


|
|
|
|
Our sponsors make financial contributions toward the costs of publishing Linux Gazette. If you would like to become a sponsor of LG, e-mail us at .
|
 The Answer Guy The Answer Guy |
 |
 The Weekend Mechanic |
TWDT 1 (text)
TWDT 2 (HTML)
are files containing the entire issue: one in text format, one in HTML. They are provided strictly as a way to save the contents as one file for later printing in the format of your choice; there is no guarantee of working links in the HTML version.
Got any great ideas for improvements! Send your
This page written and maintained by the Editor of Linux Gazette,
Write the Gazette at
|
Contents: |

We're back in business after a one month gap--no November issue--and we need articles from you.
So, all you budding authors and Linux users out there, send me your material. Don't depend on our regular authors to fill the gap. We want to hear about all the neat tips and tricks you've found, as well as all the neat applications you are writing or working with. We also like to hear how you are using Linux as a workplace solution. --Editor
 Date: Mon, 06 Oct 1997 01:40:46 +0100
Date: Mon, 06 Oct 1997 01:40:46 +0100
From: Emmet Caulfield
Subject: Newbie Stuff
Hi,
I've noticed recently that there's an increasing volume of questions on fairly elementary topics to your help page.
There's probably a fairly large volume of readers, like myself, who correspond with the querants offering help, pointers, and suggestions in the hope that they may be useful. I'm NOT an expert, by any stretch of the imagination, being a recent "convert" of only 10 months vintage.
I think that there is an argument for the Gazette running a series of articles outlining a step-by-step setup procedure specifically targetted at people setting up Linux on home machines connected over the POTS in spite of the fact that this would be duplicating efforts elsewhere (in HOWTOs and such).
Just a suggestion.
I love the Gazette, you have struck a fine balance well - there is something for everyone. I read 22 "cover to cover".
Keep up the good work,
Emmet
Date: Wed, 15 Oct 1997 18:28:05 -0700
From: Todd Martin
Subject: System Back up
I would love to see an article on backing up a Red Hat 4.2 system onto a SCSI Tape drive.
I'm having trouble with it, and am finding information on it rare if not impossible to find.
If anyone could point me in the right direction I would appreciate it.
Or contact me direct if its easy enough to explain.
Thanx
Date: Mon, 13 Oct 1997 21:13:24 -0500
From: "Cochran"
Subject: Article Idea
Hello, I'm a Linux newbie so please forgive any inaccuracies. :) I think someone should report on the Linux game scene. Different projects that are dealing with game projects like GGI and the Linux GDK. Keep the good work up everyone.
Micah
Date: Tue, 14 Oct 1997 18:54:41 -0500
From: Glenn Meuth
Subject: LJ Howto get TECH Info for NEWBIES
I have been reading LJ recently, and I would like to request that an article be written. I have recently had (2) problems which I researched, and only seemed to find dead ends for. I purchased a new computer recently :-) and, as is probably common with such, had some unsupported hardware. This did not surprise me, having worked with computers for some time. So I proceeded to search hardware listings, currently active projects, etc in order to find an answer, and found nothing. (My problem was with my UDMA harddrive controller card from Promise.) I began to email news groups and Promise trying to get the information I needed to write the code for the controller card myself. I could not seem to dig up any help on the subject of support for new hardware. My question: Could you please address an article on how to go about attaining the information necessary to code this? Q(2) Could you also address how to get involved in the linux project?
I have tried to get involved with projects (I am a relatively new C++ programmer (2 years)), in college, and there is little for me to do in my area of the USA in order to exercise my C & C++ skills. If you could help me out here I would appreciate it!
Glenn Meuth
Date: Wed, 5 Nov 1997 04:11:55 -0800 (PST)
From: Ron Culver
Subject: COMMENTS/SUGGESTION
Hi Folks,
First want to say I'm really glad the Gazette is on line... what a great source for finding out new things! Keep up the great work - it's a real winner. Next, want to suggest some needs on this end you might find useful as an idea for a feature. I run a real tiny ISP biz in NM (my hometown, but live in CA) - and have LOTS of questions related to running the system (do sysadmin via telnet) - primarily system security issues, keeping the email system running right, HTTPD (actually run Apache) questions, and DNS issues. What has most plagued me is the lack of a fresh source of info to keep the system on the 'cutting edge' of new developements in software. One example is Java, something that came along shortly after the server was first installed, which I can not seem to get to run properly - and to date no one can tell me why. What I would like to see you try is a column that addresses the questions/concerns of small POP's or ISP's - actually anyone who is running Linux as a server on line would have similar questions/concerns.
Have a nice....
Date: Sun, 12 Oct 1997 02:34:26 +0200
From: Guillermo S. Romero
Subject: Clipboard Ideas
Hello:
I am a bit new to Linux and my programming skills are poor (time solves everything), but I have brain (well, 2 overclocked neurons) and I think that Linux (and Unix) have a problem with "cut & paste", aka clipboard. GPM is fine, xclipboard too, some other systems also work, but its hard to move from one system to another, and not all data can be copied.
I want to start a team to implement a clipboard in Unix, maybe using files stored under something like /tmp/clip/ (or another /dev/foo?). :]
The main thing is that it should be able to work with text, graphics and binary (archives, ie), like other OS do. I think that if we use a system based in /dev/ , the system will support old apps (you only have to save to the correct place emulating an app behaviour, and a demon will convert non standard files to the ones supported by the clipboard). We can even made the new clipboard a multiuser one. Or one with multiple buffers per user (like Emacs, doesn't it?).
If someone is interested, just write. I have a draft so we can start the discussion now. I must admit that my idea maybe look mad or too simple, but that only demonstrates that I believe that usefullnes is directionaly proportional to simplicity. :]
GSR
Date: Tue, 18 Nov 1997 11:10:08 -0500
From: Dan E. Collis
Subject: Adaptec 2940 UW adapter
I am drowning! Have called Adaptec to no avail. They say they're not supporting Linux. Have tried all the loc's on redhat.com that I can find and have had no luck.
Is there a driver available for an Adaptec 2940UW that's good for RedHat 4.2? I'd sure appreciate some help on this one.
Many thanks,
Date: Mon, 10 Nov 1997 12:23:45 -0700
From: Chad Peyton
Subject: PPP
I'm trying to configure a ppp connection. So far the program mgetty has got most things working. I don't know much about Linux, but this is what I think I need to do: get the shell to run the following command.
Puser - - /usr/sbin/pppd auth -chap +pap login kdebug 7 debug
But notice the message I get below when I call in:
Red Hat Linux release 4.2 (Biltmore) Kernel 2.0.27 on an i486
login: chad
Password:
Last login: Fri Nov 7 15:36:54 on ttyS0
Warning: no access to tty (Not a typewriter).
Thus no job control in this shell. It says that the shell isn't working or something. Do I need to get tty working or what? How do I do that?
Also, after I logout the program quits on me. Is there a way to make mgetty keep working after someone hangs up? Also is there a way to make mgetty load at boot time?
Can you help me PLEASE,
Chad
Date: Sun, 09 Nov 1997 00:46:33 -0200 (br> From: Javier Salem
Subject: I need some help
I'm new using Linux but I learn so quicky. I just downloaded Communicator for Linux tar version and did all the installation steps, but I don't understand how to set the environment variable setenv. I think that it's my problem because I can't see Netscape when I open xwin, so I can't use it yet
My name is Javier from Argentina. I 'll be pleased if somebody could give me a hand. Really thanks.
Date: Sat, 08 Nov 1997 09:37:44 -0800
From: Ted Rolle
Subject: Accessing Win95 vfat drive
I've compiled vfat support into my 2.0.31 kernel. How do I mount the drives so Linux can "see" the Win95 partition?
Date: Wed, 08 Oct 1997 13:47:17 PDT
From: "HoonChul Shin"
Subject: Video woes
Greetings to every Linux lover!
When I run XFree86 ver. 3.2 with resolutions more than 640x340, and open menus and move windows around, I see white lines or streaks in my screen. It's very annoying. And when I exit Xwindows, and return to text mode, screen becomes impossible to read. Fonts just become nasty. Is there anyone out there with same problems that I am having now? Video Card= Trident TGUI 9682 with 2 mb.
Thanks!
Hoon Chul
Date: Tue, 11 Nov 1997 12:51:25 +0200
From: Ihab Khoury
Subject: NetFlex driver..
Greetings,
I am trying to install RH4.2 on a compaq Proliant 2500. I have a NetFlex card built in and unable to read it..I saw that few poeple have posted this before ..I was not able to find the driver. Please e-mail me at [email protected] if you have any solutions. Thank you in advance.
Date: Tue, 11 Nov 1997 11:52:48 +0100
From: Sven Goersmann
Subject: scanner driver or scanner codes for RELISYS Infinty/Scorpio VM3550
Hi everybody there!
I just want to ask you if you know there's a Linux scanner driver for the RELISYS Scanner Scorpio VM3550 from the Infinity series, and if so where can I get it.
Thanks in advance, Sven.
Date: Tue, 11 Nov 1997 13:32:34 -0000
From: Roger Farrell
Subject: Emulators
Hi,
I am looking for emulators that support the 8088 and 80188 chips.
lf you can help please reply.
Regards Roger Farrell
Date: Fri, 10 Oct 1997 02:08:44 PDT
From: Gilberto Persico
Subject: Transaction Processing
Have you ever heard of Transaction Processing systems (such as CICS or Encina or Tuxedo) available (free or commercial) for Linux ???
Date: Mon, 03 Nov 1997 19:06:53 +0100
From: Fabrizio
Subject: chat
HI!
I am looking for a chat program for Unix. Can you send to me some tips about this?
Thank you and best regards.
Fabrizio Piccini
Date: Sun, 2 Nov 1997 02:04:28 +1100 (EST)
From: Shao Ying Zhang
Subject: Sorry! - RE: SB16 and MIDI
I am sorry for this second mail; I forgot to tell you what the problem is. OK, the problem is that it plays without returning any errors, but simply no sound comes out.
Thanks very much!
I am using Sound Blaster 16 for my system. My Linux version is Redhat 4.2 with the kernel 2.0.30.
I recompiled the kernel properly (I think) to make my SB16 work. It now can play wave, mod, CD but NOT MIDI.
I can only use timidity to convert them into wave and then play. This means that /dev/sequencer does not work properly.
I have also noticed that a couple of other friends have the same problem.
Could you help me PLEASE???
Thanks in advance!
Shao Zhang
2/896 Anzac PDE
Maroubra 2035
Australia
Date: Wed, 29 Oct 1997 19:51:44 +0900
From: "Chun, Sung Jin"
Subject: [Q] PCMCIA IBM CD-400 Help me.
I want to access cd-rom using my IBM cd-400 PCMCIA CDROM. But I don't know how can I do this. Please help me.
Date: Mon, 27 Oct 1997 14:07:47 -0800
From: "Possanza, Christopher"
Subject: HELP! Possible to use parallel port tape drives with linux?
Does anyone know if it's possible to use parallel port tape drives to backup a Linux system? I've got the HP Colorado T1000e drive, and I'd love to be able to use it... Any suggestions?
Date: Mon, 06 Oct 1997 18:24:12 GMT
From: Harry Baecker
Subject: Word Processing & Text Processing
In his article in Issue 22, subject as above, Larry Ayers indulges in the requisite Unixworld denigration of word processor software and its users, as contrasted with the virtues of software "which allows the writer to focus on content rather than appearance". I suggest that there are some errors in this ritual obeisance to received wisdom.
The first is that all who yearn for the services of a word processor lust to inflict another Gibbon, "The History of the Decline and Fall of the Roman Empire", or Russell & Whitehead "Principia Mathematica" upon the world. Were that so then the world would be more than hip deep in rejected typescripts already. Rather, I, and I am sure most others, wish to prepare snailmail with some attention to personalised format and typography, which is exactly what a reasonable word processor provides. I certainly do not look for the archetypal offense in Ayers' universe of discourse, Microsoft Word for Windows. I have borrowed, used, and rejected that, and I have owned, and given away AmiPro (WordPro) and abhorred Word Perfect since its inception. What I would like to use in Linux is some clone of Wordpad, of MS-Write, or of the word processors included with MS-Works or ClarisWorks, wherein I can govern not only the content but also the appearance of my message.
It is true that Lyx seems to be a reasonable compromise, unless you find, as I do, that the assumptions built into its templates are displeasing to the eye.
