN and BECN, Forward and Backward Explicit Congestion Notification) in the header, they do not count discard eligible (DE) bits. The five-minute counts of FECNs and BECNs that we record via SNMP do not provide any method to assign the occurrence to a particular second, or to particular packets. Debugging an application / network interaction problem without the raw packet data is very difficult.
In this paper we will first review the hardware requirements and packet acquisition software. Then the traffic analysis software will be discussed, followed by real-world analysis examples including ``Congestion and Circuit Capacity Planning'', ``Using the Raw Packet Data'', and ``Application Profiling''. Two short sections describe the extension of the system for T-1 point-to-point circuits, and using tcpdump to perform similar analysis when the packets of interest are available on a LAN. We will close with some ideas for future applications.
The system is built on a low cost desktop platform running RedHat Linux (version 5.2 or 6.x). The heart of the hardware is one or more communications boards from sangoma.com, previously known as Sangoma Technologies Inc., (Markham, Ontario, Canada). The first few monitors we built used two Sangoma WANPIPE S508 ISA cards, but we are now using a single Sangoma WANPIPE S5142 PCI card that can handle four communications lines at up to 4Mbps in ``listen-only'' mode.
Acquiring the bi-directional data requires the use of two receive lines and the associated clock signals on the Sangoma cards. The transmit lines of the card are not connected. While we have successfully connected to T-1/E-1 lines using short cables directly attached to the communications lines, the use of an active ``Multi-Interface Tap'' is recommended. These taps present a high-impedance to the signal lines and allow a long cable to be safely used between the tap and the computer. The cost for a system to monitor a single T-1/E-1, including PC, communications board, and WAN tap is about US$2000. A second T-1/E-1 can be monitored on the same PC for an additional US$800.
The basic model for the system is to record packets in both directions (in-bound and out-bound) for fifteen-minute periods. At the end of each period the packet files are closed and a new pair of acquisition processes are started. Then a summary program processes the data from the previous period.
This model provides considerable simplification at the cost of only about a fifteen-minute delay compared to a real time system. It also allows convenient packaging of the summary results and a method to locate raw packet data when deeper analysis is needed. The hardware requirements are lower for this post-process model; all that is necessary is for the summarization process to complete in less than fifteen minutes while handling the input streams without packet loss.
The software consists of drivers provided by Sangoma, a modified version of Sangoma's example C program for data capture, and a set of Perl programs to control the acquisition and analyze the acquired data.
Sangoma's driver software was set up for CHDLC (Cisco HDLC) mode. The packet capture program, frpcap, writes files in a format closely modeled after the tcpdump format. The only significant difference is that the Frame Relay header is recorded in place of the Ethernet header. The first 150 bytes of each raw packet are usually saved to provide context information during application analysis.
The packet acquisition process is driven by frcap_run, a Perl script that runs every fifteen minutes. Frcap_run stops the current frpcap processes (one for each data direction) and immediately starts another pair. A traffic summary program, fr_decode, is then run on the two packet files. Following the summarization the raw packet files are compressed, and any files that are older than a preset age are deleted to conserve disk space. For a fairly busy set of Frame Relay circuits on a T-1 access line, eight days worth of raw packet files consumes 3-6GB of disk space.
The fifteen-minute raw packet files are summarized by a Perl program that appends its output to a daily summary file in XML format. The XML file is read by other programs for display and further analysis. An example of a fifteen-minute summary output displayed by a Web application that formats the XML data is shown in Figure 2. To reduce the size of Figure 2, data for a minor PVC were removed and only the top five numbers, rather than our usual ten, are shown in each category.
Frame Relay Traffic Summary (Philadelphia)
Out-Bound from Philadelphia Data
Capture Time: Thu Feb 10 11:00:00 2000 - Thu Feb 10 11:15:01 2000 GMT
PVC Summary (Out-Bound from Philadelphia)
DLCI Packets Bytes % FECNs BECNs DEs DE No DE
460 79,648 12,422,725 30.2 % 0 0.0 % 0 0.0 % 0 0 328 London
490 119,404 28,677,448 69.8 % 0 0.0 % 0 0.0 % 0 0 1,321 Paris
All 199,052 41,100,173
Protocol Counts (Out-Bound from Philadelphia)
DLCI Protocol Packets Bytes % of PVC TCP ReTransmits
460 London
0800 06 IP TCP 40,291 9,068,685 ( 73.0%) 328 ( 0.8%)
8137 IPX 34,675 2,805,741 ( 22.6%)
0800 11 IP UDP 1,671 316,118 ( 2.5%)
0800 01 IP ICMP 2,593 197,600 ( 1.6%)
809b ATALK 203 15,000 ( 0.1%)
0800 58 IP IGRP 200 14,616 ( 0.1%)
490 Paris
0800 06 IP TCP 70,203 21,871,361 ( 76.3%) 1321 ( 1.9%)
8137 IPX 46,048 6,228,881 ( 21.7%)
0800 11 IP UDP 2,051 498,644 ( 1.7%)
0800 01 IP ICMP 882 58,936 ( 0.2%)
0800 58 IP IGRP 205 14,886 ( 0.1%)
Access Line Busiest Seconds (Out-Bound from Philadelphia)
Time Bytes kbps
11:08:11 125,513 1,004.1
11:08:09 118,855 950.8
11:08:13 116,336 930.7
11:02:53 108,926 871.4
11:08:14 104,754 838.0
PVC Busiest Seconds (Out-Bound from Philadelphia)
460 London
11:02:53 77,873 623.0
11:02:52 76,221 609.8
11:02:54 47,667 381.3
11:02:56 46,748 374.0
11:00:07 44,487 355.9
490 Paris
11:08:11 112,854 902.8
11:08:13 105,761 846.1
11:08:09 95,425 763.4
11:08:14 92,765 742.1
11:08:10 85,951 687.6
Access Line Quiet Seconds (Out-Bound from Philadelphia)
11:12:53 11,366 90.9
11:12:52 14,118 112.9
11:12:54 15,371 123.0
11:12:55 22,993 183.9
11:11:48 23,544 188.4
PVC Quiet Seconds (Out-Bound from Philadelphia)
460 London
11:05:14 3,640 29.1
11:04:55 3,859 30.9
11:05:33 4,068 32.5
11:07:48 4,118 32.9
11:06:20 4,170 33.4
490 Paris
11:12:53 3,460 27.7
11:12:54 6,613 52.9
11:12:52 8,187 65.5
11:13:18 14,021 112.2
11:12:55 14,065 112.5
Top Sources (Out-Bound from Philadelphia)
Bytes % of Total
1 TCP 155.94.114.164 1867 4,673,580 11.0 Philadelphia GroupWise
2 TCP 10.2.71.201 1494 2,644,817 6.2
3 TCP 155.94.155.23 1521 1,671,696 3.9 ra01u04 - Philadelphia DCG
4 TCP 192.233.80.5 80 1,272,224 3.0
5 TCP 209.58.93.100 1494 931,341 2.2 MARTE WinFrame 1
Top Destinations (Out-Bound from Philadelphia)
Bytes % of Total
1 TCP 10.248.107.217 7100 4,742,966 11.2
2 TCP 10.247.113.201 4498 1,272,224 3.0
3 IPX 0451 01000105 1 1,138,074 2.7 NCP
4 TCP 10.248.89.1 7100 952,921 2.2
5 TCP 10.247.66.76 1073 931,341 2.2
Application Summary (All PVCs, Out-Bound from Philadelphia)
New TCP Total TCP
Application Sessions Sessions Packets Bytes
Internet TCP 4,684 4,817 41,455 13,128,752
IPX 90,631 9,785,697
Unknown TCP 1,016 1,167 41,305 7,141,942
GroupWise TCP 98 138 12,106 6,722,084
DCG TCP 138 150 7,370 1,824,223
MARTE WinFrame TCP 2 5 4,428 1,041,713
IP Protocol 0b NVP-II 3,894 839,902
EDMS TCP 13 20 3,075 775,923
MARTE Oracle TCP 1 3 1,882 472,541
MLIMS TCP 38 22 850 255,473
Internet ICMP 3,255 214,690
Unknown ICMP 780 78,666
ProbMan TCP 0 4 181 48,826
IP Protocol 3a IPv6-ICMP 598 43,012
Unknown ATALK 203 15,000
ASTROS TCP 2 6 62 9,963
TCP SYNs (connection requests): 5996 Total TCP Re-Transmissions: 1662
The report consists of five major sections. The first section is a PVC summary showing the DLCI (circuit number), number of packets and bytes, percentage of bytes per circuit relative to all circuits on the access line, congestion notification counts, DE (discard eligible) counts and TCP re-transmission counts. Since this router does not set any congestion notification information (Frame Relay switches further down stream set these) or DE bits, the counts are all zero for the out-bound direction. Some of our routers do set DE for Internet traffic to give it a lower priority (setting DE tells the carrier that the traffic can be dropped if the network is congested, in exchange the carrier does not count the packets towards certain credit limits). The TCP re-transmit counts are done separately for packets with and without DE so that we can determine the effect on packet loss within the Frame Relay network when DE is set.
Layer 2 and 3 protocol counts are summarized in the second section. For each protocol observed the Ethernet/802.2 type field, IP type by number (if an IP protocol), protocol name, number of packets and bytes, and percent utilization by bytes for the PVC are shown. For TCP/IP a count of packet re-transmissions is displayed.
In the third section we display the busiest and quietest seconds for the access line and for each PVC. The generation and use of these data are described later under Congestion and Circuit Capacity Planning.
The top sources and destinations of data are shown in the fourth section. The protocol, IP address, port number, number of bytes, and percentage of the total for all traffic on the access line are included. If the server name is known it is also displayed, along with a short description of the application.
The fifth section of the report lists the utilization of the access line by application. Where possible we identify applications by the IP address of the server. Although it might make sense to further define applications by port number, many of our servers run a single application. In fact we often have two servers running the same application in which case packets with either IP address will count towards the application. Database servers often run multiple applications which all use the same IP address/port number pair so the addition of a port number qualification would still not uniquely identify all applications. In the future we hope to encourage the use of virtual IP addresses assigned on a per application basis to provide a simple accounting method. The ``New TCP Sessions'' column indicates how many sessions were initiated during the fifteen-minute period and ``Total TCP Sessions'' counts both new and ongoing sessions. For Web based applications these counts are not very useful except as a type of hit counter, but for applications with persistent connections it is a measure of the number of users connected during the period.
The final two items in the report are a count of initial TCP SYNs, which might be used for intrusion detection, and a count of TCP re-transmissions for all PVCs.
Figure 3 shows the top of a report for the in bound direction. Note that we have a variety of FECN, BECN, and DE information related to packets flowing in this direction. The FECNs and BECNs provide information on the level of congestion in the carrier's Frame Relay network [Blac95]. The rest of the report contains the same information as shown in Figure 2.
In-Bound to Philadelphia Data Capture Time: Thu Feb 10 11:00:00 2000 - Thu Feb 10 11:15:01 2000 GMT PVC Summary (In-Bound to Philadelphia) DLCI Packets Bytes % FECNs BECNs DEs DE No DE 460 62,915 6,453,502 36.9 % 515 0.8 % 31 0.0 % 2,211 6 111 London 490 109,900 11,024,584 63.1 % 39 0.0 % 11,800 10.7 % 0 0 656 Paris All 172,815 17,478,086
Several customizable reports using the fifteen-minute summary data are available. A Web form can be used to select a single application and then generate a list of ``Application Summary'' entries for just that application. This list of application usage is very helpful for determining the bandwidth impact of an application and the number of users. Since we are often told, ``There will be 400 users in Europe accessing this Philadelphia based application'', we can use the tool to judge how many are logged-in simultaneously and to monitor usage growth. Another program will generate a daily or monthly ``Application Summary'' by summing usage for each application over time.
The above example data is for one of our busier access lines, but it is far from the most complex. One European Frame Relay hub site has 13 PVCs on a single access line. Some of the traffic is business critical telnet traffic between subsidiary sites and an AS/400 at the hub site. Much of the traffic, however, is intranet mail or Internet data that comes in on one PVC and then heads towards the US on another PVC. Without the Frame Relay monitor it would be very difficult to determine what applications and protocols consume the PVC and access line bandwidth. In some cases it is necessary to obtain application summaries for a single PVC to determine what is happening on a particular circuit. We do not routinely report application and protocol usage on a per PVC basis in order to keep the size and complexity of the reports reasonable.
Like many organizations, we collect router statistics via SNMP every five minutes. While five-minute averages are a useful measure of how a circuit is doing in relationship to its bandwidth limit, they do not tell a lot about the instantaneous (one second, or smaller, time scale) state of a circuit that governs interactive performance. If a circuit is saturated for several ten-second bursts during a single five-minute period the average utilization might appear to be quite reasonable. An interactive user, however, would likely say that the network was slow while his packets were waiting in a router buffer.
Our monitor attempts to measure the largest peaks in a fifteen-minute period by summing the number of bytes transmitted and received for each one-second interval. The summary program reports the ten busiest seconds for the access line and each circuit. A sample plot of busy seconds for one day is shown in red in Figure 4. Time periods with a wide range of values are good because they indicate a large variation in the top ten busy seconds and therefore there are fewer than ten very congested seconds in a fifteen-minute period. The lack of busy seconds below the full speed of the T-1 (1536 kbps) starting at 12:45 GMT indicates significant on-going congestion. There are several busy seconds above the 1536 kbps line. These are probably due to packets being held in buffers. We hope to reduce the delays in servicing interrupts by prioritizing the data acquisition process. Quiet seconds are measured in a similar fashion. If a usually busy circuit has seconds with zero, or a low number of bytes, then it may indicate a circuit or routing problem.
We had one problem where a large number of quiet seconds were showing up with low utilization during busy times of the day. Since there were also user complaints, a detailed analysis of the packet data was performed. It showed all IP traffic periodically stopping for about eight seconds while IPX was still flowing normally. We traced the root cause to an IP routing problem. Without the IPX traffic the problem would have been easy to spot since there would have been periods of about eight seconds with zero traffic on an otherwise busy circuit.
While we have not yet developed a formal rule set, it should be possible to determine how well PVCs and access lines are sized with respect to the actual traffic using busy second data. Clearly, looking at the busiest seconds on a circuit is much more meaningful than five-minute average data when mission critical interactive applications are the most important traffic.
Since the raw packet data are stored in separate files for in-bound and out-bound directions the two files must be combined for traditional packet trace analysis. A utility program performs this task by putting the packets from a pair of files into a time ordered sequence and writing a tcpdump format file. A ``Frame Relay information'' file containing the Frame Relay header information is also written.
We have a packet trace analysis program originally written for tcpdump files that can optionally read the ``Frame Relay information'' file and list the DLCI (circuit ID), FECN, BECN, and DE bits for each packet. Using this feature, we have discovered that some applications were operating over asymmetric routes. In addition to our own analysis programs, the tcpdump format files can be examined using other programs such as tcpdump itself, or ethereal [Ether00]. Since ethereal, and its companion program editcap, can export packet data to other formats, the traces can be analyzed with popular commercial products. When a session needs to be followed through multiple fifteen-minute periods we use a simple program to concatenate multiple tcpdump files.
In a previous paper [Meek98] we discussed interesting issues we have had with our telecommunications vendors. Our complaints about a slow circuit sometimes yield a vendor response like: ``Customer is exceeding CIR by 160%'' with the implication that the over utilization of a circuit (bursting) has lasted for an excessively long period. With raw packet information it should be possible to compute bandwidth utilization on a per-second basis and use the same algorithm as the telecommunications equipment to verify when, and by how much, CIR was exceeded. Figure 6 shows the per-second bandwidth utilization of a circuit for a thirty-minute period and the percentage of in-bound packets with the BECN bit set to indicate congestion on the out-bound circuit. The BECNs are sent by the carrier's switches to indicate that there is congestion in our out-bound direction and that our bandwidth usage will be throttled if we are exceeding CIR and are out of credits. In the future we hope to use this data to accurately determine when we truly exceed our contracted bandwidth and how we might implement quality of service to prioritize traffic to manage bandwidth bursts.
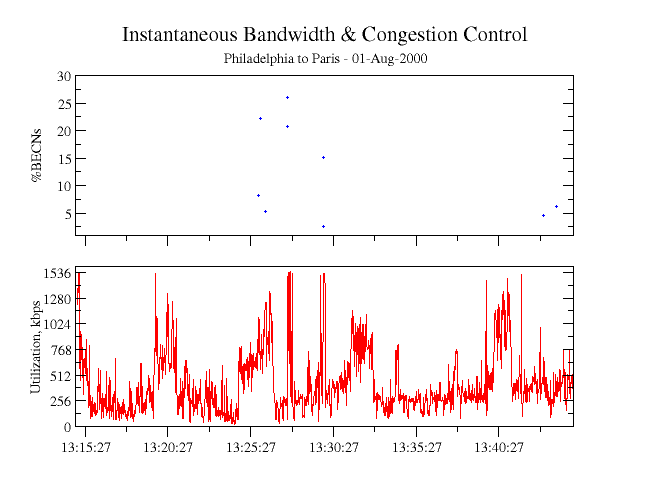
Packet loss is an important parameter in any data network. One measure of packet loss is the percentage of TCP packets that must be re-transmitted. Figure 7. illustrates TCP re-transmission rates on one of our busy circuits over several months. Hours with fewer than 10,000 TCP packets are not shown. Since this circuit feeds multiple downstream Frame Relay circuits, and many LAN segments, packet loss could occur in several places. During late July we had problems with a T-1 interface that caused a significant portion of the re-transmissions during that period. Further analysis of the raw packet data can determine what destination IP addresses were responsible for the re-transmissions. We recently added a new section to the standard report (Figure 2) that lists the top ten destinations of re-transmitted packets to help identify hosts or subnets with problems. Re-transmitted packets are counted by tracking the TCP sequence numbers by session for packets with a payload (not acknowledgment-only packets).
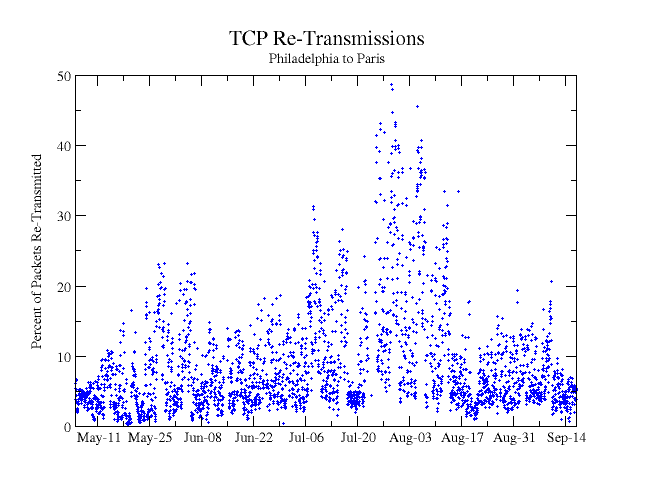
Profiling the bandwidth requirements of an application is a useful exercise to perform during the development or evaluation of a software product. We have often found that applications originally developed for use on a LAN have serious problems when they are moved to a WAN or Internet environment. Problems result from large quantities of data being sent, application level handshaking resulting in excessive round-trip-time waiting, or even the same set of data being requested (and delivered) multiple times due to a programming error. These issues have occurred in both internally developed and purchased commercial software.
One advantage to using the WAN packet capture system for application profiling is that the application under test can be observed along with all of the other data flowing on the circuit at the same time. Since we routinely capture all of the traffic on monitored circuits, no advance preparation is required for most application profiling tests. We have found, however, that it is helpful when testing an interactive application if the test procedure has timed pauses of 15 to 30 seconds where the user does not touch their hardware. The pauses are used to separate phases of the application in the packet traces and to determine if the client and server ``chatter'' when idle.
A disadvantage to using the WAN packet capture system for these tests is that we generally capture only 150 bytes of combined header and payload. While this small number of payload bytes is often enough to determine the context of the application (especially when ASCII or EBCDIC data are involved), it might not be enough to confidently determine that multiple packets with identical payload are being transmitted within a session (determined by computing MD5 checksums on payload content [Meek98]).
Two examples of application profiling are summarized graphically in Figures 8 and 9. The application profiled in Figure 8 is a widely used ERP (Enterprise Resource Management) system that uses page-based terminals as the user interface. The user interacts with the system by filling out text forms and then transmitting the screen page to the server. This method, similar to modern Web applications, is an efficient way to implement interactive applications on a WAN since reasonable size chunks of data, in comparison to keystrokes, are transmitted at one time.
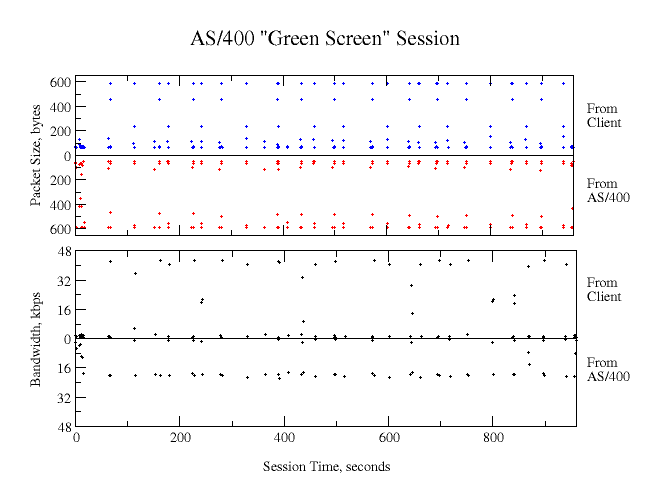
To determine how much bandwidth a single user consumes we look at the packets for individual sessions as a function of time. The top plot shows the distribution of packet sizes for each direction, while the bottom plot shows the bandwidth used per second. A detailed look at the numbers shows that 143,473 bytes in 400 packets were sent from client to server and 112,560 bytes in 348 packets were sent from server to the client. By closely inspecting the data using an interactive data analysis tool [Grace00] we find that a typical transaction is completed in one or two seconds. The maximum bandwidth used was 43kbps from client to server and 22kbps in the other direction.