The second error is to assume as gospel the correctness of Unix conventions for ASCII text. The ASCII encoding was officially adopted by ISO in 1964. That included provision for the CR/LF pair, and a functional backspace (not left-erase). Anyone familiar with hardcopy terminals of the time, such as Flexowriters, will also remember the joys of "line reconstruction" procedures, to encode, say, lines of Algol 60 program text, in a useful internal representation. Tortuous, but that's what we expect computers to do for us.
The text representation conventions of Unix were born together with the limited representational capabilities of video terminals, character generators with limited repertoires, no "backspace and overtstrike" abilities, hence no way of effecting backspace or CR. By the time proper graphic facilities, and hence font choices, became available the Unix conventions for ASCII text had ossified, and the flexibility actually made available by the original ASCII conventions were treated with disdain. Had Unix embraced the full flexibility offered by the ASCII encoding then things might have been otherwise.
Harry Baecker
Date: Tue, 14 Oct 1997 14:26:20 -0400 (EDT)
From: Paul Lussier
Subject: Thanks!
Hi,
I've been reading the LG since issue 1 when I first stumbled upon John Fisk's web page from an Alta Vista search for Linux info. All of you at SSC have done an unbelievably outstanding job with both LJ and LG, and I just wanted to say thanks. I look forward to the first week of every month when there is a new LG to grab off the net, and a new LJ waiting in my mailbox. I read them both cover to cover each and every month.
I do Unix sysadmin for a living and still benefit from so much of what is originally written with Linux in mind and am able to reuse it on other "Unices" as well.
Also, I just checked out CANLUG On-line magazine. It's not bad. Maybe you people (and the rest of us too) who have done such a terrific job with LG, can give them a hand getting their's off the ground. After all, the whole spirit of the Linux community is helping one another :) And we can all benefit from another on-line, enjoyable source of Linux news and info :)
Thanks again!
Happy Linuxing,
Seeya,
Paul
Date: Fri, 07 Nov 1997 21:05:22 -0800
From: Andrew T. Young
Subject: word vs. text processing
While reading Larry Ayres's comments (mostly quite sound) about TeX, LOUT, groff, etc., I noticed he was sort of behind the curve on *roff.
First, there are several *good* books on this family of text processors. I have troff Typesetting for UNIX Systems by Sandra L. Emerson and Karen Paulsell (Prentice-Hall, 1987), as well as UNIX Text Processing by Dale Dougherty and Tim O'Reilly (Hayden Books, 1987). In addition there is a rather specialized book on the tbl pre-processor called something like "setting tables with tbl" -- I don't seem to be able to lay hands on it right now. (I might add that I consider tbl to be considerably superior to LaTeX's clumsy handling of tabular material.)
After you read these books, it's easy to make up a set of formatting macros that do for the *roff family exactly what LaTeX does for TeX. You can then invoke these very much the way the LaTeX macros are invoked; indeed translation from the *roff to the *TeX markup is pretty easy at that point (though there are a few subtleties that cause problems). LaTeX has a very few advantages for very esoteric mathematical equations; apart from that, the systems are very similar.
Yes, the underlying engine is opaque as hell to figure out; nevertheless, it's powerful and effective. I still prefer *roff to LaTeX, but have been forced to live with *TeX because the journals I use all employ it.
One more historical item: Larry called nroff "newer" than troff, but it's the other way around. Originally, there was some formatter called roff (short for runoff); then came nroff for "new runoff" and then *later* came troff for typesetting. -- Andrew T. Young
Date: Mon, 3 Nov 1997 09:17:40 -0500
From: Jack Chaney
Subject: new_user_setup
Hi,
I too am a relative newbie (again) to Linux but am sold on a lot of the conceptual aspects of the system (shareware, GNU, free downloads, world wide support, etc.) I am also quite comfortable with the stability and security of the OS. I'm not, however, satisfied with the quality of support for new users or "non-experts."
My argument is this, if you are trying to compete in the world market with the IBM's and Microsoft's you need to study what it is that made them so popular in the first place. Availability of applications, which Linux is doing a much better job addressing, is one of the pieces that make them so prominent, but it's only one of the pieces. The popularity of WIN95 in particular is due to the ease of installation of the wanted systems and applications, and the focus on the end user.
In the world of computer users the highest percentage of computers are set up as single user systems linked to a network, or some central server and/or ISP. The majority of documentation material for Linux has done an excellent job of describing how to create and maintain the system as a central server, but very little copy is devoted to running Linux as a client station. Red Hat and others have made great strides toward making the install process as painless as possible (my first install attempt was back in the 0.98 days). I am able to get most of the systems up and running but any time I have questions about a particular package, the files it accesses, and where the files reside, is always viewed as a fishing expedition.
Also a great deal of software gets installed by the standard install process with descriptive text about what the application is during the install (I can't read that fast), with a memo at the end of installation that a list of what was installed can be found in the log directory. When I went to look at the log what I found was a listing of the package titles that were installed (little more than the filename of the RPM file) and no description about what the package does. I found the HOWTO information, but I tend to work better when I can read the instructions from hard copy while I work with the application on the screen. I could (and do) print out the docs I am working with but the expense of this one-of printing is tedious since I spent extra money to get the documentation. It is also particularly annoying because the documentation has highly detailed chapters on how to recompile the kernel (which isn't broken and works just fine) and little more than a paragraph making reference to creating a dial-up client connection to an ISP (which is what most people want).
I am a computer professional who is quite familiar with OS systems and embedded coding and would like to convince management that a Linux-based development environment would be a good new direction for our teams, but it is a hard sell when the response to on-line queries tends to come off as the respondents turning up their nose saying "that information is in the docs" and no clue as to which docs or where. If the respondents know the answer but are tired of answering this question "again" either reprint the old answer, point out where the old answer can be looked up, or answer the question "again," not blow the person off because the question isn't interesting enough. Microsoft and IBM got where they are by taking special interest in always answering the "elementary" questions. I realise the nature of Linux precludes focusing any resources since it doesn't really have any. But if the general Linux public would take a better attitude toward people wanting to join up, and lend a helping hand when possible, Linux could become a major force in the computer industry.
Jack Chaney
Date: Fri, 24 Oct 1997 17:16:04 -0700
From: Felix Liebau
Subject: e mail subscribe?
Hi,
Thanks for that great journal, Linux Gazette, which I really like to read. Can I subscribe to have new issues mailed to me?
Felix Liebau
(No, it is impractical to use e-mail to send such large files as those that make up LG--1 to 2 MB total for each issue. However, check out the Front Page for information about our new notification mail list. --Editor)
Date: Wed, 12 Nov 1997 23:36:43 +0000
From: I.P. Robson
Subject: More Praise
You probably get enough of it. But here's more praise. I've just come accross this magazine and its the most useful and interesting thing I've come across since Linux itself.
Sorry to hear about the November issue but this magazine must be so fundamental to everything that isn't Gatesian that you have to keep on going.
I wish I had a huge bundle of cash to send you, but you'll have to make do with this E-mail instead.
You should have a logo ready to go on every Linux web page everywhere.
I don't often gush with praise and I'd be embarassed if any of my gum chewing friends read this. But you deserve it.
I.P. Robson
--
The goal of Computer Science is to build something that will last at least until we've finished building it.
![[ TABLE OF CONTENTS ]](../gx/indexnew.gif)
![[ FRONT PAGE ]](../gx/homenew.gif)
 More 2¢ Tips!
More 2¢ Tips! Spinning Down Unused HDs
Spinning Down Unused HDsDate: Sat, 8 Nov 1997 18:34:07 +0100 (MET)
From: Philipp Braunbeck
I guess there's no more need to emphasize how much we all like LG. Here's just my humble-newbie-one-and-a-half.
If You're like me and You've been upgrading for a couple of years now You're likely to have several HD's on Your IDE- or SCSI-Interfaces. Now there's probably some GNU-Linux-partition and one or more other partitions with M$-stuff on a separate disk. I've got a 120MB Conner (with actually nothing on it, I use it as a backup-device; it used to be win3.1, but I don't need it anymore :-) which is horribly loud. In the old days of DOS one friend of mine wrote a little Pascal-program which would stop the disk after a period of time, and it would only restart on some (hardware?)-interrupt. Some modern BIOSes can do that job for You, but people told me, that either it doesn't work on Linux (because the BIOS is only used on bootup in order to get some basic configuration) or it is not recommended to do so anyway.
When I was on some adventure-trip through /usr/sbin, I discovered some new species called "hdparm", which should be included on any major distribution. The manual page says that you can use it to spin down any drive on Your system! All You need to do now is putting a line like "hdparm -S1 /dev/hdb" in some boot-startup-script (I guess the filenames differ in different distributions) and You're done. What a silence!
However, You shouldn't do it with Your working /-partition, as it syncs the disk every now and then and the disk will keep starting and stopping, and this is definitely not good for any HD.
If You like my 2-cent just go ahead and publish it. If not, there will certainly be a good reason for this. As I am a newbie, i.e. I've been using GNU/Linux for about one year now, I'm humble enough to admit that this hint seems more than obvious to any experienced user. But if You decide to publish it, I'd prefer that I can stay anonymous, not because I got anything to hide, but because I don't want to pretend to be someone I'm not, like a sysadmin or I dunno. I've got too much respect for them guys who are lots more intelligent than I am, but would they ever consider to mail something as primitive as I suggest to LG? It really is a matter of getting started for unexperienced users, finding that GNU/Linux gets even more powerful while sorting it all out. So just put it in "Clueless at the prompt" or where You like. Sign with Your name, You knew the trick anyway, didn't You?
Finding What You Want with findDate: Wed, 12 Nov 1997 16:14:43 +0000 (GMT)
From: Jon Rabone
In the October 97 issue, Dave Nelson suggests using
find . -type f -exec grep "string" /dev/null {} \;to persuade grep to print the filenames that it finds the search expression in. This starts up a grep for each file, however. A shorter and more efficient way of doing it uses backticks:
grep "string" `find . -type f`
Note however, that if the find matches a large number of files you may exceed a command line buffer in the shell and cause it to complain.
Cutting and Pasting without a MouseFrom:
Date: Wed, 5 Nov 1997 18:58:41 +0100
It is possible, I did think there was no way but there is a way to cut and paste without any mouse. Just use screen-3.6x to achieve what you may have wanted for a long time. you use screen already but did you know how to use this cut-and-paste tool?
This was pasting without leaving your keyboard for a while!
Control-a can be any key to achieve a screen-3.6 command. There are many more very useful features with screen but i guess that like me there are people out there who may not know this very useful feature. Another hint: It is really worth printing the Manual. If like me you are going by train you can read the Manual x. I found out there are so many important features in so many programs I did not know and that did help me a lot after discovering.
About vim and completion: there is a feature that lets you complete words which you did write before which is very, very useful. press control-n in Insert-mode and vim will complete your word if you typed it before. It is even better: You can get vim to complete words that are in a different file. Just tell vim what the name of the file is with :set dictionary=file Then complete the word with control-x-control-k. Now imagine how much easier it may be to get a list of words with a grep command than to write down all kinds of abbreviations and put them into a file. This is a Killer-feature IMO!
About emacs and completion:
Emacs was first with completion or at least this kind of completion mentioned for vim goes back to 1992. What you need is hippie-exp.el which can perform all kinds of completion.
About atchange
There is a very nice script out there written in perl. I like it very much because it lets you perform an action whenever you change the date of a file. The action can be almost anything like calling another program and executing things or whatever you want. The idea came from Tom Schneider who has a page about atchange out there: http://www-lmmb.ncifcrf.gov/~toms/atchange.html
I strongly encourage you to read it, this is an idea, that can really save your time. The perl-script itself is only 68 lines of code. almost one half is explanation, the most important thing is the idea itself but Tom has a good page. So I don't tell you more right now :)
Slow ModemDate: Mon, 3 Nov 1997 17:45:13 -0600 (CST)
From:Michael J. Hammel
To: Larry E Scheib
In a previous message, Larry E Scheib says:
When I access a remote site with Linux my screens paint painfully slowly; a problem I don't experience with Windows95. When my modem connects under Linux it replys "Connected at 38,400", the actual speed of my modem. The modem runs off of cua1, IRQ 3.
I'm not very good at debugging modem connections. I've never really had any problems with my dial-ups except when the network itself is bogged down. To be honest, I have no idea how fast my modem connections are actually running. I just know they're tolerable (they actually seem to run quite fast - I have a 33.6 modem).
Things that might affect this would be:
Finding Strings with findDate: Tue, 28 Oct 1997 16:31:47 +0100
From: Gordon Walker
Being new to Linux I find the Tips section very useful in general and the tip about searching for a string with find inspired me to write my first conditional Bash script. It finds a string in the current or given directory
#!/bin/sh
## Recursively finds all strings in given or current directory
## Usage string_search <dir> <string> (dir is optional)
## For example: "string_search fish " finds string "fish" in current
directory
## and "string_search /water fish " finds string "fish" in directory
/water
if [ "$2" = "" ]; then
find . -type f -exec grep "$1" /dev/null {} \;
else
find $1 -type f -exec grep "$2" /dev/null {} \;
fi
Another Calculator TipFrom: Frank Damgaard
Date: Thu, 23 Oct 1997 22:05:14 +0200 (METDST)
In issue 21 there was a smart perl based command line calculator, here is another one.
I have for some years used a simple alias for the calculator command. The alias only requires awk, and that tcsh (or csh) is the running shell. This alias will not work with bash/sh/ksh since these shells do not allow arguments in aliases.
Just place the following line in your ~/.tcshrc or type at the prompt:
alias calc 'awk "BEGIN{ print \!* }" '
# When calling calc do not escape "*":
# Example: calc (3+5)*4/5
Upgrading a Laptop Hard DiskDate: Fri, 24 Oct 1997 14:38:58 -0400
From: Peter Teuben
I wanted to upgrade the harddisk of my laptop, which had gotten a bit tight with 800Mb and maintaining both linux and W95 (don't ask).
I got a new 2Gb drive, and of course wanted to install W95 as well as linux. I decided, despite my die-hard Slackware, to try RedHat4.2 for linux and basically "copying" W95. Since the laptop is on a local ethernet at home, I could make a backup of W95 on the desktop, and after linux was braught up, restore W95 back over the network. Indeed this worked quite nice, but you have to remember a few tricks. Here were my basic steps:
umount /DOS
insmod vfat
mount -t vfat /dev/hda1 /DOS
Caveat: For FAT32 versions of W95 (from OSR2 or W98) you may need to patch the 2.1.x kernels to include this.
WallpaperDate: Mon, 27 Oct 1997 14:38:35 +0100
From: Roger Irwin
Use netscape, got xv?
Try running this script in your home directory:
rm -f XVbaa for foo in .netscape/cache/* do for baa in $foo/*.gif do echo $baa >>XVbaa done done xv -root -quit -random -flist XVbaa
This will make you a custom wallpaper on the fly by fishing in netscapes cache.
I mapped this to my fvwm2 button bar by using the following lines in .fvwm2rc95:
*FvwmButtons(Title Mood, Icon exit.xpm, \
Action 'Exec XVchange ')
This goes in the FVWM buttons section in the middle of the other lines that define the other buttons.... When I hit the Mood button, the wallpaper changes. I suppose a lazier person might use crontab....
PostScriptDate: Sun, 9 Nov 1997 22:00:31 +0000 (GMT)
From: Ivan Griffin
Counting the Number of Pages in a file
To count the number of pages in a PostScript file, you are relying on the creator of the file to have been a sociable application and to have followed the Adobe Document Structuring Conventions (ADSC). These conventions entail the automatic placement of comments (%%) in the PostScript source so that additional applications will find it easier (and indeed, possible!) to post-process the PostScript without having to interpret it. They are generally ignored by PostScript interpreters and printers. The comment '%%Page:' delimits each new page. So to count the number of pages in a DSC compliant PostScript file, all you have to do is grep for the number of '%%Page:' markers:
grep -c '%%Page:' filename.psI generally tend to alias this to pspage in my .cshrc
alias pspage 'grep -c %%Page:'
Printing 2up
The utility pstops, part of the psutils package, allows you to process a PostScript file to enable 2up printing. I find the following works for A4 (European) paper -- the measurements will need to be tweaked for US Letter:
alias psdouble 'pstops "2:[email protected](21cm,0)[email protected](21cm,14.85cm)"'
To use it, it is as simple as:
psdouble < 1up.ps > 2up.ps
Microsoft Ugly PostScript
Quite often in PostScript generated by the Microsoft Windows driver, it requires the interpreter to have 30MB of memory, and refuses to print otherwise!! This is quite incredible, and I have found that it always seems to print perfectly well if this artifical limit is removed. The PostScript in question is:
/VM? {vmstatus exch sub exch pop gt { [ (This job requires more memory than is available in this printer.) 100 500 (Try one or more of the following, and then print again:) 100 485 (In the PostScript dialog box, click Optimize For Portability.) 115 470 (In the Device Options dialog box, make sure the Available Printer Memory is accurate.) 115 455 (Reduce the number of fonts in the document.) 115 440 (Print the document in parts.) 115 425 12 /Times-Roman showpage (%%[ PrinterError: Low Printer VM ]%%) = true FatalErrorIf}if} bind def 30000 VM?
The line "30000 VM?" checks that (roughly) 30MB of memory is available in the printer. Deleting this line is sufficient to ensure that the check is not performed, and that the job will now print (or be interpreted successfully in ghostview for example).
Linux Virtual Console Key SequencesDate: Sun, 9 Nov 1997 22:00:31 +0000 (GMT)
From: Ivan Griffin
Pressing these key sequences on a VC will dump information to the screen.
Displaying task information:
Ctrl-Scroll Lock gives:
free sibling task PC stack pid father child younger older swapper 0 R current 4096 0 0 1 init 1 S FFFFFFFF 2676 1 0 706 kflushd 2 S 00000000 3984 2 1 3 kswapd 3 S 00000000 3976 3 1 4 2 nfsiod 4 S 00000000 3520 4 1 5 3 nfsiod 5 S 00000000 3520 5 1 6 4 nfsiod 6 S 00000000 3520 6 1 7 5 nfsiod 7 S 00000000 3520 7 1 21 6 bash 8 S 00000000 3012 172 164 711 login 9 S 00000000 2820 164 1 172 166 135 kerneld 10 S 00000000 3224 21 1 76 7 login 11 S 00000000 3012 706 1 712 571 syslogd 12 S FFFFFFFF 3192 76 1 85 21 klogd 13 R 00000000 3404 85 1 96 76 crond 14 S 00000000 3480 96 1 108 85 inetd 15 S FFFFFFFF 3464 108 1 119 96 lpd 16 S FFFFFFFF 3376 119 1 135 108 gpm 17 S 000B206C 3368 135 1 164 119 vi 18 S FFFFFFFF 3012 711 172 mingetty 19 S FFFFFFFF 3012 166 1 167 164 bash 20 S 00000000 3012 712 706 724 httpd 21 S 00000000 3460 573 571 574 httpd 22 S 00000000 3600 574 571 575 573 httpd 23 S 00000000 3308 571 1 579 706 171 httpd 24 S 00000000 3600 575 571 576 574 mingetty 25 S FFFFFFFF 3012 167 1 168 166 mingetty 26 S FFFFFFFF 3012 168 1 169 167 mingetty 27 S FFFFFFFF 3012 169 1 171 168 httpd 28 S 00000000 3600 576 571 577 575 update 29 S 00000000 3460 171 1 571 169 httpd 30 S 00000000 3600 577 571 579 576 vi 31 S FFFFFFFF 3012 724 712 httpd 32 S 00000000 3600 579 571 577
Displaying Memory Information
Shift-Scroll Lock gives:
Mem-info: Free pages: 3136kB ( 4*4kB 0*8kB 1*16kB 1*32kB 0*64kB 24*128kB = 3136kB) Swap cache: add 0/0, delete 231912/0, find 0/0 Free swap: 16596kB 5120 pages of RAM 789 free pages 449 reserved pages 2572 pages shared Buffer memory: 2324kB Buffer heads: 2340 Buffer blocks: 2324 Buffer[0] mem: 1953 buffers, 10 used (last=1953), 0 locked, 0 protected, 0 dirty 0 shrd Buffer[2] mem: 337 buffers, 25 used (last=337), 0 locked, 0 protected, 0 dirty 0 shrd Buffer[4] mem: 3 buffers, 3 used (last=3), 0 locked, 0 protected, 3 dirty 0 shrdSize [LAV] Free Clean Unshar Lck Lck1 Dirty Shared 512 [ 0]: 0 0 0 0 0 0 0 1024 [ 186]: 31 1953 0 337 0 3 0 2048 [ 0]: 0 0 0 0 0 0 0 4096 [ 0]: 0 0 0 0 0 0 0 8192 [ 0]: 0 0 0 0 0 0 0
Netscape Hidden "Easter Eggs"Date: Sun, 9 Nov 1997 22:00:31 +0000 (GMT)
From: Ivan Griffin
These special URLs do interesting things in Netscape Navigator and Communicator.
about:cache gives details on your cache about:global gives details about global history about:memory-cache about:image-cache about:document about:hype about:plugins about:editfilenew view-source:URL opens source window of the URL
Ctrl-Alt-F take you to an interesting site :-)

 |
Contents: |
 New URL for LG
New URL for LGLinux Gazette now has its own domain name! Check out http://www.linuxgazette.com/ as another way to get to LG.
Other LG News While we do not mail issues of LG to our readers--it's just too big--we do have an announcement service. Write with the wordsubscribe in the body, and each month you will receive an e-mail notice when we post Linux Gazette.
Our ftp site will now contain each issue after Issue 9 in its own gzipped tar file. Issues 1 through 8 will be together in one gzipped tar file.
Cool Linux Sites of December!Check out the two cool Linux sites of the month!
The Rat Pack Underground Network is a must-see. This URL has some practical stories about using Linux to solve "real-life" problems and much more.
The Eyes on the Skies Robotic Solar Obsevatory and BBS page contains an internet-accessable robotic solar telescope and BBS system built by Mike Rushford. You can actually control your view of the sun by controlling a telescope from your browser! The telescope control pages are served by a Linux system that is called Eyes on the Skies.
Stand Up and Be CountedThe Linux Counter is a serious attempt to count users in the Linux universe. At the moment, more than 53.000 people are registered with the counter, coming from more than 130 different countries. The counter has been recently updated and given a new Web interface and forms design, and is now able to give you the ultimate Linux counter gimmick: The Linux REGISTRATION CERTIFICATE! This little GIF image, with your personal registration number on it, ready for insertion in your Web page, is available for you at the price of filling out the registration form. Older, registered users can go to http://counter.li.org/update.html, enter their registration key, and get it there.
Come on folks--STAND UP AND BE COUNTED!!!!
Virtual Services HOWTOCheck out the new HOWTO on virtual services which includes a section on virtual mail services as a whole. Go to http://sunsite.unc.edu/mdw/HOWTO/Virtual-Services-HOWTO.html The author would like your comments on the HOWTO in order to keep it on track, you can reach him at
Eiffel SpecialIn celebration of the 200,000th Eiffel Professional license, ISE is making available special limited time offers for new purchases of the Eiffel Professional Licence and upgrades from Personal Eiffel.
FREE Upgrade to Eiffel Professional license with NEW Java Interface (see offer for full details)
Eiffel Professional Suite $495
Eiffel Client-Server Suite $795
Eiffel Cross-Platform Suite $895
Eiffel Enterprise Suite $1195
A special bonus runs with each of the above which includes a free upgrade to the next release, a free O-O book and 15% off any ISE training session up to June 1998. The Enterprise Suite also includes a free year of maintenance and support from the date of purchase.
O'Reilly "Animal Book" ContestReaders of the "Animal Books" by O'Reilly now have a chance to see some wild animals close up, courtesy of computer book publisher O'Reilly & Associates. O'Reilly has launched the In a Nutshell contest, with the prize being a trip for two to the San Diego Zoo and Wild Animal Park. Readers of O'Reilly's bestselling In a Nutshell quick-reference books can find entry forms at their favorite bookstores. Completed entry forms must be received by December 31, 1997, and the winner will be chosen on January 30, 1998.
Official In a Nutshell Contest Rules:
Help with JWPThere is a Windows application, called JWP -- a Japanese Word Processor. This package was written by Stephen Chung, and as a GNU product it is freely distributable. JWP comes with its own fonts and its own Front End Processor (FEP) which means it is useful on English-only computing systems. It is also integrated with Jim Breen's EDICT Japanese-English dictionary. Unfortunately, JWP is only available for Windows right now, which is locking out a lot of people under other platforms who might benefit from it. As Stephen is quite busy with full-time work and maintaining the Windows versions (he's developing version 2.00 now), there is an attempt being made to go ahead and port to X-Windows.
This project will never get off the ground without volunteers. any interested X-Windows developer who wants to make a contribution both to the GNU and Japanese-speaking communities is invited lend a hand with this exciting project.