The packet data in this analysis were extracted from 30 minutes of raw packet capture data from a Frame Relay access circuit with 13 PVCs. The first step was to combine in-bound and out-bound packet streams into single tcpdump format files. The tcpdump files for the two 15-minute time periods required to span the session were then concatenated. Finally, the combined file was processed with tcpdump acting as a pre-filter to select the session of interest and feed it to our own software that summarized the session and prepared the packet and bandwidth data for plotting.
The profile in Figure 9 is from a PC-to-server ``thin client''. The actual application runs on a server and is displayed on the client, much like X Windows, but using a more efficient protocol. Traffic between the client and server consists of keyboard and mouse data, screen refreshes, and, in some cases, file transfer. In this example a file transfer was started at about 2100 seconds into the session.
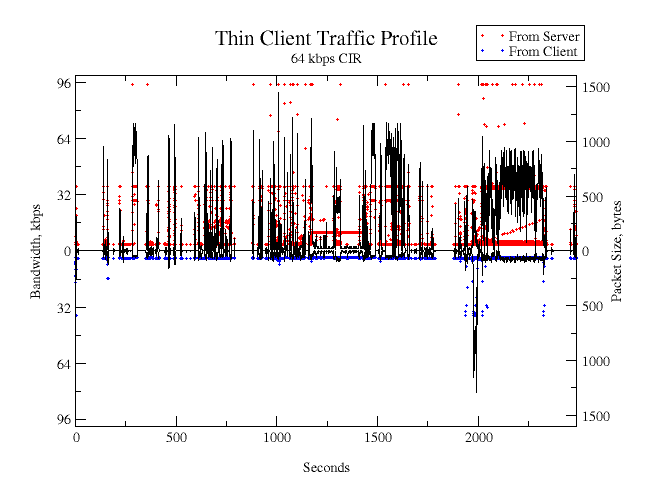
Tools presented here do a complete job of quantifying the actual bandwidth used by an application on a one-second time scale and demonstrating fundamental differences in the bandwidth requirements for different applications (``burstiness'', bandwidth use evenly divided between the two directions, or not). The tools, do not, however, address simulated scaling of the application. Presumably, our data could be used as input to a network simulation tool to perform the scaling simulation to multiple users. Our tools can, however, select any slice of actual recorded network traffic based on source, destination, port number, etc. and determine the total bandwidth utilization for the applications encompassed by the slice. In addition, it is important to consider the effect of network latency on the application. [Meek98]
In order to determine how the use of an application changes over time we can look at some parameter representing usage. In Figure 10 we show the number of sessions per week for one application. The use of this particular application varies depending on business cycles and holiday schedules. Other parameters useful as a measure of application usage are bytes transferred or number of packets. Bytes or packets are especially useful for Web, or other non-session oriented applications.
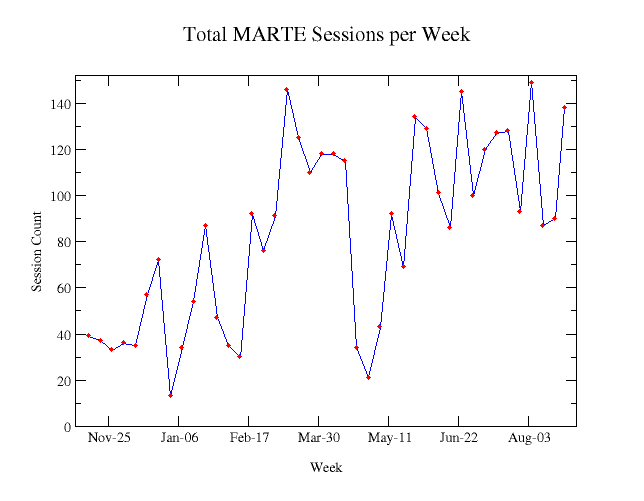
We were pleasantly surprised to discover that the hardware and software can be used without modification on T-1 point-to-point circuits. The packets on the point-to-point circuits have a header very similar to a Frame Relay header. The first two bytes of the Frame Relay header contain packed data representing the DLCI number and the FECN, BECN, and DE bits. [Blac95] The first byte of a point-to-point serial line packet is set to 0x0F for unicast packets and 0x8F for ``broadcast packets'' and the second byte is always zero. [Cisc00] For both Frame Relay and point-to-point serial the third byte contains the Ethernet protocol code. Note that these conventions may be specific to certain types of equipment.
When all traffic of interest is accessible from the LAN, simpler tools and techniques should be used to record traffic. We use a simple script to start tcpdump and rotate the packet capture files on a time schedule controlled by cron (the user-mode command scheduler). The acquired data can be analyzed using the methods described here for WAN traffic.
Because we are now moving some of our major circuits to ATM in order to overcome T-1/E-1 and Frame Relay bandwidth limitations we hope to be able to extend the techniques discussed here to ATM. This should be straightforward if the ATM interface card performs the re-assembly of ATM cells into complete IP packets. The design and implementation of an ATM monitor is discussed in [Api96].
Some of the parameters measured by the system will probably be used to generate alarms when they exceed certain thresholds. The TCP re-transmission rate and quiet/busy seconds are likely candidates for alarms. Frame Relay provides information about circuits using LMI (Local Management Interface) packets. Currently we do not decode these, but plan to add the capability in the future.
We would like to measure the effectiveness of QoS (Quality-of-Service) schemes by measuring packet delays through the router for packets in different classes of service. This would likely be done using tcpdump on the Ethernet side and WAN packet capture on the serial line side of the router. Histograms of packet delays during busy periods should show that the high-priority traffic passes through the router more quickly than lower priority traffic. The results might be used to tune QoS parameters.
We have assembled a low cost Frame Relay and T-1 packet capture system with a large memory and applied it to real problems. The use of this monitor is helping us communicate to management how the WAN is being used at the application level. It also provides detailed worst-case traffic information through the analysis of busy and quiet seconds. We have upgraded bandwidth on some circuits following analysis of peak utilization data, identified unusual routing problems, and profiled the network impact of applications. The large memory and long retention time for the raw packet data allow us to troubleshoot many network problems days after they occurred, an important factor in our large, global organization. The data analysis discussed in this paper just touches on possible uses of raw packet data from WAN circuits. In the future, we expect to mine the information in new ways.
Supplemental information and some of the software used in the work described here can be obtained at http://wanpcap.sourceforge.net.
The author would like to acknowledge Jim Trocki, Kevin Carroll, Kim Takayama, Jim French, and the technical staff at Sangoma Technologies Inc. for valuable discussions, advice, and information during the development of the tools. Drafts of this paper were expertly reviewed by Bill Brooks, Kevin Carroll, Edwin Eichert, and William LeFebvre.
[Blac95] Uyless Black, Frame Relay Networks: Specifications and Implementations, McGraw-Hill 1995.
[Cisc00] Cisco Systems, WAN Group, private communication.
[Ether00] Ethereal, A network protocol analyzer, http://ethereal.zing.org/, 2000.
[Grace00] ``Grace, a WYSIWYG 2D plotting tool for the X Window System and M*tif'', http://plasma-gate.weizmann.ac.il/Grace/, 2000.
[McCa97] Steve McCanne, Craig Leres, Van Jacobson, ``TCPDUMP 3.4'', Lawrence Berkeley National Laboratory Network Research Group, 1997.
[Meek98] Jon T. Meek, Edwin S. Eichert, Kim Takayama, ``Wide Area Network Ecology,'' Proceedings of the Twelfth Systems Administration Conference (LISA '98), USENIX, Boston, 1998.
[Ranu97] Marcus J. Ranum, Kent Landfield, Mike Stolarchuk, Mark Sienkiewicz, Andrew Lambeth, and Eric Wall. ``Implementing a Generalized Tool for Network Monitoring,'' 11th Systems Administration Conference (LISA), 1997.
"Spamming is the scourge of electronic-mail and newsgroups on the Internet. It can seriously interfere with the operation of public services, to say nothing of the effect it may have on any individual's e-mail mail system. ... Spammers are, in effect, taking resources away from users and service suppliers without compensation and without authorization."
-- Vint Cerf, Senior VP, MCI and acknowledged "Father of the Internet"
Spam. Seems like it's become a cost of having an e-mail address these days: if you post in a newsgroup, enter something in an on-line guestbook, or have your email address on the Net in some way, sooner or later you'll get harvested by the spambots. Even if you don't, spam _still_ costs you money: it takes up bandwidth that could otherwise be used for real information transfer, leading to overall higher costs for ISPs - and consequently, keeping up costs of service for everyone. This cost is, incidentally, up in the tens of millions of dollars per month (see http://www.techweb.com/se/directlink.cgi?INW19980504S0003) for an excellent overview) - and this translates directly to about $2 of your monthly bill. If you pay for your access "by the byte", there is yet another cost - and all this comes before you add in the cost of your own wasted time.
Is there anything that we can do? The answer is "yes". We can stop spam from polluting our own mailboxes, and we can intercept it back at the ISP, if we have access to a shell account and they implement a simple tool (and most ISPs that provide shell accounts do). I invite those of you who would like to fight spam at its root to take a look at http://www.cauce.org - these are the folks that are advocating a legislative solution to spam; the information on their site tells you how you can help. In this article, however, I will concentrate on stopping spam locally - at your shell account or on your own machine.
There are several ways to do this, but the most common by far - and one that most ISPs offering shell-accounts already have - is a program called "procmail" by Stephen R. van den Berg, an e-mail processor that uses a 'recipe' that tells it what to keep, what to filter, and what to redirect to another mailbox. So, we need to do two things: first, we need to tell our system to use "procmail"; second, we need to cobble together a 'recipe' that will do what we want.
In my own case, I collect my e-mail via "fetchmail", running as a daemon. This is something I would recommend to everyone, even if you normally collect your mail via Netscape: fetchmail does one job (mail collection) and does it very well, in the worst and most complex of circumstances, things that Netscape doesn't even try to do (multiple servers with different protocols and different usernames, for example) - and Netscape will happily read your local mailbox instead of the ISPs.
Normally, my "fetchmail" will wake up every 5 minutes, pull down the mail from the several servers that I use, and pass it to "sendmail" which then puts it in my mailbox. Whew. Sounds like wasted effort to me, but I guess that's the way things are when you scale down an MTA intended for processing big batches... Actually, using "procmail" eliminates that last step.
In my "~/.fetchmailrc", the resource file that controls what "fetchmail" does when it runs, the pertinent line reads:
mda "procmail"
This tells "fetchmail" to use "procmail" as the mail delivery agent instead of "sendmail" - remember, this is for incoming mail only; your outgoing mail will not be affected.
The other way to do this - and this is the way I recommend if you're filtering mail at your ISP's machine - is to create a ".forward" file in your home directory (this tells your MTA to 'forward' the mail - in this case to our processor.)
Edit ".forward" and enter one of the following lines:
"|exec /usr/bin/procmail"
if you're using "sendmail" (the quotes are necessary in this case).
If you are using "exim", use this instead:
|/usr/bin/procmail
[ Note: According to Mike Orr, "exim" has its own procmail-like filtering language. I haven't looked at it, but it should be in the "exim" docs. ]
You'll need to double-check the actual path to "procmail": you can get that by typing:
which procmail
at the command prompt.
Now that we have redirected all our mail to pass through procmail, the overall effect is... nothing. Huh? Oh yeah - we still have to set up the recipe! Let's take a look at a very simple ".procmailrc", the file in which the recipes are kept:
:0:
* ^Sender:.*[email protected]
linux-kernel-announce
:0:
* ^Resent-Sender.*[email protected]
debian-user
Recipes are built like this:
Notation Meaning
======== =======
:0 Begin a recipe
: Use a lock file (strongly recommended)
* Begin a condition
^ Match the beginning of a line followed by....
Subject: ``Subject:'' followed by....
. any character (.) followed by....
* 0 or more of preceding character (any character in
this case) followed by....
test ``test''
joe If successful match, put in folder $MAILDIR/joe
My own recipe has been in service for quite a while. I built a rather basic one at first, and this immediately decreased the spam volume by at least 95%; later, I added a "blacklist" and a "whitelist" to always reject/accept mail from certain addresses - the first is useful for spammers that manage to get through, especially those that send their garbage multiple times, the second one is for my friends whose mail I don't want to filter out no matter what strange things they may put in the headers (I have some strange friends. :)
For those of you who use "mutt", here's how I add people to those lists: in my "/etc/Muttrc", I have these lines:
macro index \ew '| formail -x From: | addysort >> ~/Mail/white.lst'
macro pager \ew '| formail -x From: | addysort >> ~/Mail/white.lst'
macro index \eb '| formail -x From: | addysort >> ~/Mail/black.lst'
macro pager \eb '| formail -x From: | addysort >> ~/Mail/black.lst'
and in my "/usr/local/bin", I have a script called "addysort":
unless (/\</) { print; } else { print /<([^>]+)/, "\n"; }
Given the above, all I have to do with a given spammer is hit 'Esc-b' - and I'll never see him again. By the same token, a person whom I want to add to the whitelist gets an 'Esc-w' - and they're permanently in my good graces. :)
So, here is my "~/.procmailrc":
# Test if the email's sender is whitelisted; if so, send it straight to
# $DEFAULT. Note that this comes before any other filters.
:0:
* ? formail -x"From" -x"From:" -x"Sender:" \
-x"Reply-To:" -x"Return-Path:" -x"To:" \
| egrep -is -f $MAILDIR/white.lst
$DEFAULT
# Test if the email's sender is blacklisted; if so, send it to "/dev/null"
:0
* ? formail -x"From" -x"From:" -x"Sender:" \
-x"Reply-To:" -x"Return-Path:" -x"To:" \
| egrep -is -f $MAILDIR/black.lst
/dev/null
# Here is the real spam-killer, much improved by Dan's example below: if
# it isn't addressed, cc'd, or in some way sent to one of my addresses -
# all of which contain either "fuzzybear" or "ulysses" - it's spam. Note
# the '!' in front of the matching expression: it inverts the sense of the
# match, that is "if the line _doesn't_ match these words, then send it to
# $SPAMFILE." "^TO" is a procmail variable that matches "To:", "Cc:",
# "Bcc:", and other "To:"-type headers (see 'man procmailrc'.)
:0:
* !^TO .*(fuzzybear|ulysses).*
$SPAMFILE
# X-Advertisement header = spam!
:0:
* ^X-Advertisement:.*
$SPAMFILE
# To nobody!
:0:
* To:[ ]*$
$SPAMFILE
# No "To:" header at all!
:0:
* !^To: .*
$SPAMFILE
For most folks, the only thing necessary would be the last four stanzas of the above (and of course, the variables at the beginning), with the first stanza of that doing 95% of the work. The last three I stole from Dan :), but I can see where they'd come in handy.
By the way, yet another useful thing is a mechanism I've implemented for reporting spammers: in my "/etc/Muttrc", I have a line that says
send-hook (~s\ Spammer) 'set signature="~/.mutt/spammer"'
and a "signature" file, "~/.mutt/spammer" that says
I've just received mail from a spammer who seems to be coming from your
domain. Please fall upon this creature and rend him to bits. His garbage,
with headers, is appended.
Sincerely,
Ben Okopnik
-=-=-=-=-=-
<grin> No, I don't like spammers.
So, in order to send a complaint, I look at the headers with the 'h' key, run a 'whois' on the originating address, hit 'm' to send mail, and type the following at the prompts:
To: abuse@<domain.com>
Subject: Spammer
Given that keyword in the subject, "mutt" pulls up my "spammer" signature file. I save it, append the original spam with the 'A' key, and send it. About 15 seconds of typing, whenever I feel like getting another spam kill. :)
(Just as I was about to send off this article, I got another spam kill, this time from UUnet. <grin> I collect'em.)
On we go to other folks' recipes.
LG itself is in a rather vulnerable position in regard to spam. Since the address is posted on the Net thousands (by now, perhaps millions) of times, it is constantly harvested by spammers. The thing is, "tight" filters of the sort that I've described are not feasible. Consider: what would be a safe "filter" for spam that would not also knock out a certain percentage of our readers' mail? People send mail in from all over the world, in many different ways, with just about every kind of client (including those that create broken headers.) The spam rate for LG, according to Mike Orr, is 28% per month. Rejecting "Precedence: bulk" mail, which can be a good "minor" filter, is not an option: many "News Bytes" entries (since they are bulk-mailed news releases) are sent that way. Even the inquiry that led to the publication of the HelpDex cartoon series came that way.
What to do?
The answer seems to be careful, "accept-when-in-doubt" filtering and checking the "spam" mailbox more often than most people. For the staff at LG, it's just another cost of doing business. Hopefully, even their "loose" filters decrease some of that load.
Dan Wilder, the resident admin and system magician, had the following "spam killer" in his "~/.procmailrc":
Pretty obvious - anything that doesn't match those three domains in the specified headers wasn't sent to him. Dan checks his "spamfile" every once so often - as do I, because real mail can slip by and match by mistake - and this takes care of the tiny percentage of errors.
:0:
* ^(From:|To:|Cc:) .*(-list\
|debian\
|networksolutions\
|ciac\
...
|bugs\
)
$DEFAULT
Much the same thing as my "whitelist", but hard-coded into ".procmailrc" itself. It's not much more difficult to add new people there, so it's just as good a solution as mine, though perhaps a trifle less automatic.
LG's editor, Mike Orr, does a fair bit of sorting (which I've clipped) as well as spam-killing in his recipes (designed by Dan Wilder):
# The real workhorse.
# Bogus recipient .. not To: or From: or Cc: ssc.com,
# and has an "@" in To: (local mail from damaged MUAs may not)
:0:
* !^(To:|From:|Cc:) .*(\
ssc\.com\
|linuxjournal\.com\
|linuxgazette\.com\
)
* ^To: .*@
$SPAMFILE
Hmm, looks like we have a blacklisted spammer here...
:0:
* From: .*[email protected]
$SPAMFILE
# if they have an X-Advertisement header, it's spam!
:0:
* ^X-Advertisement:.*
$SPAMFILE
# To nobody!
:0:
* To:[ ]*$
$SPAMFILE
# No To: header at all!
:0:
* !^To: .*
$SPAMFILE
# Otherwise, fall off the end and default.
Wow. Seems like a whole lot of stuff, doesn't it? In reality, it's minor:
1) Pipe all incoming mail through "procmail".
2) Build a recipe.
That's it. I've thrown in a lot of tips for doing other spam-related stuff, but the above two steps are all you need to do in order to decrease or almost completely eliminate your spam. Oh, look - here comes another tip! :)
If you already have a mailbox full of spam, and you go ahead and do the above two steps, it's really easy to filter it all in one shot:
cat mbox | formail -s procmail
So, you can indeed "de-spam" your mailbox. Thanks to the power of Linux and "procmail", you too can stare at people who complain about getting deluged and say "Oh, yeah... I remember when I had that problem." <Laugh>
Happy spam-hunting!
Back last fall, when I first heard about Caldera's new Volution product it was going into beta I have to admit that it didn't register. "Comprehensive Linux Managment Solution" buffers a meaningful phrase Linux Management between two words that are pure verbal camouflage. The other modifiers it attracted in press coverage "revolutionary," "new," "comprehensive," "significant" came across to me as equally generic PR braggage.
But the concept of "Linux Management" was sufficiently oxymoronic to stick in the back of my mind. The enterprise model of a network is a collection of services: directory, security, management, messaging, Web, print, and so on. As more enterprises build on Linux infrastructure, they'll need the network service called management.
The kind of management we're talking about here isn't just about control. It's about bringing efficiency and knowhow to bear on many systems at once:
Customers in this market want network services that become more valuable as they scale up both in size and rates of change. A management system like Volution only gets more valuable as number of computers, device drivers, operating systems, software packages, and people are added to the network.
Network management is old hat for companies like IBM, HP, Computer Associates and Intel, which all have network management offerings (IBM through Tivoli). But it's new for Linux and new for Linux in the established enterprise environment.
As I began to look into Volution, I suspected it might be the first enterprise product with the potential to elevate Linux into position as serious i.e. marketable enterprise infrastructure. Volution competes directly with the offerings of all the established vendors. An there's nothing exclusive about it, at least where other Linux distributions are concerned. It works with all of them. Caldera also plans to make it work with SCO's UnixWare (decended from the original AT&T UNIX), which Caldera purchased last year.
This scope is due partly to Volution's use of SLP (Service Location Protocol ) a standard Internet (RFC2165) protocol that allows discovery, location and configuration of network services such as mail, print and Web hosting. Caldera has developed a version of SLP, called OpenSLP, that it has contributed to the open source community (www.openslp.org). With OpenSLP, services make their presence known to Volution's management agent without needing to go through any kind of setup, cofiguration or other modification.
The management console is an ordinary Web browser. And the system is enabled by an LDAP (Lightweight Directory Access Protocol) directory. A single client can manage any number of servers with LDAP V3 directories.
As with other enterprise offerings from major Linux vendors (e.g. Red Hat Network Services, SuSE's Email Server II), the product strategy is to close the source and to close marketing mouths about that fact.
To make more sense of what Caldera is doing with Volution, I called on Craig Burton, who is perhaps the world's leading authority on network services (a topic he did much to define both at Novell in the Eighties and The Burton Group in the Nineties). In late January I called on Craig to help make sense of what Caldera is doing with Volution. Normally a curmudgeon about vendor's new products and claims, he makes an exception in the case of Volution. I asked him why.
Doc Searls: What's so special about Volution?
Craig Burton: Two aspects: architecture and strategy.
Doc Searls: Then let's start with architecture.
As management systems go, the Volution architecture is elegant, well thought out, and usable.
First, it's directory-enabled. Volution is a great example of what power and elegance infrastructure can have based on the concept of using a general-purpose directory service for systems design. As such Volution is an example of the way network infrastructure should be built using the constructs of a general-purpose directory and security service to manage the location, identity and state of network objects over space and time.
Second, it uses standards-based infrastructure where possible to do really difficult things, and it does them in a non-intrusive manner. For example, it's hard to discover and create a manageable network without a lot of administrative work and change to the configuration of the very system you are trying to manage. Volution uses OpenSLP to locate and connect to services. this protocol is very cool for creating a manageable environment while causing minimal potential for other problems.