The JWP-Port Project home page contains more information on the JWP package as well as the JWP-Port project itself. If you are interested, please visit the page at http://qlink.queensu.ca/~3srf/jwp-port.
Perfect Backup+ Personal EditionUnisource Systems, Inc. announced today the release of the famous PerfectBACKUP+ Personal Edition, a fully functional version of their best-selling PerfectBACKUP+ V5.5. Having received continued and tremendous support from the LINUX community, and in recognition of LINUX becoming our #1 best-selling platform we are giving something back. The PerfectBACKUP+ Personal Edition is unrestricted and free to anyone. Its freely redistributable and can be use for either private or commercial use.
Information about, and the program itself can be obtained from http://www.unisrc.com.
86Open ProjectA group which includes some of the key developers of Unix operating systems on Intel architecture computers have agreed to work on a common programming and binary interface. At a meeting held mid-August at the head office of SCO, participants achieved consensus on a way to create software applications which would run, without modification or emulation, on the Intel-based versions of:
The goal of this effort is to encourage software developers to port to the Unix-Intel platform by reducing the effort needed to support the diverse mix of operating systems of this kind currently available. The specification, called "86open", will be published and freely available to any environment wishing compliance. It involves the use of a standardized 'libc' shared library of basic functions to be provided on all systems. This library will provide a consistent interface to programmers, hiding the differences between the various operating systems and allowing the resulting binary programs to run unaltered on any compliant system. Whenever possible, it will be consistent with The Open Group's Single Unix Specification.
Each participating operating system will be free to implement the 86open library specification on its own. However, the reference implementation will be based upon GNU's 'glibc' version 2, ensuring that it will remain open and freely available. The actual list and behavior of the 86open functions is presently being determined.
Participants in the meeting, who will be involved with the ongoing evolution of the 86open specification, include people deeply involved with the operating systems mentioned in this project. The 86open steering committee, a core of this group which will assemble the work and produce the final specification, comprises: Marc Ewing, Dion Johnson, Evan Leibovitch, Bruce Perens, Andrew Roach, Bryan Sparks and Linus Torvalds
For more information, contact or check http://www.telly.org/86open.
Clobberd 3.2Clobberd 3.2 (Clobberd-3.2-RELEASED.tgz) has been released on to the following sites:
Clobberd is a user/resource regulator that allows Operators to monitor and track users Total Time, Daily Time, Expiration time, Total network usage and Daily network usage (to name a few) in an effort to limit or cost resources that the user uses. Clobberd effectively "meters" resources, and compares them to any limits/conditions you impose. The third version now has the ability to monitor users on a network rather than a single host.
Corel Video Network Computer NewsWhen Corel Computer Corp. formally unveils its Video Network Computer later this month, the machine will be running Linux, an operating system that is becoming an increasingly prominent force in workstations linked to corporate intranets.
Linux is a compact, efficient, easier-to-use and free version of Unix. A growing number of corporate MIS groups, as well as software developers and systems integrators, are choosing Linux over 32-bit Windows platforms, especially for Internet applications. At some sites, Linux actually is displacing Windows.
That is what happened at Unique Systems, Inc., a software developer in Sylvania, Ohio. The company, which puts together accounting systems for small and midsize companies, was using Microsoft Corp.'s Office 95 internally but was plagued by software crashes and other problems. "It really irked me," Unique President Glenn Jackson said.
The company tested Applix, Inc.'s ApplixWare office suite on Intel Corp. computers running Linux. Users got nearly all the functionality of Microsoft Office and were able to import all Office files easily into ApplixWare - at much lower cost and with far greater reliability than with Office, Jackson said.
"Linux is the true competitor to Windows NT in the long term," said Dave Madden, senior product manager at Corel Computer, a subsidiary of Corel Corp., based here.
Linux has a number of key features NT lacks. For example, Linux is a multiuser system and runs on a wide range of processors _ from Intel 386 to 64-bit Reduced Instruction Set Computing chips _ and on multiprocessor computers. The Linux kernel is less than 2M bytes.
Linux has other key attractions, according to Jon Hall, executive director of Linux International, a trade group that promotes the software. Linux is free, and users have access to all the Linux source code, which means they can make whatever changes they need. Commercial Linux versions from companies such as Caldera, Inc., of Provo, Utah, and Red Hat Software, Inc., of Research Triangle Park, N.C., range from $49.95 to $399 and usually come with additional software and technical support.
The free version of Linux is crammed with utilities and connectivity software. "One of the things that makes Linux so attractive is how much software you get with it," said Dave Parker, a senior software engineer at Frontier Information Technologies, a division of Frontier Corp., a Rochester, N.Y., telecommunications company. "Linux will connect to anything."
Much of the free software is available under the "GNU public license," which is administered by the Free Software Foundation.
For example, TCP/IP and a Web server are built in, and Linux can run DOS applications. It includes X.11 support, so it can host or access Unix applications.
Linux supports the Microsoft Server Message Block protocol, so it can serve Windows files.
It also supports AppleTalk for Macintoshes. Using optional software, it can even run Windows applications. Cal-dera's commercial OpenLinux adds Novell, Inc. NetWare connectivity.
Frontier Information Technologies' Green Bay, Wis., site is using several Caldera Open- Linux servers as specialized gateways, directory or naming servers and firewalls.
This seems to be an increasingly common practice at big corporate sites, said Dan Kusnetzky, director of operating system research at International Data Corp. in Framingham, Mass.
Unknown to senior MIS executives, operations staff are deploying Linux servers in a range of intranet applications, he said.
 The Answer Guy
The Answer Guy  Running Multiple Instances of X on One Video/Monitor (VCs)
Running Multiple Instances of X on One Video/Monitor (VCs)From: Guillermo S. Romero
Hello,
I have tried to run multiple X servers with only one card and one monitor. Is this possible, or is it normal that the second X server does not run? I used startx display :0 the first time, and :1 the second. I have a 1024K video board (#9GXE64 PCI, S3 864), and normal config is 8 bpp, 1024*768 virtual desktop, running on a remix of RedHat 4.0, 4.1 and 4.2, with XFree86 as server. Maybe I did not understand the man page (English is not my first languaje). Any suggestion?
The normal way this is done is using the form:
startx -- :0 &
startx -- :1 &
... The -- is used by startx and xinit to separate an optional set of client parameters from the set of display/server options and parameters.
If you ran the command:
startx xterm -e myprog -- :1 &
... it would start X Windows with a copy of xterm which would be running 'myprog' (whatever that might be). The remainder of the line informs the X server to use display number one (which would be VC -- virtual console -- number eight on most Linux systems).
(On my systems it would start on VC#14 -- accessed with the {Right Alt}+{F2} key combination. I routinely configure mine with 24 VC's -- the first twelve of which have "getty's" (login prompts) and the next eleven of which are available for X (xdm's or otherwise), using 'open' commands, or for dumping status output from a process (like 'make' or 'tail -f').
Read the man pages for startx and xinit one more time. I'm pretty sure that the man pages have all been translated into Spanish -- so you might want to hunt those down.
Thanks!!!
Read the man pages for startx and xinit one more time.
Sure, and with a dictonary. ;]
I'm pretty sure that the man pages have all been translated into Spanish -- so you might want to hunt those down.
Try:
man-pages-es-0.2-1.src.rpm: ftp://ftp.redhat.com/pub/contrib/SRPMS/man-pages-es-0.2-1.src.rpm
The Spanish Howto is small, too global, sure it does not cover that. And I still have problems with my ntilde chars and acents, Spanish is not supported a lot (Linux or another OS, always late and bad)... The system explained in that howto does not work (but thats another question, whose solution maybe... magic? real support?). GSR
I'm afraid I'm completely ignorant of internationalization issues with Linux. I do know that there is quite a bit of work done on Linux boxes in Japan, Germany, Italy and, naturally enough, Finland (where Linus comes from).
As bad as it seems -- Linux' support for other languages is probably the best in the world. Unfortunately I don't have the skill or resources to point you to the support and resources you need.
Since your English is clearly adequate to discuss these issues with me -- you might consider contributing some of your time to a translation effort (get the LIGS, NAG, and SAG portions of the Linux Documentation project translated, and "beef up" (improve) the Spanish-HOWTO.
I highly recommend that you find or start a Linux user's group in your area. This is the best way to help yourself and to improve the situation for all of your compatriots.
-- Jim
VC MadnessFrom:
Hi
I have an application that uses its own .cshrc and .bashrc to fire up and this is done by using its own login account. Now what I would really like is for this to say select VC8 to run on and then have my normal X on VC7 as usual. Can this be done? and if so how?
--Phil
open -c 8 -- su - $PSUEDOUSER
... where PSUEDOUSER is the psuedo users whose .*shrc you want to run. Naturally you can convert the .*shrc into a normal shell script and do whatever you like with it. You have to run this as root -- (so 'su' doesn't prompt for a password) though there are ways to get around that 'runas' is available at the sunsite.unc.edu archive site and its mirrors). If launch this from another UID you'll need to ensure that this users (the launching user, not necessarily the psuedo-user) has write access to /dev/tty8 (group +w should be sufficient).
If you want to have the console visually switch to this application's VC you can just add the -s switch like so:
open -c 8 -s -- ....
... where the "--" marks the end of 'open's' arguments so that the command that follows it can unambigously get its own arguments.
Without the -c switch the 'open' command will select the next available VC. Any subsequent 'startx' commands or other 'open' commands would then pick later ones (unless the others were freed back up).
You can have two or more copies of X running on different VC's as well. For example the command:
startx -- :1
... will create a second X session on the localhost:1 display (the first one is addressed as localhost:0 or simply :0). These X sessions can be run under different UID's and have completely different client configurations (colors, window managers, etc). There is also an 'Xnest' command that works similarly -- allowing one X session to run "within" (as through a window on) one of your existing X sessions.
You can also set the terminal settings and colors using normal redirection of the form:
stty erase ^? > /dev/tty8
... and:
setterm -background blue -foreground yellow -bold on -store \
> /dev/tty8
This last command would set and store a new set of default screen colors for the VC. The setterm command can also be used to control the Linux VC screen blanker's timeout (a value of 0 means "never blank").
Naturally you may want to read the man pages for all of these.
If you want to ensure that a given process will *always* be running (and will automatically be respawned when it dies) you can add it to your /etc/inittab -- so that the init process will watch over it. This is how new 'getty' processes are spawned on your first six (or so) VC's when you boot and are respawned when you logout. Likewise if you use 'xdm' to keep a graphical (X based) login prompt on one or more of your VC's.
As you can see, its possible to do quite a bit with Linux VC's. I run 12 VC's with getty (as login consoles), have one 'xdm', one devoted to syslog, and ten more available for other purposes (such as 'startx' and 'open' commands and to to use for 'tail -f' commands when need to monitor the end of a status or log file -- from a 'make' or whatever.
The second set of 12 VC's is accessed with the *right* {Alt} key. (In case you'd never noticed, the default keyboard settings of Linux only allow you to use the *left* {Alt} key for switching VC's). I set syslog to use VC number 24 with an entry in the /etc/syslog.conf file that reads:
*.* /dev/tty24
This puts a copy of *every* syslog message on to that VC -- which is what I switch to for a quick glance and try to switch to when I leave any of my systems unattended. (That way when one does lock -- as rare as that is -- I have some idea of what the last throes of the system were).
I set that to bright red on black with the following command in my rc.local file:
setterm -foreground red -bold on -store > /dev/tty24
(I also do the same to /dev/tty12 which I customarily use only for root login's).
Hope all of that helps.
-- Jim
Linux and OSPFFrom: Jose Manuel Cordova-Villanueva
Dear Sr.
Recenty I had my first contact with the Linux G. and is a big source of information, can you inform me if there are a program that can talk ospf because our ISP, is changing from RIP to OSPF and we have a linux box in one of our links, for our cisco no problem but for our Linux box??
The software you want is called 'gated' (for "gateway daemon"). This is a Unix multi-protocol router package for Linux which includes support for OSPF and other routing protocols (BGP4, IGRP, etc).
Here's a link to the top level 'gated' pages Cornell Gated Consortium Information
I've heard that compiling 'gated' for Linux is not quite trivial so here is some other links that might help: Here's a link to a source RPM in the Red Hat contrib directory: gated-R3_6Alpha_2-1.src.rpm
Here's a threaded archive of the 'gated' users mailing list: Gated-People Archive Here's an odd note about an alternative routing software package/project: Route Servers -- RA.net: routing arbiter project
Hope that helps.
-- Jim
Security Problems with pop3 of Linux 2.1.29From: Sam Hillman
Well I hope I'm posting to the right person. I have two questions, which I hope you can answer. 1. How do I setup my linux machine as a POP3 server? I can't find any FAQs or Howtos.
Usually you don't have to do anything extra to allow access to POP services. Most Linux distributions include a pop server pre-installed and appearing in the /etc/inetd.conf and /etc/services files.
A quick test is to login to the system in question and type the command:
telnet localhost pop-3... it should respond with something like:
+OK your.hostname .... (some copyright info)... and you can type QUIT to get out of that.
If that doesn't work you'll want to make sure that the appropriate lines appear in your /etc/services and /etc/inetd.conf files like so:
/etc/services: pop-3 110/tcp # PostOffice V.3 pop 110/tcp # PostOffice V.3 /etc/inetd.conf: pop-3 stream tcp nowait root /usr/sbin/tcpd ipop3d
If they appear commented out -- remove the leading hash sign(s) (or paste these samples in) and restart your inetd with a command like:
kill -HUP `cat /var/run/inetd.pid`
2. When I log on to my ISP, I download my mail and it gets dumped to the sendmail, this creates a situation where the mail is bounced back and forth until it passes the hop limit and is dumped as an error message in the postmaster box, and a nasty letter is send to the originator from MAILER-DEMON... I think this maybe because I'm running a local area network between my two machines, the IP address of the local net is 162.blah.blah... But I also have the IP address the ISP gave me in the host file. If the ISP's IP address is the problem can I remove it from the host file, and just get a duynamic IP when I connect? Thanks in advance!
This is a bigger problem. First the 162.*.*.* is probably not what you want to use for you disconnected LAN. There is an RFC 1918 (originally RFC 1597) which describes and reserves a set of addresses for "non-Internet" use. These are guaranteed not to collide with any valid (routable) hosts on the 'net. Here's the list of those addresses:
192.168.*.* (255 class C address blocks)
172.16.*.* through 172.31.*.* (15 class B address blocks)
10.*.*.* (one class A address block)... use those however you like. Be sure to keep them behind your own routers (make any hosts with those go through an IP masquerading or NAT -- network address translation -- router, or through a SOCKS or other proxy server).
The next problem is configuring sendmail for use on a disconnected system. You probably need to define your hostname (or an alias to your hostname) to match what your ISP has named you. Each ISP seems to use a different way to manage these "disconnected sendmail subdomains" -- with no standardization in site (which is why I use UUCP). I gather that some people use a scheme where they only run sendmail when they are connected. The rest of the time their MUA (mail user agents like elm, pine, mh-e, exmh, etc) just drop outgoing mail into the mqueue directory where 'sendmail' will get to it later. One problem I have with these configurations is that sendmail wants to look up these remote hosts. This seems to cause various problems for users of "disconnected" or "periodically connected" (dial-up) systems. So far the only solutions I've found are: recompile sendmail without DNS support (there used to be a sendmail.cf switch that disabled DNS and reverse DNS activity in sendmail -- but that doesn't seem to work any more) use UUCP. UUCP was designed for disconnected (dial-up) and polling systems. It's what I use. The disadvantage to UUCP is that it's a bit hard to set up the first time -- and you have to find a provider that's willing to be your MX/SMTP to UUCP gateway. There are still some people out there where will do this for free or at only a nominal fee. But they are increasingly hard to find. I use a2i Communications in San Jose. You could use a non-local provider if you want to use UUCP over TCP as the transport mechanism (UUCP is pretty flexible about the underlying transports -- you could probably use tin cans and string as far as its concerned).
There are several HOWTO's that try to cover this topic. Try browsing through some of these:
-- Jim
Thanks so much for the detailed suggestions. We have installed a newer version of pop3 on our server for now and we will look into the feasibility of implementing some of your suggestions for a final cure. Thanks again, James, we really appreciate it.
-Sam Hillman, Service Manager, Easyway Communications.
Cryptographic SystemFrom:Emil Laurentiu
Hello Jim,
Sorry for bothering you but I would apreciate a lot an answer even a short one like 'no' :) I am (desperately) searching a crypographic system for my Linux box. I am already using TCFS but I'm not very happy with it for several reasons: it is slow, I experienced some data loss, must use the login password, cannot share encypted files with other users, NFS - increses security riscs. And the people in Italy seemed to have stoped work on this project (latest version is dated february).
February doesn't seem that old.
Are you sure you're using the latest TCFS (v 2.0.1)? You can find that at: http://pegaso.globenet.it (which is a web form leading to an HTTPS page -- so use and SSL capable browser to get there).
If you find it slow than any other decent encryption is also likely to be too slow for you.
You could look at http://www.replay.com (in the Netherlands). This has the best collection of cryptography software I've seen anywhere.
The two fs level alternatives to TCFS are CFS (Matt Blaze's work, on which TCFS was based) and userfs (which support a few different user-level filesystem types including an experimental cryptographic one.
I am wondering if you know anything about an encryption at the file system level. Something like SecureDrive (from DOS :) which did IDEA encryption on the fly at sector level for a partition and was very fast.
Are you sure SecureDrive is using IDEA? I rather doubt that.
As an (almost) single user on my linux machine something like this would be more apropriate. Of course if I would not find one I'll finish by writing it by myself. My only concern is that I've been a Linux user only for half a year and I did not get the chance to study the kernel to well (this will be a good opportunity :)
Why not pick up on the TCFS or CFS work? Why not build on the userfs work (plugging in whatever encryption you like)?
Why write it "by yourself" when you can collaborate with other members of the Linux community as they have done to bring you Linux itself, and as the FSF and others have done to bring you the GNU packages which turn Linux into a full OS?
What you asking for doesn't need any support at the kernel level. userfs and CFS already have shown that. The Linux kernel already support a robust and open filesystems interface (which support more different filesystem types than any other -- with read-only support for HPFS, NTFS, BSD and Sun UFS/FFS, and support for HFS (Mac), ext2fs, xiafs, Minix, and many others.
If you're a competant programmer (which I am not, BTW) you should be able to trivially take the sources for any of the existing filesystem modules and hack together your own with the encryption support of your choice. How secure the result will be will be a matter of your skills -- and should be greatly improved by peer review (by publishing your work for all to see).
Naturally if you are in a free country you can share your work on cryptography with the world. However the USA doesn't appear to currently be free in this particular respect -- please find a congress critter to vote out of office if this oppresses you.
-- Jim
An Interesting De-Referencing ProblemFrom: Kevbo
Here's the brain teaser I read about and promptly forgot the solution (because I thought it would never happen to me). How does one delete a FILE named ".." I have the following at the root directory.
How this happened I don't know. How to remove this not-bothering-me file has me stumped. Got an answer?
I suspect that this file is actually named something like: "/.. " (note the trailing space!).
In any event you can remove this with a command like
find / -type f -maxdepth 1 -name '..*' -print0 | xargs -0 rm -i
Note: you must use the GNU versions of find, xargs, and rm to ensure that these features (-print0, -0, and -i) are available. (They may be available in other implmentations -- but you must check first).
The find parameters here specify files (not directories, symlinks, device nodes, sockets, or FIFO's) and force it to only search the named directory (or directories if you list more than just /). The -print0 force it to be written as a null-terminated strings (thus the receive process on the other end of the pipe must be able to properly interpret null-terminated arguments -- which is what the -0 to xargs accomplishes).
As far as I know there is no way to legally get a NUL character into a Unix filename. (Using a hex editor might get one in there -- but fsck would probably complain on its next pass).
The -i on rm is just a little extra protection to prevent any other unexpected side effects. It forces rm to interactively inquire about each argument before removing it.
-- Jim
Reminder!From: George Read
I am a subscriber to caldera-users, but as a rank newbie, 99% of what gets posted is irrelevant to my situation and over my head. In fact, I'm looking for some real basic, preliminary information:
Perhaps you should consider some avenue of paid support. there are a number of consultants and even a 900 support line.
Also, if you have access to IRC there are a few #Linux "channels." (If you've never heard of IRC -- or Internet Relay Chat -- then think of it as an online CB system -- similar to the "chatboards" and "chat lines" on various BBS' and online services (like CompuServe and AOL)). Granted IRC is a bear to figure out -- and 99.9% of what's written there is even less relevant or comprehensible than the traffic on this list. However the feedback is immediate and there are some people who will take time out from their usual chat aggenda to help.
There's also that pesky "Answer Guy" from Linux Gazette ;) (but he's too ornery and doesn't help with X Windows stuff at all).
1. A way to create a primary Linux partition on a drive that is entirely occupied by a dos active and a dos extended partition. The extended partition has 400MB available that does not have any data on it, but LISA 2.3 does not wish to give it a primary partition.
You have three choices here. You can repartition the drive using traditional methods (backup your data, reformat, re-install DOS and all applications, restore data). You can repartition using FIPS (a non-destructives partitioning program for DOS -- written by Linux or FreeBSD users from what I gather). If you use FIPS the process goes something like: do a backup, verify your backup, unfragment you DOS partitions, run CHKDSK and/or Norton Disk Doctor and/or SCANDISK, then run FIPS.
Another approach -- and the only one I know of that doesn't involve repartitioning -- is to use MiniLinux or DOSLinux or XDenu. These distributions (of which DOSLinux is the most recent and must up-to-date) are designed to run on a UMSDOS partition (an MSDOS partition mounted under Linux with support for some Unix semantics). You would be running COL -- but you would be running Linux.
You can find information about DOSLinux at Kent Robotti's home page: ftp://wauug.erols.com/pub/people/kent-robotti/doslinux/index.html (Kent is the creator and maintainer of DOSLinux).
2. a workaround to a problem with RAWRITE3: I can't see my COL Base cdrom on a Nakamichi MDR7 jukebox that is controlled by a BusLogic 946C, because Autoprobe can't find anything and I can't get RAWRITE3 to write MODULES.IMG to a floppy on A:.
Have you tried supplying the "max_scsi_luns=7" parameter to the kernel during the bootup sequence (at the LILO prompt).
Normal SCSI controllers support up to 7 devices. It is possible for these controllers to refer to "Logical Units" on any/all of these devices. These "logical unit numbers" or LUN's aren't very common -- but are used by CD changers (which is why most of them are limited to 6 or 7 CD's) and some tape changes (though those usually use a different mechanism to control tape changes and ejections) and some RAID subsystems and CD-ROM "towers."
I have a NEC 7 platter CD changer which requires this parameter. This suggestion assumes that the problem is isolated to the CD drive -- and that your kernel (LISA's) is seeing the BusLogic card. If the problem is that you can't even see the SCSI controller -- then you probably want to look for an alternative boot/root diskette set and boot from that.
One of the nice things about user's groups is that you can often have the phone numbers of some local Linux users that will cut you a custom kernel on request and let you pick up the floppy. I'd highly recommend finding (or starting) a local LUG. I've occasionally had people come over to my place where we could plug them onto my ethernet and suck all the free software they want across from one of my systems.
(Which reminds me -- I've been meaning to get PLIP working for a couple of years now -- I should really get around to that).
For these reasons, I ask: Is there any way to ask caldera-user users for some help on these two questions, sent to my own email address, and not have to read 20 or 30 messages that I can't profit from, at least until I get COL up and running. I had hoped from the name that Post-Only might be such an address, but I see that it is something very different.
Caldera has some support options. I think some of them are extra cost items. Have you called them about your Caldera specific questions?
At first blush it doesn't look like Caldera's COL is the best Linux distribution for your needs. If you're intent on using COL -- and particularly if you have a business need for Linux -- I'd recommend going out and buying an additional drive. For a couple hundred bucks (US) you can get a 2Gig external SCSI drive (www.corpsys.com if you don't have a suitable vendor handy).
Even if you're just experimenting with Linux and don't want to "commit" to it -- an extra external SCSI drive with a couple of Gig of space is a handy investment for just about ANY operating system. It's pretty convenient to connect the extra drive, and just make a copy of everything from your main system.
If your time is worth more than $20/hr you can easily make the case for buying a $200 to $300 hard drive. Doing full system and data backups, and verifying them prior to repartitioning can be pretty time consuming. Even if you already have a scheduled backup habit (let's face it -- most don't) and even if you have a regular recovery test plan (which almost nobody bothers with -- often to their detriment!) -- doing a major system change (like repartitioning) almost requires an extra "full" backup and test cycle.
(I have customers who've run the cost vs. time numbers for their situations and justified buying a full system and hired me to do the configuration on the same basis. The "extra" system becomes part of the recovery plan for major system disasters).