Doc Searls: For example?
Craig Burton: While you still have to install the Volution client on a Linux operating system in order to make it manageable, with OpenSLP, you can do it without having to change any of the configuration files on the target Linux OS. This is because with OpenSLP, services the management server and the client the managed workstation can find each other and rhen exchange information about each other on the network. And they can do it independent of the configuration of the Linux OS on either side. This is a triple whammy. First, Linux doesnt have a native location protocol; and second, every protocol that anyone else uses, Linux or not, is much more intrusive and complicated. Finally, OpenSLP is the only service location protocol that has reached RFC status. Nobody else even comes close to doing that, or having and architecture that lets you do that. Novell is the only vendor that really uses OpenSLP with their management products. This is because Novell had to have a way to convert their service location protocol (Service Advertising Protocol [SAP]) to something that was TCP/IP-based and preferably an RFC. Sun says they are going to use it but isnt doing much yet. I dont think this is an issue either way; but it is a simple functional protocol with RFC status that does the job and then some.
Doc Searls: What about Red Hat? Aren't they doing something here?
Craig Burton: Red Hats management system is a good example of an intrusive system. The Red Hat system uses Novell's NDS it's called eDirectory when it's used with Linux and is therefore directory-enabled. They run the directory they don't really give the customer a choice and they embed their agent so it goes in and makes system changes, and it's Red Hat 7 only. A much better approach to management is to keep the stuff doing the management separate from the stuff being managed. They're also running a service business here. It's not implementing management or directory as discrete network services.
Doc Searls: What else about the architecture?
Craig Burton: Object oriented design is another thing. All of the benefits of object-oriented design come in to play as a result such as reusability, inheritance, simplicity, and consistency. Basically, Volution creates objects that represent what the network looks like and puts them in the directory. For example, if something goes wronga machine quits workingthe management system can look at the object representation of the system (in the directory), check the differences between it and the real system, and fix what has been broken. Or at least make them match and do a best attempt to bring things back to where they were when things were known to be working. The only down side of their object oriented strategy is that they created their own object model. Fortunately they did it in a directory-enabled way, so they should be able to transition to a more long-term solution at a later point.
Another is XML-based encoding. Volution uses XML to communicate between the client and server. This is good for all of the obvious reasons; text-based, extensible, self-discovering and all the same reasons Jabber, for example, uses XML.
Doc Searls: There's the browser interface.
Craig Burton: The interface to the service is through a Web-server. They like Apache. This means the management server talks to any web-based client. This means administration and management can be done from anything that can run a browser. Thats good use of infrastructure and is the way things should work.
Doc Searls: Is it a good enough first effort, or is it missing some things that might hurt its acceptance?
Craig Burton: While Volution is still a long ways from being a finished management system i t doesnt actually provide the full-blown applications that use the services it provides a significant leap forward for the Linux community and does it with what I consider great foundational management architecture: the kind of infrastructure I would recommend and design. It's good for customers, partners, developers and anybody else that wants what it offers.
Doc Searls: That's an unusually strong endorsement. I haven't heard you gush about too many things before.
Craig Burton: I thought about this a lot and I tried to come up with a reason to be more negative, and I couldnt. I think Volution is well thought out. They have a veteran team here. When I was briefed by some of the same guys when they were at Novell doing this work, they were loving it because they were able to build the basic infrastructure building blocks for this system in a fraction of the time it took them to do it for ZEN Works. Those are probably the two reasons why this is so good. It is the second go around for the architects, and it is based on a general purpose operating system and tools. Nice stuff.
Doc Searls: What about strategy?
Craig Burton: Linux is a commodity. It is also truly becoming critical infrastructure. So how does a linux distro vendor bring value to the table? Service? There's no way a distro vendor can scale enought to bing in the service level the cuistomer needs. That's not a long-lasting way to cause shareholder value. What they need to do is field the next generation of Internet services that run on Linux. Caldera is doing that with management services, and doing it in a distribution-agnostic way.
Doc Searls: So they scale with a product that provides an Internet service, rather than try to run a service business.
Craig Burton: Right. They've come up with a product that builds infrastructure that supports the commoditization of Linux in a way that is significantly more advanced and architecuturally sound than what anybody else is doing. They're raising the stakes of what a distro vendor needs to do.
Doc Searls: It's not open source. How is that strategic?
Craig Burton: The reality is that not all of Volution is open source. But it is open-source based,and it's a real strategy. Red hat's service strategy isn't open source either. It's based on Novell's eDirectory, which is NDS running on platforms other than Netware. You pay a monthly fee to Red Hat and they'll manage your directory. eDirectory is not an open source product. I don't see how Red Hat can make it one. Meanwhile they're providing service only for companies using their latest distribution version. What good is something no other Linux vendor can work with? It's the same as not being open source.
Doc Searls: But it's still strategic to the degree that they offer something.
Craig Burton: Their goal is to be THE Linux. If they want to maintain the kind of majority share they have now, they need to differentiate. This is one way. Whether they realize that it's also a lock-in strategy is an open question.
Doc Searls: So you're saying Caldera is more strategic because they're offering a different network service, and doing it in the form of a product a strategy that scales.
Craig Burton: Yes. And I'm saying bravo. This is a bold move. In chess terms, it's a Bobby Fischer-grade opening. It's preposterous to think that a Linux distribution vendor can an industry impact on network management, but I think that's exactly what Caldera has laid out here. This architecture is strong enough, and well-thought-out enough, that it really is an industry-leading move. If it weren't Linux and if it weren't Caldera, a lot more people would be calling it hot stuff. And it may just be that Linux is hot enough, and Caldera is strategic enough, that it really is hot stuff. If it doesn't pan out, it's still what network management is going to be like. Whoever solves the problem of management is going to take this kind of approach, whether it's Linux or not. It's a very cool move on Caldera's part.
Doc Searls: What about security?
Craig Burton: Security is inherent in this. Security and directory are related services. This goes back to the network services model, which says that directory and security are the services on which all the other services have to be based. And right here Caldera has a directory-based secure management infrastructure. That's really strong.
Doc Searls: In that it's independent of any Linux system.
Craig Burton: Right. But it's still only Linux. It only runs on Linux and only manages Linux systems. But it embraces all Linux distributions, and that's very significant.
Doc Searls: How about IBM, which is selling a lot of Linux and declaring itself a Linux Company?
Craig Burton: Their solution is Tivoli, which isn't anywhere near as clean as this. IBM bought Tivoli a while back. They're an object oriented network management solution. They have a lot more stuff than Caldera does in Volution, but Caldera has a more elegant solution because it fosters infrastructure.
Doc Searls: How about companies like Egenera, which are building data centers around Linux (or planning to)? These centers might include Linux and other platforms. They should be looking at this kind of thing, no?
Craig Burton: They should be jumping all over it. Anyone doing widespread Linux implementation should be looking at this as infrastructure. Because there isn't anything better for Linux. Again, unfortunately, it's still only Linux. That's not enough in the larger scheme of things, but it's a huge start.
Doc Searls: Is there anything about Linux that makes it inherently more or less manageable?
Craig Burton: There is no infrastructure in Linux to discover a configuration. So Caldera built one that goes in there and does a hard-wired discovery of the Linux architecture, so it can point back what's there in terms of devices, device drivers and systems. Volution uses that. It's the way they do discovery to populate the virtualization of management. It's tied in with OpenLinux, which is open source. But the agent that does this isn't. At least not yet. Right now they're trying to get out there in front of the curve by providing real management services. This is a valid strength.
Doc Searls: What would be the next steps?
Craig Burton: There are several questions that come up. Who's going to build the Caldera Volution client for other platforms besides Linux? That's one question. And which Linux distributions are going to bundle the Volution client? If it was included with TurboLinux, Volution would automatically find it and begin securely managing it.
Doc Searls: Isn't the client a browser?
Craig Burton: This is where the term "client" gets confusing. There is a Volution management server that is accessible from a browser. In this sense the browser is the "administration" client for Volution. The administration client is used to do things like setup, configuration, and maintenance of Volution. Then there is the actual "management" client. This is a piece of software that enables Volution to manage a Linux platform. The management client is loaded and sits in the background of the Linux system doing its management job. The management client looks for problems, communicates with the server, and executes management functions. Both client functions are secure and require passwords to do things.
Doc Searls: What about LDAP? Will it look at any LDAP directory?
Craig Burton: They're using an LDAP v3 directory, which has a security model. It's far enough along to justify their claim that if you've got a V3 LDAP infrastructure in place you can use Volution. The problem is that what V3 does not define is replication. What's missing with LDAP directory is, one, dealing with the naming problem, and two, that LDAP servers talk to each other.
Doc Searls: LDAP is a protocol. So why, if there's a protocol in place
Craig Burton: LDAP defines only how a client talks to a server. Not how a server talks to a server.
Doc Searls: Critical difference. Can we diagram what's possible and what's not here? If you've got a Volution console, and you're looking at multiple directories, you can do that, because you're a client talking to a server. But
Craig Burton: But there are going to be pockets of disparate LDAP solutions out there even though it is assumed that this is not something you want to do, because it isn't manageable. What happens is you're busy thinking that's not what you're going to do, but it happens anyway. Let's say you've got a company with two geographic implementations of lots of linux distributions with one LDAP directory per location. The one in California uses mostly Red Hat, but also some other Linux distributions, and uses Netscape as its LDAP directory infrastructure. Now let's say the one in Utah has bought off on eDirectory, which is Novell's LDAP directory infrastructure. These two systems can't be integrated as a single managed entity.
Doc Searls: Not yet.
Craig Burton: Not for a long time. Because these servers don't talk to each other.
Doc Searls: You need metadirectory for that.
Craig Burton: That's right. You can't do it without metadirectory. But that's still way downstream.
Doc Searls: But there are metadirectory products out there.
Craig Burton: Sun's iPlanet metadirectory, which used to be Netscape's, tries to figure out how to reconcile the vendors that bought their own different LDAP directories. How do you integrate those different name spaces? They have to talk to each other, even though they have different schemas and naming practices. They don't match. Between them you have breakdown. The problem is the same as if one directory wasn't LDAP.
Doc Searls: So LDAP is necessary but insufficient.
Craig Burton: Yeah. See, I can look, though LDAP, at two different islands, but I can't look at them together. Any LDAP client can look at any LDAP directory on any LDAP server, but each creates its own island. The servers are not integrated.
Doc Searls: So for now it can't be done.
Craig Burton: Sure it can be done. Go buy Microsoft's metadirectory. It does exactly that.
Doc Searls: This is Zoomit's VIA, which Microsoft bought a few years ago, and which had as its charter a policy of including all directories regardless of vendor, naming convention, schema or anything else.
Craig Burton: Right.
Doc Searls: So if I have a multi-platform shop already running Windows 2000 server, I can buy VIA, put it on the server and combine multiple LDAP directories.
Craig Burton: Right. But if you're a customer who's trying to follow orthodox Linux policies, you can't.
Doc Searls: But if you're all open source, you're not even running Volution.
Craig Burton: That's right. If you're in an all open source environment, you're hosed for management. There is no management infrastructure in an all-open-source solution today. Certainly nothing like Volution.
Doc Searls: But Volution may be politically acceptable because it comes from a company that's committed to opening everything it believed it can, and still stay in business.
Craig Burton: Right. Look: people have always been paying for software. Companies vendors and customers alike need to have an open source strategy because only open source is going to create ubiquitous infrastructure. The question isn't just, What should be open and what shouldn't?, but, How do we generate both ubiquity and shareholder value? Caldera has a strategy for that. So does Red Hat. They're players. You have to have an open source strategy to play today. That has become a very clear reality. What remains fantasy is the idea that everything has to be open source. But that's an absolute idea that has no opposite. Open source advocates have done a very good job of selling the value of open source. But there isn't enough pudding in the commercial space to prove it, and there never will be. Caldera is living with this problem right now, and doing a very careful job of moving everything it can into the open source space, which creates ubiquity, while they come out with products like Volution, which drive shareholder value and happen to be closed source.
Doc Searls: That's why they put OpenSLP out there as a protocol.
Craig Burton: Right. That creates ubiquity because it's something everybody can use tomorrow. Microsoft did the same thing with SOAP.
Doc Searls: Which they created with other companies.
Craig Burton: Sure. But it's still an open source strategy.
Doc Searls: And we're still new to all this.
Craig Burton: It's still a new world. What's ubiquitous about that world is full of open source stuff. But it also has to be a world where business can thrive. Can you do that entirely with closed source software? Not if companies are going to make money at it.
Doc Searls: If we look at what Richard Stallman wrote in the GNU Manifesto, one business idea behind a free operating system was "remove operating system software from the realm of competition." He says, "You and they will compete in other areas, while benefiting mutually in this one.... GNU can save you from being pushed into the expensive business of selling operating systems." Maybe managing multiple operating systems is one of those areas.
Craig Burton: Let's go at it from this direction. There are those who think that Linux' role is to take over the client, and be big contender there. God bless 'em. That's not what I'm talking about. The fact is, Linux already is a contender as a platform for infrastructure. No, it's beyond that: it is infrastructure. Period. Today. However, it's an infrastructure commodity. So those who are in the business of supplying that commodity need to put a stake in the ground about the next piece of infrastructure they're going to provide that's based on Linux. We have exactly two vendors in the Linux community who have driven those stakes: Red Hat with service and Caldera with management. Red Hat offers exclusive service based on eDirectory which is a form of NDS: a directory from Novell. Caldera offers Volution, which is an agnostic management system that works with all kinds of Linux systems, including Red Hat's. Now: which one is more strategic, more long-term and better for the industry and an evolutionary leap? It sould be Caldera.
Doc Searls: Isn't Red Hat just doing what it can until it figures out something better?
Craig Burton: Sure. But in doing service, they are trying to figure out how to do standards-based, directory-enabled service. Not services. That's it right there. Huge difference.
Doc Searls: This has all been very much on the positive side for Caldera. What's the down side? Is there anything wrong with Volution as it now stands?
Craig Burton: The Volution object model is homegrown and not a long-term approach. I think they should use The Desktop Management Task Forces (DMTF) Common Information Model (CIM). The Linux community is very resistant to CIM because Microsoft is fully committed to it. The community wishes there was an alternative, I dont see one. Trying to force another object model into play is a waste of time. But politics are still likely to muck this up. I also think they need to support other platforms besides Linux, either themselves, or through partnerships. This product calls into question whether Caldera intends to be in the infrastructure busienss or in the management business. It's one thing to provide infrastructure on which everyone builds or to put applications on infrastructure. Sooner or later they'll have to choose. I think they should stay in the infrastructure business.
Doc Searls: Doesn't Volution put them in both?
Craig Burton: It's mostly infrastructure with a a start on management applications: inventory and application distribution, hardware and software inventory, health monitoring, Linux printer configuration and management. These are separate applications that come with Volution. There's no help desk, no trouble ticket. The question is, are they going to partner with somebody to create those things or do it themselves? I think they should partner.
Doc Searls: Why shouldn't they add more value to what is clearly a product?
Craig Burton: It's not that they shouldn't. It's what works best both for them and for the industry they're serving. The infrastructure strategy is in alignment with their roots. It's not a big leap going from Linux to management infrastucture. It is a big leap to go from Linux to managment applications. It's a very different business. They'll probably need to walk a fine line here. A Linux vendor selling network management to the enterprise is a new concept and they're pushing the envelope with it.
A lot of Great Stuff goes out over the broadcast radio bands, but it's rare that you're actually in a position to hear it. I have solved this problem with various systems to record radio broadcasts to cassette tapes. My starting equipment was a boom box and a hardware-store AC power timer switch, later updated to a fancy stereo tuner and a slightly nicer timer switch. Some stereo tuners have an 'instant on' feature which remembers what radio station they were set to when they were turned off, thus allowing you to hook a tape drive to them and turn them on through the power cord. All of these approaches suffer from several drawbacks. Hardware-store timers work only in 24-hour cycles, so if you want to tape a show at 8pm Saturday and another at noon Sunday, you must reset them between days. More expensive timers feature interfaces which are very difficult to learn and manipulate, limiting their usefulness. It is also difficult to keep these timers precise; they're really not built for that purpose. In addition, you can only turn the radio on or off with them. You must also be sure to get the thing tuned to the right channel. Every step you do to catch a radio broadcast increases the chance that you will make a mistake and miss the show.
The obvious solution to this problem is to use a computer to control both radio and tape deck, setting times and channel tunings through it. The ideal way to have this work would be to have a single device with a radio, a computer, and a tape deck all tied together inside, along with a clean, simple interface to control them all. In the real world, there's probably not enough crazed radio listeners to justify designing and manufacturing such a thing. But it's still possible to hook all these things together. With Linux, an old PC, and a PC radio card, you can build a device to hang off your home network which will be simple to operate and let you listen to some Really Cool Stuff for less than $150.
The system I built started with a '486 DX 66 PC with a 1.5 GB hard disk and 16 MB of RAM, which I obtained in exchange for a 6-pack of good homebrew beer. I could have done only a half-gig of drive space. To this I added a PC Cadet radio card (about $40), a CM17A 'Firecracker' X10 control module (I got mine free in a promotion), the tape deck (bought used from a friend), an X10 radio transceiver module ($20 or so), and some audio cables. The tape deck must have a 'record on' feature, so that you can force it to begin recording immediately when you supply it power. The audio cable has a miniature stereo plug on one side, and a pair of RCA plugs on the other. Most audio stores sell these for plugging portable CD players into room stereo systems.
The first step in building the radio timer is to attach all the hardware you'll need to the PC. Plug the PC Cadet radio card into an available ISA slot. Plug the CM17A "Firecracker" module into one of the serial ports on the back of the PC. The CM17A needs a DB9 connection; if you have only the larger DB25 serial port on your machine, you'll need an adapter. The CM17A features a pass-through DB9 port on the outside of the device. Reports are that this works well if you need to plug another device into your box's DB9 port.
It's best to run your radio listener server "Headless" (with no monitor or keyboard) on a network. This way, you can work with it from somewhere else in your house, and you won't have to power a monitor which you'll seldom have reason to read. The only thing actually travelling over the network will be text, so you can use a 10BaseT card to connect the server to your network. Try to find a PC with a BIOS up to date enough to include the option not to test the keyboard on boot if you go this route. Even though you won't be using it, your radio server will need a video card in order to boot properly. Access to a parts pile comes in handy here, since even an old 'Hercules' black & white video card will serve well for this.
I first installed the Debian 'Potato' release of Linux on my PC (of course, I had a monitor and keyboard attached for this task). The installation was straightforward, and the release CDs had all the drivers I needed. Installing Linux is outside the scope of this essay; if you need help, The Linux Installation HOWTO is as good a place as any to start. You need not install X-Windows or any of its support files, since you'll be talking to the machine over your network rather than running an X server on it. This cuts down the pain of installation by a good bit. It is best to avoid dual-boot or floppy-boot configurations if at all possible for a server like this, since with no monitor it is difficult to tell what is happening if the machine will not come up far enough to talk to the network. I chose to put C and Perl on this server, although they are not strictly necessary for what I am doing on it now. They will help if I later decide to experiment with browser-based configuration or want to use the server as a general-purpose X10 server machine.
Another useful trick on a server like this, controlled from your network and inside your firewall, is to make /sbin/shutdown runnable from an unprivileged account. On a multi-user system, you should not do this for security reasons. But if you are the only user of your Linux box, changing /sbin/shutdown this way makes it possible to shut down from any of the accounts on which you happen to be logged in. The way to do this is with the chmod(1) command. Log in as root, then type
chmod +s /sbin/shutdownThis also allows you to use one user cron file to control the machine, which simplifies setting it up and making it work.
The first step in putting together the radio listener server is to get the computer to control a broadcast radio receiver. I used the PC Cadet radio card for my receiver, although several other radio cards also work with Linux. Linux 2.2 controls the 'Cadet' radio card, as well as several other types of cards, through the Video4Linux drivers. Setting the card up is a 4-step process. First, you must use the pnpdump(8) utility to create an isapnp parameter file and edit this file appropriately. See the Plug-and-Play-HOWTO for detailed instructions on configuring isapnp devices. I was able to work this step out from the man(1) pages on isapnp(8) and pnpdump(8) without too much difficulty. The PC Cadet radio card will give back the ID string "ADS Cadet AM/FM Radio Data Receiver V. 1.4". The pnpdump(8) program will also show what the base IO address of the card is; chances are this is 0x200. After you have successfully modified the output file from pnpdump(8) and fed it to isapnp(8), you can load the "videodev" driver into memory with insmod(8). Then, load the "radio-cadet" module with an argument of "io=number", where number is the Cadet's base IO address as given by pnpdump(8). You must next configure the "/dev/radio0" device at 81,64 with mknod(1). Finally, install the fm program to talk to the radio card through your new device. You now have a broadcast radio receiver controlled by your computer. The PC Cadet radio card has only a single "line out" jack, so you will need a portable boom box with a "line in" and your audio cable to verify that everything is working correctly. Plug the boom box's "line in" into the radio card's "line out", switch the box to "Line" mode, and you should be able to make broadcast radio come out of it from your command line. After you've satisfactorily performed the device configuration steps, you can make sure they happen at every boot by placing the modified output file from pnpdump(8) in /etc/isapnp.conf and the appropriate modules and arguments in /etc/modules.conf.
At this point, you have a computer which can play broadcast radio on the channel you want. The next step is to make it able to control the tape deck, so you can capture the output of the radio receiver. That is the job of the CM17A 'Firecracker' X10 module. Making the CM17A work is simpler than setting up the radio card. Make sure that you have the drivers for the serial ports loaded correctly (this should have been taken care of when you installed your system). You can then install the "br" program (available in the the Debian package repository, although you will have to hunt for it under "stable/electronics/bottlerocket"). and use it to determine which serial port you have the CM17A plugged into. The simplest way to test it out is to plug a lamp into your X10 transceiver module, then try to control it from the command line with the "br" program. Once you know which serial port you are working with (there are most probably only two you need worry about),create a softlink to the correct device with ln(1) called "/dev/firecracker".