-- Jim
pcmcia ide DrivesFrom: Alan C. Sklar
I am trying to install a pcmcia drive through a kit I purchased.. I got the drive all ready I formatted it with a desktop machine and bot my win 95 and linux partitions are defiend... But now when I go and boot linux I send the commad ide2=0x170 and it loads it identifies the right drive but I get all sort of errors... Can you help?
C. Alan Sklar
I don't have enough information to help with this one. Is this a laptop or a desktop with a PCMCIA adapter installed? In either event what is the make/model of the system?
Do you have PCMCIA support installed and built into the kernel? What modules do you have loaded? What does your /etc/pcmcia/config.opts file look like? What type of hard drive is this (make and model)?
-- Jim
KDE BETA 1From: Eric Wood
This should be the most handy tip known to man! If a certain application (I don't care what it is) complains about missing a library and you know that the library it's wanting is in a certain directory THEN:
That's it. What is does is it tells Linux to search the directories specified in /etc/ld.so.conf for library files. Forget about the stupid LD_LIBRARY_PATH variable. Everyone: Please read the ld.so man page for further knowledge.
Eric Wood
I recently trashed my /etc/ld.so.cache file and had forgotten how to fix it (since the last time I'd had a damaged ld.so.cache was on an old Sun a couple of years ago -- and I've never had one on a Linux box before.
Post that to your tech support archives:
System hangs on boot -- even with -b and single switches -- or it gives messages like "unable to open ls.so.cache" in a seemingly endless stream:
Run /sbin/ldconfig!
-- Jim
Compression ProgramFrom: Cygnus
Anyone know of any programs for linux that decompress multi-part (multi-disk) .zip archives? I can't find a one.
-Cygnus
Most Linux distributions come with the free zip/unzip package. Here's the -L (license) notice from my Red Hat 4.2
"Copyright (C) 1990-1996 Mark Adler, Richard B. Wales, Jean-loup Gailly Onno van der Linden and Kai Uwe Rommel. Type 'zip -L' for the software License.
Permission is granted to any individual or institution to use, copy, or redistribute this executable so long as it is not modified and that it is not sold for profit."
I think there's a source package for "Info-zip" also floating around. I don't know if this is Info-zip or an independent version -- looking in /usr/doc/unzip*/COPYING I find Mr. Rommel listed -- and that document is definitely about Info-zip.
For the future you might try the 'locate' command -- which is fairly common among Linux distributions. The command:
locate zip
... will quickly find every file with "zip" in the name or path that was on your system during the last "updatedb" run (which is typically a cron job that's run nightly).
-- Jim
loadlinFrom: Scott Williams
Answer guy, To run LOADLIN I need to have a copy of the LINUX kernel on one of my dos partitions, and an initial swap space. No where can I find an actual explaination on how to do this correctly.
You don't need an initial swap space to run LOADLIN or to load the kernel. If you have 8Mb or more of RAM you don't "need" to have a swap space at all -- but you'll probably want one. You can swap to a file or a partition -- or even several of each. Assuming that you don't have Linux installed yet you can view man pages for most Linux/GNU commands, functions, packages, and configuration files at: http://www.ssc.com/linux/man.html
... in particular you want to read the mkswap(1) and the swapon(8). The man pages there are accessed via a CGI script so you have to post data to a form to access the individual pages. Thus I can't give URL's directly to the pages in question. That's an unfortunate design decision by the web master at SSC -- it would be more convenient to access (and cause less server load and latency) if they used a cron job to periodically update a tree of static HTML pages and saved the CGI just for searching them.
Every time I try to copy the kernel to a dos diskette, Linux overwrites the formatting. DOS then cannot recognize the file from the LOADLIN command.
It sounds like you're using 'dd' or RAWRITE.EXE to prepare these diskettes. That's fine for transferring boot/root images -- but has nothing to do with LOADLIN. To use LOADLIN.EXE you copy the kernel image to a plain old DOS file.
I haven't even gotten far enough to think about creating an initial swap space... Any advice on the subject?
Scott
I'd consider getting a copy of DOSLinux from ftp://ftp.waaug.erols.com/pub/people/kent-robotti/doslinux.html (Yes there are still some people out there serving HTML pages via FTP -- nothing in the HTML spec *requires* that HTTP be used as the transport mechanism).
Kent Robotti has been working on this distribution for awhile. It takes about 32Mb of space on a DOS partition -- and comes as a set of six 1.44Mb files (so if fits on a half dozen diskettes). You then add a kernel for SCSI or IDE use.
Basically DOSLinux works like this. You get all the RAR files (RAR is a Russian Archiving Program like PKZIP, SEA ARC, ARJ, LHARC, ZOO, or whatever). The first image is a self-extracting file (an archive which is linked with a DOS binary of the decompression program -- a common DOS technique among archiving programs). You put these all in a given directory and run the self-extractor (DOSLNX49.EXE as I write this -- it was at "48" a couple weeks ago) from C:\. It thenn extracts all of these images to C:\LINUX directory.
This provides a complete (though minimal) Linux distribution. It also shows how to configure a system to use LOADLIN with a UMSDOS root partition.
I realize that you may be intending on use something like Red Hat, Slackware, or Debian on a third hard drive, or a removable drive or some other device that LILO just can't see (because you BIOS can't "see" it). You can do that -- and I've done in many times (I first used LOADLIN in about 1994 for exactly that purpose -- with the magneto optical drive I still use). However, if the README's and examples that come out of the LOADLIN package aren't helping you use if for that purpose -- than installing DOSLinux may help get you rolling and serve as a vang DOSLinux may help get you rolling and serve as a valuable example. -- Jim
WipeOutFrom: Falko Braeutigam
Hi, in Linux Gazette Issue 22 there was a question about the WipeOut IDE. Your answer was that you never heard about WipeOut :-( Please check ShortBytes of Issue #19 - there is an announcement of WipeOut. WipeOut has nothing to do with xwpe. It _is_ an IDE for C++ and Java. There is just a new release -> http://www.softwarebuero.de/index-eng.html.
Regards,
Falko
This definitely counts as my biggest flub in the 10 months that I've been writing this column. I've gotten about 10 messages correcting me on this point.
-- Jim
Well since Michael Hammel was our featured speaker for the evening we had our obligatory snow storm (grin). It is amazing that every time he attends one of our meetings this happens. Nevertheless, we still had 24 people in attendance.
For those of you who don't know Michael, he writes the Graphic Muse column for Linux Gazette, maintains the Linux Graphics mini-HowTO, helps administer the internet Ray Tracing Competition, coauthored the UNIX Web Server book, designed the magazine cover for the November issue of Linux Journal, and is also the author of a four part article "The Quick Start Guide to the GIMP" now running in Linux Journal.
His presentation started out with a demo of the GNU Image Manipulation Program (GIMP) showcasing many of its features, and perhaps more importantly giving us all an idea of what it could do. The discussion then turned to GUI builders. The group discussed their experiences, likes, dislikes, advantages, disadvantages, and general opinions of many different GUI design software packages. Supporting this discussion, Michael showed us examples of GUI building using XForms (I hope I've got this right) and Visual TCL.
After this discussion, Michael showed a 10 minute video tape of Toy Story animated shorts done by Pixar. I think that everyone got a few good laughs from this. We then held a drawing for two CD's from the Internet Ray Tracing competition, and a copy of the November Linux Journal. As usual, we wrapped up the evening with a general discussion of Linux related topics.
Since Michael is moving to Dallas next week, I particularly want to thank him for his support of our group!!! I have appreciated him taking the time to talk to us, and have always enjoyed his presentations. I want to wish him the best of luck at his new job. It might be a good idea to warn the North Texas Linux User's Group of an impending change in their weather though (very big grin). Perhaps he can continue to participate in our discussions on the mailing list?

.bashrc and .bash_profile Well, I found out why the bash dotfiles I talked about last month didn't work, and there were a couple things I did wrong. First I didn't recognize the difference between instances of bash and how they differ.
alias xx=whatever -options.notice that there is no white space between the alias name, the equal sign, and the command that the alias represents
Besides aliases you can do also change the color of your console screen with your .bashrc or .bash_profile, by using commands like:
"/dev/tty1") setterm -background green -foreground black -store;;
Installing Software
One very tricky procedure for new linuxers is installing software. Several months ago I touched on this subject, apparently not in enough depth, so I'm going to give it another go this time with a little more experience under my belt. The best advice I can give you if you are using debian, redhat, or caldera distributions is to look for the software you would like in a compatible package format, ie. RPM for redhat-caldera, and deb for debian. These are most commonly binaries and don't require much to get running.Slackware has packages in tgz format, but this can be misleading, as some source packages are inexplicably given a .tgz extension. If you get your software from the CDROM you should be set, with packages for a given distribution on that CD. Ifg you got your distribution from an ftp site, try using the most appropriate software found on that site, to see if it fits your needs. If not, you should check out the Linux Software Map, to see what kind of alternatives there are for the kind of applications you want. if you have disk space, I recommend that you choose a couple that seem to be close to what you are looking for, install them and use them for a short period to see which is more suitable for your uses. Sad but true, some software compiles easily, but you will probably find that many others take some hacking, and some doesn't seem to compile at all. You are at a distinct advantage if your Linux distribution conforms to the Linux FSSTND, which tends to assure that paths to libraries are the same in your distribution as they were in the distribution that they were written for/in. With enough hacking however, all of the software that has been compiled on one distribution can be compiled on any other.
tar -zxvf filenameto unpack it, since sometimes the untarring doesn't create a separate directory and if you just unpack it in an existing directory you could get a real ugly situation when you get a bunch of disjointed files cluttering up your directory. you can also use tar -cxvf or similar combination to get a listing of the files that would be unleashed when you use the -z option. This will tell you if the files have a designated pathname which means that it will create its own directories and subdirectories that will keep the parent directory nice and tidy.
cat README |pr -l 56 >/dev/lp0(or lp1, or whatever). Using the -l 56 option should paginate the file so that page breaks occur where they should.
I'm not really a Linux guru, and I'm starting to get into more advanced (??) stuff, and my intent was and still is to present information that a new user can implement now and research at his/her convenience, I'm not trying to be the Weekend Mechanic OR the Answer Guy, although I aspire to their level of Linux prowess. Briefly put, although it's a little late to be brief, I may not be appearing monthly after this issue, since I don't want to write just to hear myself type, I'll likely post a column when I can nail down a column's worth of information.
I still invite questions, suggestions, reasonable criticism and just plain e-mail:
Don't M$ out, try Linux!!
Las Vegas, Nevada is host each year to one of the largest technology trade shows in the U.S.--COMDEX/Fall. This year nearly 220,000 industry professionals lined up to find, test and research the latest technologies from the leading industry vendors.
Earlier in the year the staff of Linux Journal volunteered to coordinate the COMDEX/Fall Linux Pavilion. Coordinating the event turned out to mean hours of preparation, and, luckily, vendors were quick to lend a hand. Kit Cosper of Linux Hardware Solutions managed to talk the spirit of Linux into Softbank, the sponsor of the COMDEX show. As a result, COMDEX personnel were very cooperative and worked with us to ensure that the floor space for the pavilion was in the best possible site; that is, we weren't hidden away in a back corner.
Attendees seemed pleased to find many of their favorite Linux vendors in one convenient and easy-to-find area. Vendors present included Caldera, Linux Hardware Solutions, Enhanced Software Technologies, S.u.S.E., Red Hat Software, Hard Data, Quant-X, Infomagic, LinuxMall, Linux International and, of course, Linux Journal.
Jon "maddog" Hall barely held his own against the hordes of Linux enthusiasts visiting the Linux International booth. Several members of the Linux community kindly volunteered their time to staff the Linux International booth, answering questions and spreading the word about Linux. Volunteers included Marc Merlin, Ira Abramov, Dan Peri and Richard Demanowski.
Red Hat Software announced the December 1 release of Red Hat Linux 5.0. To mark the event, Red Hat balloons filled the Linux Pavilion area of the convention center. The Linux mascot, Tux the penguin, was carried away in all of the excitement (see photo).
S.u.S.E., a popular European Linux vendor, also announced the latest release of their Linux distribution, S.u.S.E. 5.1. This was S.u.S.E.'s first appearance at COMDEX, and considering their rapid growth in the U.S. market, it will most likely not be their last. Their distribution demonstrations proved to be great crowd pleasers, compliments of Bodo, Rolf, Michael and James Gray, the President of S.u.S.E. U.S. (See review of S.u.S.E. in this issue.)