You address X10 devices with both a 'house code' and a device sequence number. I am already using X10 to control some lights in my house, so I used a housecode different from the one on my light controllers on the X10 transceiver connected to my cassette deck. This also makes for easier administration if you decide to control other X10 devices from your Linux box. The X10 controller used for lamps is unreliable when connected to a radio or other electronic device; it is best to use an "appliance module", which contains a relay rather than a solid-state switch, for these kinds of devices. Fortunately, the X10 transceiver has a relay of this kind, so if you're only using X10 for this one thing, you're OK here.
The best way to set the other server software up is to centralize everything to do with timed radio reception under one user ID. I have a "Radio" user which holds the script, crontab(1) files, and other application files I need to run the radio. If you're setting this up on a box you use for other things, this is a necessary step. Otherwise, your head will explode from complexity when it's time to back up or modify your machine.
After you have proven that the CM17A and the radio card work separately, try assembling and testing the whole system. The PC will get power from the wall. Plug your tape deck into the X10 transceiver and thence into the wall, and run the audio cable from the PC to the tape deck. Connect the PC to your network. Make sure that the tape deck is set to record when it's powered up, and you should be ready to go.
When you are finished, the hardware should be connected together like this. 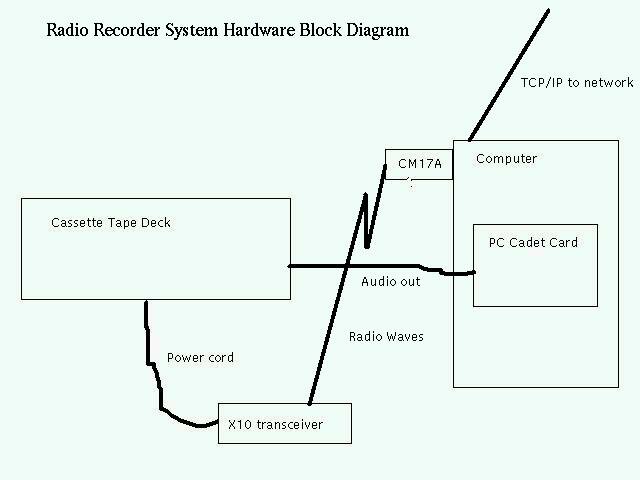 You should now be able to turn the tape deck on in record mode from a telnet session on your server, then turn the radio on in the same way and watch the LEDs on your deck move as broadcast radio sounds flow onto your cassette tape. Take the tape over to your stereo and play it to verify you are really getting what you should. You'll probably have to twiddle some knobs on your cassette deck to get the levels just right. I also installed a fancy powered antenna on the PC radio card to improve FM reception; you may not need to do this if the radio stations you're interested in are strong enough in your area. I favor 120 minute cassettes for this kind of listening, since few radio shows last more than an hour. You may find that audio quality is better with shorter tapes.
You should now be able to turn the tape deck on in record mode from a telnet session on your server, then turn the radio on in the same way and watch the LEDs on your deck move as broadcast radio sounds flow onto your cassette tape. Take the tape over to your stereo and play it to verify you are really getting what you should. You'll probably have to twiddle some knobs on your cassette deck to get the levels just right. I also installed a fancy powered antenna on the PC radio card to improve FM reception; you may not need to do this if the radio stations you're interested in are strong enough in your area. I favor 120 minute cassettes for this kind of listening, since few radio shows last more than an hour. You may find that audio quality is better with shorter tapes.
After you've gotten your pieces to work together, you'll need some way to automagically kick off the radio on the appropriate times and channels. Linux comes with a marvelous system program called cron(8), which provides timed execution of scripts. All you need to do is set up a set of crontab(1) entries for your radio user which will set the radio channel and turn it and the tape deck on and off when your favorite shows come around. You could go nuts here, with a really cool web-based interface,a perl script to do the controlling and another CGI script to edit your crontab file, and all kinds of slick amazing bells & whistles. To just make it work, I used bash(1). The script I came up with is short, simple, and to the point:
Text version of this listing
#!/bin/bash
#################################################################################
# Very first shell script to control radio. Very crude.
#
# Charles Shapiro Dec 2000
################################################################################
LOGFILE=/home/radio/radio.log
BREXEC=/usr/bin/br
FMEXEC=/usr/local/bin/fm
echo ------------------ >> ${LOGFILE}
date >> ${LOGFILE}
${BREXEC} -c b -n 1 >> ${LOGFILE} 2>1
${FMEXEC} $1 65536 >> ${LOGFILE} 2>1
echo Sleeping $2m.. >> ${LOGFILE}
sleep $2m >> ${LOGFILE} 2>1
${FMEXEC} off >> ${LOGFILE} 2>1
${BREXEC} -c b -f 1 >> ${LOGFILE} 2>1
date >> ${LOGFILE}
echo ------------------ >> ${LOGFILE}
The logfile is a necessary refinement; many subtle errors can creep in when you are setting up cron jobs, and it is a great debugging help. For example, I found it necessary to explicitly specify the path to each executable I used in this script, lest the programs not get found when it ran under cron(8). This results in an hour of empty tape if the "fm" program doesn't run, or the radio playing into a dead tape recorder if the "br" program fails.
Use crontab(1) to set the cron file you'll use to tune your radio. Mine currently looks like this:
# # Crontab file for radio # # Charles Shapiro Dec 2000 # # Prairie Home Companion 00 19 * * Sat /home/radio/radiofirst.sh 90.1 70 # Industrial Noise 00 00 * * Sun /home/radio/radiofirst.sh 91.1 70 # My Word 00 12 * * Sun /home/radio/radiofirst.sh 90.1 70 # Locals Only 00 19 * * Sun /home/radio/radiofirst.sh 99.7 70 #Shutdown after weekend 00 21 * * Sun /sbin/shutdown -h -y now # Commonwealth of California 00 10 * * Wed /home/radio/radiofirst.sh 88.5 70 # Between the Lines 30 19 * * Thur /home/radio/radiofirst.sh 90.1 40 #Shutdown after mid-week 00 21 * * Thur /sbin/shutdown -h -y now
Your crontab(8) will vary, since this is the place where you record your taping choices. The 'shutdown' lines in this crontab file bring Linux down gracefully from my 'radio' account, so I can turn the machine off from the power strip when it will be idle for a few days. Without them, I would have to fire up another machine and log in to manually shut the system down. Setting the /sbin/shutdown program's privileges to allow a non-privileged account to run it allows me to keep everything in the radio account's crontab(8) file, so it's easier for me to understand what will happen when. Of course, if you're not so stingy as I am, or if you want to listen to more different things, you may choose to leave your radio server on all the time. My choice here means that I must remember to turn the server on again on the days when I will be taping.
A real 31337 7190X HAX04 D00D would do all this on a 'diskless' PC, running everything from a couple of floppy drives with LRP (the Linux Router Project) or another one of the tiny Linux distributions. I've already made that approach work on this project, so I may eventually tear the drive and SCSI controller out of my radio listener server and use them on another machine.
Given that we already have the hard drive there though, one good refinement would be to improve the user interface. I could run apache on the box and create a CGI script connected to a browser form to make it easy to change what radio stations it will listen to and when. Another possible direction is to create MP3 files instead of tapes, but this would depend on a sound card in the PC and an MP3 player in my car, neither of which are on the horizon (the current radio PC is out of slots). I've also thought about daisy-chaining tape decks to the Cadet's 'audio out' cable and connecting them to different X10 appliance controllers. This would make it possible to go longer without swapping tapes, so I could tape more than one show without being physically present. The video4linux spec also allows more than one radio card to reside in the same machine, so you could modify this setup to tape more than one show at the same time. Another great thing would be to attach a CM11A X10 controller to the radio PC's remaining comm port and power strip. These devices have independently programmed timers, so that the PC could tell the CM11A to wake it up in a couple of days and then shut the power off to itself. This would mean I would not have to remember to hit the power strip switch every couple of days. A less elegant solution would be to use one of my old hardware-store timers which I have lying around the house for the same purpose.
This kind of application is one place where Linux can truly shine. Cheap, single-purpose servers which do one thing extremely well are a good extension of the original Unix and Linux software philosophy of simple parts glued together for complex behavior. This project would not have been possible with an expensive, GUI-based operating system such as OS/2, Windows, or BeOS. Doing it with MS-DOS would have involved an extensive development effort on the application side, even assuming you could find or write drivers for the radio card and CM17A.
In this article I want to show you a few things you can do with a $50 TV card under Linux. This article expects you to know how to compile the kernel, and how to install general application on Linux. I will not get into too much detail, but for each section there are plenty of documentation available on the web for you to study and learn.
This last week I had a blast setting up a Pinnacle Studio PCTV on my Linux box. You can get this TV Card for about $50 on most online computer stores.
First, let me give you my settings:
1 GHz Athlon
256 MB of RAM
60 GB HD
VIA 97 Sound Card
Nvidia TNT2
Running Red Hat 7
Kernel 2.4.1
Xfree86 4.0.2
Pinnacle Studio PCTV
Here is what you need:
1. Sound working under Linux.
This can either be accomplished by running /usr/sbin/setup (under Red Hat systems) or by manually loading the sound drivers with /sbin/insmod.
I also would suggest that you take a look at http://www.opensound.com if your sound still doesn't work under Linux, and you have tried both previous procedures.
2.Kernel configured to support bttv driver (http://www.strusel007.de/linux/bttv/)
With the original kernel 2.2.x that comes with Red Hat, your bttv drivers should already be in place, compiled and ready to go.
If you need to (re)compile 2.4.0, you need the following options activated.:
� Under Character Devices-> I2C support, turn on I2C support, and I2C bit-banging interfaces
� Under Multimedia Devices, turn on Video For Linux, and under Video For Linux, set BT848 Video For Linux as a module.
Feel free to add anything else that you need, but for help, read the kernel documentation.
After the kernel has been successfully compiled, and its modules, reboot your machine, and run /sbin/insmod bttv. If no error pops up, you should be all set.
So, now we need an application to interface with the TV drivers.
3. xawtv
Download this app at: http://www.strusel007.de/linux/xawtv/index.html
Nothing too exciting here, download it, untar it, then:
� ./configure
� ./make
� ./make install
Note: The only error I have seen this application give me, is that it will not work if the there is something wrong with your: /etc/X11/app-defaults/ directory or path.
3.1. Running xawtv:
To run xawtv, on your Xterminal just run xawtv, it will pop a screen with good old fuzzy TV noise will show up (assuming that you have gotten all the previous steps right, and your TV card is installed :-D).
You can right click on the TV screen to get a menu where you can do all sorts of things to the application. To know more about how to configure this app, just read the documentation included with it (It is pretty good).
With xawtv, you should be able to plug in your cable, regular antennas, and watch TV on Linux, or even a VCR/DVD and watch your favorite movie.
4. Running Sega DreamCast on your Linux box.
If you have gotten all the last 3 steps done right, you now, can bring in your Sega DreamCast (or whatever other video game console you have), and plug it in to the back of your TV card, play video games via xawtv.