Clarica Grove, Britta Kuybus and I staffed the Linux Journal booth. We were quite pleased with the turnout of this year's show. During last year's COMDEX, we were kept busy explaining what Linux is to all comers. We were pleased to find that this year's COMDEX attendees had remembered and done their homework from last year. Not only did most people we spoke with know about Linux, but many of them are using it and very excited with their results. It goes to show that the popularity of Linux is indeed growing. Linux is being looked at more than ever as a cost-effective, viable operating system. Thanks to years of dedicated work by all of the Linux vendors, Linux International and the Linux community, we are now able to begin enjoying the success of Linux. This year's COMDEX Linux Pavilion was a showcase of this success.
Linux Journal would like to thank everyone involved with this year's show--look forward to seeing you there next year.
 In this article, I'll describe how to configure procmail using The Dotfile Generator (TDG for short). This will include:
In this article, I'll describe how to configure procmail using The Dotfile Generator (TDG for short). This will include:
Figure 1 |
Figure 2 |
The first category of backup is to back up all incoming mail. The code, which must be generated to the procmailrc file for this, will be written as the very first line. This is to avoid that any errors in the generated procmail file will throw away any of your mails. This sort of backup is only a good idea when you at first start using the generated procmail file. The main drawback is that all incoming mail is saved in one file, and this file may become huge very fast.
The second method is to backup all incoming mail, which are delivered by procmail. This may be a good idea to use, to verify that mail are sorted into the right places.
The third method is to backup all mail, which makes it to your incoming mailbox. This mail are often mails, which do not come from a mailing list, and which are not junk mail to thrown away.
In the first method, you have to specify the full filename. This is because this method has to be 100% full prof. In the next two methods you may build the file names from the current date and time. This makes it possible to save this sort of mail to folders, for the current year/month/week etc. E.g. a folder called backup-delivered-1997-July
As an additional feature, you may keep the files as gziped files.
The backup of delivered mail may be specified for each individual recipe, or for all recipes at once. (see figure 4 check box 9) To learn how to use the FillOut elements, which configures the file to save to, please see the Dotfile Generator article in Linux Journal.
Procmail will finish testing recipes when one is matched, unless a flag is set to tell it, that this recipe should not stop the deliverment (see figure 4 check box 8). This means that the order of the recipes are important, since only the first recipe, which match will process the letter.
If none of the recipes are fulfilled, or if the ones which are fulfills have check box 8 in figure 4 set, the letter is delivered to the incoming mailbox as if the procmail filter haven't been there at all.
You configure the recipes on the page called ``Recipes''. This page can be seen in figure 4.
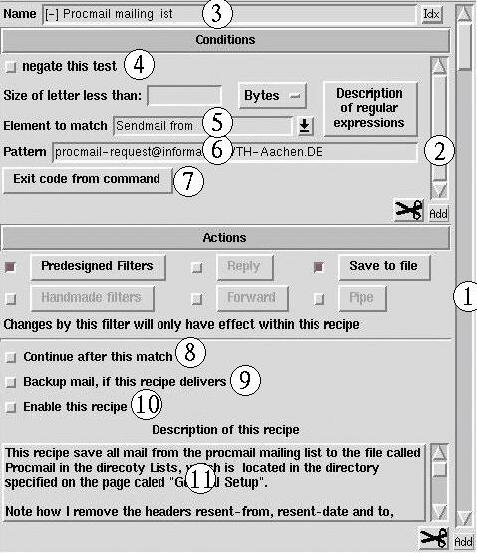
What you see here is an ExtEntry. An ExtEntry is a widget, which repeats it elements as many times as necessary (just like a list box repeats the labels.) All what you see on this page, is one single recipe. To see a new recipe, you have to scroll the outer scroll bar (1). To add a new recipe, you have to press the button below the scroll bar.
As described above, a recipe is a set of conditions. This set is also represented with an ExtEntry (2). To scroll to another condition in a recipe, you have to use scroll bar (2), and to add a new condition, you have to use the button below scroll bar (2).
You may give each recipe a unique name, which will make it easier to find a given recipe. This name will also be written to the file with mail delivered by recipes (method 2 above), so you can see which recipe matched the actual letter. To give a recipe a name, use entry (3). At the right side of the entry, a button labeled Idx is located. This is a quick index to the outer ExtEntry (i.e. the recipes). If you press this button a list box will drop down, where you may select one of the recipes to scroll to, by its name.
From [email protected] Tue Jan 28 16:30:46 1997 Date: Tue, 28 Jan 1997 10:06:28 -0500 (EST) From: Rick Troxel <[email protected]> Subject: Re: Lynx as an external viewer for pine In-reply-to: <[email protected]> To: procmail mailing list <[email protected]> Cc: "Robin S. Socha" <[email protected]>The very first line of the letter is special. This line has been written by the program sending the letter (often called sendmail). This header field is often always the same for a given mailing list, so to sort mail from a mailing list, it might be a good idea to read the letter with an ordinary file reader (NOT a mail reader, as it will seldom show this line). And copy this information to the pattern field (figure 4, label (6) ). As the element to match, you have to select Sendmail from in entry (5).
Three special macros exists in procmail. These may be used, when matching header fields:
There is a lot of header fields to chose between in the pull down menu (5), but if the one you wish to select isn't located there, you may type it yourself.
The check box (4) may be used to negate the condition, i.e. the pattern shall not match to fulfill the condition.
One common pitfall is to forget to match everything at the start of the line. I.E. If you wish to set up a regular expression for the From: field above, it is not enough to give the pattern: [email protected], since this is not at the start of the line, you have to tell procmail that every mail messages, which includes the text [email protected] is to be handled, I.E. insert .* in front of the email address.
Procmail will consider the condition fulfilled if the exit code from the program is 0 and not otherwise. This behavior may be changed with the check button (4) in figure 4.
On this page you will find one custom-made filter: Remove signatures. With this filter, you may specify a signature for each email address. If the text you specify is found (exactly!) it will be removed from the letter. My intention is that more custom-made filters will be added, as users send me their ideas and filters.
As an example, you may remove the header with the command cat - >> /dev/null, or add a message to the body of a message with the command echo This letter has been resent to you, by my procmail filter!; cat -
If only the filter actions is selected, the filter will change the letter permanently, i.e. the changes will have effect on the subsequent recipes (even on the delivered letter, if no recipe match!) This may be useful if you e.g. uses a mail reader, which does not support mime, and you have a filter, which can convert mime encoded text to 7 bit ascii.
If however one of the other actions are enabled, the changes will only have effect within this recipe!
The reply is only sent, if the letter does not come from a daemon, to avoid that you sent a reply to every message on a mailing list.
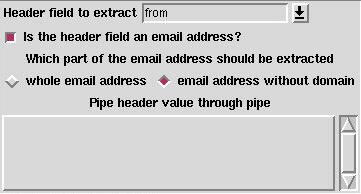
Email addresses may be given in three ways:
Finally, you may pipe the header field though a command you specify yourself. This command may read the value of the header field on standard input, and write to standard output.
Should something go wrong, you may turn on extended diagnostic, this will write additional lines to the log file, which lets you see what it does. To debug this, you have to read both the log file and the procmail file.
If you use the log abstract options, you will find the program mailstat very useful. This will tell you how many letters have been delivered where. One line in the output from the mailstat programs is fake, and that is the line, which says: /bin/false. This line is due to the way that the generated code look. When you wish to throw away a letter, in a way so you can explicit see that is has been dumped, you should deliver it to the file called /dev/null. Please note that you can only use the mailstat program, if extended diagnostic is turned off.
"|IFS=' ' &&exec /usr/local/bin/procmail -f-||exit 75 #YOUR_USERNAME"With the correct pathname for procmail, and your email address replaced with YOUR_USERNAME
Here's a few link, which you may find interesting:
 |
|
 |
muse:
|
So, another busy month gone by. I'm still in the throws of pre-shipment testing at work but fortunately my code seems to be pretty stable now. I've even managed to get far enough ahead that I've been able to work at home on other projects while the rest of the gang catches up. To their credit, their stuff was harder to work on than mine. I got to design and write my code from scratch. No legacy code for me.
One of the things I've been working on is getting deeper into the GIMP. If you haven't seen it yet, take a look at the November Linux Journal. The first of a 4 part series I wrote on the GIMP was published in that issue. I also have started to learn much more about how to create interesting effects. If you have some free time and online-money to burn, check out my GIMP Gallery. I've put most of my more interesting images there.
This month I'm going to talk a little about how to use the GIMP to create a frame with a 3D metallic or plastic look. The process turns out to be fairly simply and is one you will probably get to know by heart if you use the GIMP very often.
I'll also cover my notes from SIGGRAPH '97. I wish I could have done this right after I got back when the conference was still fresh in my mind, but things didn't work out that way.
Finally, I'll be covering JavaScript image rollovers - those cute little image swapping thingies that many people have added to their Web pages. You can do these using a number of different techniques, but I'm only familiar with JavaScript right now so thats what we'll talk about.
As usual, feel free to on any of this.
 |
CurveSoft announces release of FontScope.CurveSoft(tm) is pleased to announce the availability of FontScope(tm): A commercial, high-performance portable rasterizer ibrary for Type 1 scalable fonts sometimes also called PostScript(tm) fonts.FontScope allows developers and programmers to build Type 1 scalable font support directly into their applications thus roviding a fast, efficient, high quality platform-independent solution to the problem of providing scalable font support. See http://www.curvesoft.com for further details about the product. FREE DEMO If you have access to a Linux(x86) or a SunOS(SPARC) machine, we strongly suggest downloading the demo program since that allows you to test FontScope on your own Type 1 fonts as well as get an idea of thespeed and quality. If unanswered questions still remain, please email them to [email protected] |
|
||||
| Courier-Bold | Courier-BoldOblique | Courier-Oblique | Courier |
| Helvetica-Bold | Helvetica-BoldOblique | Helvetica-Oblique | Helvetica |
| Times-Bold | Times-BoldItalic | Times-Italic | Times-Roman |
| AdobeSansMM | AdobeSerifMM | Symbol | ZapfDingbats |
| ArialMT | Bodoni-BoldCondensed | BrushScript | Courier |
| DomCasual | LetterGothic | NewsGothic | Perpetua |
| Symbol | TimesNewRomanPS | TimesNewRomanPS-Bold | TimesNewRomanPS-BoldItalic |
| TimesNewRomanPS-Italic | |||
A: Check out the VRML update on BUILDER.COM:
Q: Whats the latest news on commercial game development for Linux?
A: There was an important announcement from Crack.com recently. Check out

ldconfig generally looks in /usr/local/lib, along with a few other places, for libraries. To make sure it does, check /etc/ld.so.conf and make sure that directoy is listed there. Check the man pages for ldconfig if you have any further problems.
If ldconfig -p shows gtk is already installed then the other possibility is to add the following to your .profile:
wrote:
Tethys <> wrote in respose to a Musing last month about NetPBM not having JPEG conversion tools:
I did a review of all the Linux scanner information I could find in my Graphics Muse column in March of this year. You can take a look at it starting at the Linux Gazette's (which is the online magazine that carries my Graphics Muse column) table of contents at http://www.ssc.com/lg.
Gregory Gardener <> wrote:
Don't choose a platform, choose a technology: Java and/or VRML. Why? By doing so you remove the need for your end users to be required to have a particular platform to use your software. Second, you can more easily fit into any organization no matter what platforms they might already have.
Problems:
#3 is a problem. There are only a few VRML browsers for Linux right now and I don't know much abou them. Liquid Reality is one - it requires you have the Java runtime environment installed and working. VRML on non-Linux is actually better supported right now, but thats probably a situation that will be fixed within the next year (again, my guess).
Now, assume you go with these two. Now you can choose your *own* development platform. I'd pick Linux. Why? Because MS is not being very forthcoming about their support of Java - Linux has embraced it quite happily. I'm just getting started with Java development so I can't tell you how to use the tools, but the Java Development Kit (JDK), all the way up to version 1.1.3, has been ported to Linux. There is a commercial Java IDE kit, Vibe, for Linux already.
VRML is like HTML and you can write it using vi or EMACS or whatever text editor you'd like. Eventually there will be WYSIWYG editors for VRML, but for now it shouldn't be difficult to do by hand. In fact, many of the current VRML texts are written from the point of view that you are writing it by hand.
Alternatives: OpenGL/Motif/C. This is the way I'd do it right now simply because I already now Motif and C and OpenGL is something I've been studying off and on for a few months now. I really like OpenGL, but if you use Motif/C your application is less portable across platforms (ie its not very easy to port to MS or Macs). OpenGL has been ported to lots of platforms, but it doesn't provide a windowing toolkit so you have to use it with a toolkit native to your platforms (Motif/X, MS Windows, etc).