My Settings:
To get mine running I basically, plug the Video output of my Sega DreamCast into my Composite Plug on the back of my TV card, and I went to Radio Shack and paid $2 for a adaptor that allows to plug my Audio (L/R) output of my DreamCast directly into the Line-In plug of my sound card. The reason I did it that way? It saved me $20, this way I don't have to buy Sega's RF Adaptor. You are also welcome to just plug in a VCR into your TV card, and your DreamCast into the VCR.
5. Creating Real Video on Linux
Now, this was the most exciting part of them all for me, and probably the one that took me the longest to get it going. First of all download the Real Producer Basic from: http://proforma.real.com/rn/tools/producer/index.html (Note: Real Networks is always changing their products' URL, if this URL stops working, just go to http://www.real.com and search for the Real Producer Basic).
After going through the installation process, go to the directory where you just installed real producer (in most cases: /usr/local/realproducer-8.5), you can run something like this:
[root]# realproducer -o /tmp/testing.rm -t 7 -a 3 -v 0 -f 0 -b "Testing Video" -h "Anderson Silva" -c "Personal" -vc RV300 -l 2:1,8:1
On the example above, I am capturing video straight from my TV card, and encoding it to Real Player 8 and saving it under /tmp directory as testing.rm.
Command Line Options:
-t Target Audience (e.g. 7 is for Cable bandwidth)
-a Audio Format (e.g. 3 is for Stereo Sound)
-v Video Quality (e.g. 0 is for Normal Video)
-f File Type (e.g. 0 is for Single Rate Video)
-b Video Title
-h Author Information
-c Copyright Information
-vc Video Encoding (e.g. VC300 for Real Player 8, VC2000 for Real Player 7)
-l audio, and video devices (e.g. 2:1 grab audio from Line-In output, 8:1 grab video from Composite output on TV Card).
This is just a fraction of the command line options for the realproducer. You can read more about them running ./realproducer �help or by reading the documentation that comes with it (usually stored at /usr/local/realproducer-8.5/help/producer.htm)

Other TV Cards:
In theory, the following cards are also suppose to work: STB TV PCI, Diamond DTV2000 (*), Videologic Captivator PCI, AVerMedia TV-Phone (*), Osprey-100, IDS Imaging FALCON.
|
|

|
ScopedBrowser openBrowserForArticle4
You'll notice that there are seven categories available, including MakingSmalltalk-Article2. If the Person class exists, it should be in this category. Left-click on the Person class, then middle-click>Remove. You'll get a confirmation dialog, click yes in this. You'll see now that the category MakingSmalltalk-Article2 is empty.
Now, to first declare our Person class, in the ScopedBrowser, left click on the MakingSmalltalk-Article4 category, you'll see the code pane displays a nice class template for you. It's pretty straightforward:
Object subclass: #NameOfClassDon't worry about what a pool dictionary or class variable is, just edit this template such that it looks like:
instanceVariableNames: 'instVarName1 instVarName2'
classVariableNames: 'ClassVarName1 ClassVarName2'
poolDictionaries: ''
category: 'MakingSmalltalk-Article4'
Object subclass: #PersonThen middle-click>accept. You'll notice that the Person class has been added to the article 4 category. Now lets add a method, the first method we discussed in article 2 was sing.Right-click>new category...>new... in the method categories pane, and type in: Singing as the method category name, then click on the Accept button. You'll notice that the code pane gives you a nice method template:
instanceVariableNames: ''
classVariableNames: ''
poolDictionaries: ''
category: 'MakingSmalltalk-Article4'
message selector and argument namesCopy over this method template with our sing method, then right-click>accept.
"comment stating purpose of message"| temporary variable names |
statements
singYou'll notice that the sing method appears in the method category Singing. You can now go to a workspace, and do: Person new sing, and the bad impression will appear. For the read-along folks, the browser looks like:
(Workspace new contents: 'Do be do be doooooo.') openLabel: 'A bad impression of Sinatra'.
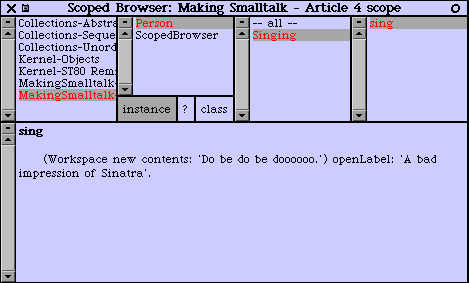
Now the next method we discussed was sing:, and it could take a parameter: 'MaryHadALittleLamb'. You can see the obvious difficulty with our first sing method - the song and label are hard-coded along with the activity that we're doing. It'd make more sense to have one method that knows the activity we're doing (singing), and be able to have it accept parameters from various methods to simplify/reuse our code. That way, if we need to change how the singing is done in the future, there are less spots to update. Lets make a new method (remember, we're denoting private methods with a 'my' prefix) that isolates how we're doing the singing from what is being sang:
[ex1c]
mySing: someLyrics withTitle: aTitleThen, lets refactor our first sing method to reuse this private method, just copy right over the sing method or edit the text directly and accept it:
(Workspace new contents: someLyrics) openLabel: aTitle
singNote that we still have the song lyrics and title hard coded in the sing public method, so they're not directly accessible by other objects or methods of Person, but it is better than it originally was. We'll show a better way to organize your code when we do our next song, and illustrate how factoring out the song lyrics can be useful. With this in mind, lets create a lyrics method for our next song:
self mySing: 'Do be do be doooooo.' withTitle: 'A bad impression of Sinatra'
maryHadALittleLambLyricsNow we can add our sing: method that reuses our private mySing:withTitle: method. It has some very simple logic that defaults to our bad impression if we don't understand what is being requested to sing. Note: when we ask aSong if it's equal to 'MaryHadALittleLamb', a boolean object is returned (true or false), and then we ask the boolean object if it's true or if it's false.
^'Mary had a little lamb, little lamb, little lamb, Mary had a little lamb whose fleece was white as snow.'
sing: aSongRemember, as soon as you add a method, you can execute it if you like, since no compile-n-link-n-run cycle is needed. Finally, lets add our last public singing method, which is similar to the above method:
aSong = 'MaryHadALittleLamb'
ifTrue: [self mySing: self maryHadALittleLambLyrics withTitle: 'Mary had a little lamb']
ifFalse: [self sing].
sing: aSong andDoIt: anAdjectiveWhich assumes another private method, which builds on our first private method. You can see how having the lyrics factored out into a separate method is useful, as we can access them as needed to sing loudly (uppercase) or quietly (lowercase).
aSong = 'MaryHadALittleLamb'
ifTrue: [self mySing: self maryHadALittleLambLyrics inManner: anAdjective withTitle: 'Mary had a little lamb']
ifFalse: [self sing].
mySing: someLyrics inManner: anAdjective withTitle: aTitleI'm leaving out the whatIsMyHeight method, as it's just more of the same of what we've covered. Note the simple conditional logic that we've used here. This is something that can be avoided by programming methods like double dispatching, but that's beyond the scope of this article. Avoiding conditional logic is often cited as one of the benefits of OO programming. To illustrate, image that we have 30 different songs that we needed to sing, this would lead us to have 30 different ifTrue statements, or a CASE statement (most Smalltalks don't even have a CASE statement) with 30 cases. Then if we needed to add 5 more songs, we'd need to track down all the places where we used the 30 cases and add our additional 5; chances are there's more than one place where there are these 30 cases, and you'll eventually have problems keeping all the cases in sync. For simplicity though, we're using conditional logic for illustrative purposes.
"Using simple logic here for illustrative purposes - if the adjective is not 'loudly' or 'quietly' just ignore how we're being asked to sing"
| tmpLyrics |
anAdjective = 'loudly'
ifTrue: [tmpLyrics := someLyrics asUppercase].
anAdjective = 'quietly'
ifTrue: [tmpLyrics := someLyrics asLowercase].
self mySing: tmpLyrics withTitle: aTitle
self halt.
self mySing: 'Do be do be doooooo.' withTitle: 'A bad impression of Sinatra'.
Then ask your person to sing by doing: Person new sing, you'll see the debugger:
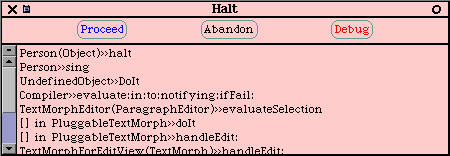
Click on the Debug button, and click on the 2nd method on the method stack. For the read-along folks, you'll see:
Now, you can delete the self halt., then middle-click>accept - at this point your code is updated such that any requests to the sing method get the new version. Now you can continue execution by moving your pointer over the top pane, and middle-click>proceed
This can be a very powerful way of programming/debugging your code. Remember, the debugger is your friend - many new Smalltalkers don't use the debugger to it's full advantage because the compile-link-run cycle is so ingrained. Following this model, you use the debugger to step in and over code until you see the problem, then you close the debugger and go back to your browser to make the code update, then try running the code again. Why not just make the code update while you're in the debugger and continue on your merry way!? Another very powerful technique can be to insert a breakpoint in a troublesome part of the code, then manually change the live objects to simulate various conditions to help you debug (scribbling temp values for different scenarios on scaps of paper can become a thing of the past). Sometimes it is necessary to begin execution from the start because the context will be so different, but more times than not you can just fix things right in your debugging session.
Base Classes
The base Smalltalk classes that you start a clean image with. For example, Object, Boolean, Magnitude, Stream, etc. Though you can (and sometimes need to) do base class changes, it's generally not advised as it's very easy to mess up the image or to break forwards compatibility.
Namespace
A namespace is much what it sounds like - a finite space that names can be defined and identified in. For example, if you're writing a program and you wanted to define a class called Object, you'd be out of luck as the class Object already exists. If you were able to define a second class called Object, how would the computer know the difference between the two? In most Smalltalks there is a single namespace (VisualWorks Smalltalk is the notable exception).
Namespace collision
When two companies/groups/people try to name thier classes with the same name, or define methods off of a class with the same name. To help avoid namespace collision not only within your own projects, but from other companies like third party vendors, it's a common practice to prefix your classes with some acronym, for example, if you work for MegaCorp you might prefix all your classes with 'Mc'
Refactor
To change/update/reorganize your code to make it (hopefully ;-) cleaner, faster, more robust. Refactoring typically moves around responsibilities and/or makes larger methods into smaller methods.
[2] Well, this isn't technically true. As in many other parts of this series I'm making a simplifying statement/assumption. To be more clear, for the purposes of beginners it simplifies things to consider Object the root object of Smalltalk.
To be more precise, Smalltalk has an elegant method for bootstrapping its class hierarchy that's rooted in meta classes and circular definition. If you don't understand the next sentence, don't worry because typically it's nothing you need worry about for regular Smalltalking. Briefly, in Squeak there's actually a class called ProtoObject that is the super class of Object, and ProtoObject inherits from nil - the sole instance of UndefinedObject, which inherits from Object. Other Smalltalk flavours have something similar to this.
 Eric KastenJon MeekBen OkopnikCharles ShapiroAnderson SilvaJason Steffler
Eric KastenJon MeekBen OkopnikCharles ShapiroAnderson SilvaJason StefflerMichael Orr
Editor, Linux Gazette,








 The Mailbag!
The Mailbag!