Now, this still might not address your problem because "an interactive educational system" can encompass all sorts of display data so its hard to say if Java/VRML will work for you. What sort of graphics do you need to display? How do they need to be displayed? User Interfaces (UI's) is a big area of study that few people hear about because the hype from the technologies you use for them gets more attention. The problem still exists - which technology do you use? The answer - whatever one you're most comfortable with for now. Eventually, you need to get familiar with Java and VRML.

This month we'll talk about a common trick many people are using in their Web pages today: image rollovers. An image rolllover is an image that changes based on user input. For example, if you look at my GIMP pages (you'll need Netscape 3.x or later for this) you'll see image rollovers in the menus. When you place the mouse over the text for one of the menu items, the Gallery for example, the text background changes to a light blue or cyan color. The text is actually an image, not ordinary HTML text. When you place the mouse over the image it is swapped out for another image, the cyan colored version. Thats a rollover.
Adding rollovers is actually fairly easy. First, you need to make two copies of an image (we're taking a very basic approach to this - you can actually create multiple versions of the image to be displayed based on different types of user input). The first copy is the original, the image to be displayed initially or when no user input is being applied. The second is the image to be swapped in when the user moves the mouse over the original or clicks on the image. Creating these images can be done in any number of ways. Personally, I use the GIMP. Its well designed for these kind of image processing tasks.
Next you need to understand how JavaScript interprets user input. These are called events. There are number of different events that JavaScript can recognize Not all are applicable to images, however, nor to use with rollovers. The ones of interest are:
| Event Name | Meaning | JavaScript and Netscape versions |
| onclick | User clicks on an image. | 1.0 (Navigator pre-3.x) |
| onmouseover | User moves the mouse over the image | 1.0 (Navigator pre-3.x) |
| onmouseout | User moves cursor out from link or image map. | 1.1 (Navigator 3.x) |
| onmousedown | User presses a mouse key down but doesn't release it. | 1.2 (Navigator 4.x) |
| onmouseup | User releases the mouse button. | 1.2 (Navigator 4.x) |
Finally, you need to understand how JavaScript references images on a Web page. The trick to rollovers is to update the correct image - in some cases the image to update is not the image over which the mouse currently rests. For example, see my contents page where I update a central image when the mouse is placed over images that surround the central image. That page doesn't do a good job checking which browser is being used and as a result it doesn't work well with non-Netscape 3.x browsers, or even 3.x browsers on non-Unix platforms. Still, the rollovers do work right on the Linux Netscape browser.
JavaScript references images as objects and as such treats them just like any other object. Images in a document (documents are HTML pages) are referenced using names, such as
 |
| document.dog.src |
First, lets look at the image's HTML definition:
A few other things we should note about this bit of HTML:
<!-- Hide script from older browsers
numitems=2;
SampleImages = new Array(numitems);
SampleImages[0] = new Image();
SampleImages[1] = new Image();
// Establish the two image objects we want to use.
SampleImages[0].src="./gx/hammel/dog-1.jpg";
SampleImages[1].src="./gx/hammel/dog-2.jpg";
// Event handler called for onMouseOver event
function mouseIn(input_status)
{
status = input_status;
document.dog.src = SampleImages[1].src;
}
// Event handler called for onMouseOut event
function mouseOut()
{
status="";
document.dog.src = SampleImages[0].src;
}
// End of hidden script -->
</SCRIPT>
The two event handlers call JavaScript functions. The mouseIn() function is called to change the image when the mouse enters the image area. As you see in the HREF tag the event handler associated with this function is the onMouseOver event. This function has two lines. The first takes the text passed as an argument and places it on the status bar at the bottom of the browser. The second line replaces the image referenced as "dog" by the second image in the SampleImages array. Pretty straight forward, don't you think?
The second function, mouseOut(), is called when the mouse is moved out of the image area. It, too, has two lines. The first clears the status bar and the second places the image in the first element of the SampleImages array over the image currently in the object called "dog". In this case, the SampleImages array's first element holds the same image source as the original image displayed in the IMG tag in our HTML source.
A few things to note about the code: I used an array to hold the images I wanted to use for my rollover. In this simple example I could just have easily used
The image object also contains a number of other properties, such as the BORDER width, image HEIGHT and WIDTH, and the VSPACE attribute for setting the vertical space around the image. By not specifying the HEIGHT and WIDTH for the document.dog object in the functions I have assumed the new image has the same dimensions as the old. If this were not the case you might want to update the image dimensions in your functions as well.
Well, that should get you started. Image rollovers are kinda cool to play with and can add a little pizazz to an otherwise drap Web page, but be careful. Like most of the neat toys on the Web, too much of anything can be annoying.
 |
SIGGRAPH 97 NotesFor those that don't know, SIGGRAPH is the yearly conference on computer graphics sponsored by the ACM. To be exact, SIGGRAPH is the Special Interest Group - Graphics of the ACM and the conference is an extension of that, but in the past few years this conference has grown into a major exposition where all the big names in the computer and entertainment industry show their latest wares. This year the conference was held in Los Angeles. It was also my inaguaration into this madhouse.I should tell you that what follows is not specifically Linux related. I will try to associated what I saw or learned with Linux as much as possible, but in general Linux is not a powerhouse at SIGGRAPH, In fact, with the exception of one technical course and a couple of engineers manning booths at the show, I didn't hear anyone talk about Linux. We have some work ahead of us to get real notice. For me, SIGGRAPH lasted 4 days, Sunday through Wednesday, even though the conference actually ran for 6 days. I went as my vacation (sick, isn't it) and after 4 days had been run so ragged I decided my last full day would do something quite and peaceful - so I went to Universal Studios. SIGGRAPH, for those who've never been, is non-stop energy drain, both physically and mentally. My first day there I spent going through lines - at the airport, at the car rental (my god, what a mess), and at the conference registration booths. I had preregistered and so I only needed to pick up my conference materials, but that took about 45 minutes. Having not been to a conference of any kind since a trip to Interop back in 1991, I was a bit disappointed to see no texts provided for the courses. In fact, the courses weren't really courses, they were presentations in front of monster sized audiences. I remember the Interop courses being a bit more personal, more like real classes. Although I got there late, I did managed to get into the Introductory class on OpenGL that was given by SGI staff members. It was mostly a discussion on basic OpenGL syntax. I did manage to wind up sitting right next to Bruce Peren's office mate at Pixar - a very nice fellow named Jim W. (my notes didn't include his last name - hope he doesn't get made at me). That seemed strange until I found out that Pixar sends just about everyone to SIGGRAPH. A few days later I saw Larry Gritz but didn't get a chance to talk to him. Like most people at SIGGRAPH, he was in a hurry to get somewhere. The rest of the day I spent wondering around the LA convention center looking for where other classes and events would be held. There was a career center downstairs where people could post resumes and companies posted job positions. Xi Graphics had a posting there, but other than that I didn't see any Linux-related postings. By the time I got back to my hotel it was about 9pm - and I had yet to eat that day. One word of warning to future attendees: take snacks! Finding food can be hard and what you do find can be awful (at least in LA by the convention center) and you will need the enegy! Being a running, I should have brought a few energy bars with me. Well, thats a lesson learned. The next day I went to the Advanced OpenGL course, also taught by SGI staff. This was a more interesting class to me, since it talked about techniques a bit more than just syntax. There were some good discussions on using environment maps (mapping an image to surface), projecting textures, and billboarding. This last one is a cool technique I wasn't aware of. An image is mapped onto a planar surface and that surface is programmed to always face towards the viewer. It is sort of like taking a photo of a tree, cutting away all of the photo except the tree, and pasting it to a popsicle stick. The stick is then rotated so that the photo of the tree always faces you. It simulates a 3D effect without all the overhead of huge polygon counts for a real tree. This technique works well for scene objects that are in the distance but looses its effect up close. You can see billboarding effects in many games. Another effect they covered was the creation of fire. They used a noise function along with what are called "quad mappings" to blur regions of the noise. They then added some turbulence and an absolute value
When I got home I went to visit my sister and her kids and watched them play Super Mario Bros on their ... Sega? Anyway, having just returned from SIGGRAPH I could see the effects they talked about in the advanced OpenGL course. It was very enlightening. One of my reasons for going to the OpenGL courses was to get an idea for how multimedia applications could be built for Linux. An alternative to an OpenGL based multimedia kit would be one based on VRML. I attended the VRML Demo SIG on Monday night and it had some very cool demos using VRML 2.0. If based on CD-ROM this could be a very good cross platform environment for multimedia packages (edutainment, for example). The current drawback is that the demos required 2.0 capable browsers, but there should any number of those showing up in the next year or so. According to CGW (freebie that was dropped at my hotel room - very nice touch), Netscape 4.0 has the SGI Cosmo Player embedded in it now. I haven't been able to get this to work yet, however. Since I have a 2.0 kernel installed now I can try some of the other VRML browsers available. Maybe I'll get to that next month. |
|
||
|
On Tuesday I arrived 1/2 hour early to take the 3D Animation Workshop. I was about 20th in line of 100 or so, but somehow managed to miss getting a little blue ticket. Despite the people at the door having seen me there for 30 minutes waiting (before others had showed up) I still didn't get in. I was very pissed. This class was one of my prime reasons for my going to SIGGRAPH. Hint: if you get in line at SIGGRAPH, make sure you check with the people in front of you to see if you need to have some special form, ticket, or sacrificial offering to get in.
My fallback course was the GUI/Multimedia class. There really wasn't much multimedia discussion - mostly it covered how to design GUI intefaces. Lots of design criteria which I'd learned by fire long ago. When they finally did get around to multimedia they talked about the lack of standards and how most applications are reinventing GUI rules. This was my assessment before going to the class, but it was nice to have it reinforced by someone who studies such things for a living. Next I skipped out to Mark Kilgard's OpenGL w/Windowing systems class. Pretty good stuff. Brian Paul talked about MesaGL a little as well as some portability issues. Both are very nice guys - I chatted with them a bit after the class. One thing Mark mentioned was that there arent' any toolkits specifically built with OpenGL, which makes sense. There is an overhead in creating widgets using OpenGL that would make it unsuitable for most applications. Instead, OpenGL is integrated into applications using some other toolkit, like Motif, XForms, or Tk, using a toolkit specific OpenGL-capable widget. Later on I stumbled into the Java3D class for a few minutes. Looks interesting but I didn't get too many details. Sun is saying a beta release of a sample implementation of the specification is due out in December of 1997 but the course speakers said they hoped to have it out much sooner. They also expect that since the specification is public and being openly developed that sample implementations from non-Sun sources are likely to show up before the Sun release. Or at least they expect that - they didn't have any information on any specific implementations. At this point I haven't heard of any Java3D announcements from my usual sources. I talked to a couple of recruiters at the career fair, mostly just to get a feel for what companies are looking for these days. They mentioned that the best way people can avoid getting lost in the crowd of candidates at the fair is to submit resumes based on job postings from the corporate web sites. If you go next year looking for work, check out some of the participating companies job listings before heading to the career fair. First day of the show for me was Wednesday. It looked more like a cross between a theme park ride and a disco, especially when Intel rolled out their MMX "clean-room dancers". SGI offered a 1/2 hour demo ride with their O2 systems. Cute demo but really didn't give a good feel for what you were really buying. After talking to some of the show staff and taking the demo ride I still don't know exactly what applications come with the stock O2 box. The $4995 price offered to conference participants wasn't bad, however. Certainly compares well with a comparably equipped PC running NT. There is a freeware/shareward CD available for O2 developers according to one of the engineers I talked to, but I didn't see it. The SGI O2 demo showed me one thing which I had hoped I'd find out from the show: how to create multimedia applications. In fact, after the demo a White Paper was passed out explaining how the demo was put together. Some items, like the networking that allowed real-time texture mapping of live video, are not really possible on Linux boxes with available software. But most of the rest is: OpenGL rendered in Motif widgets was used for the GUI and OpenGL and VRML were used for interactive 3D displays. OpenGL is available commercially and with MesaGL. Motif is available commercially. I'm not certain VRML is available for integration into applications via an API, but animation could be done using MPEG. There are some MPEG API's, such as MpegTV's API. ImageMagick's PlugIn distribution appears to have an MPEG library, but I don't know if it provides a decent enough API for commercial multimedia applications. After seeing the SGI demo and the VRML SIG demos I've changed my mind about VRML - its ready for prime time. I wouldn't recommend it for network applications yet, at least not Internet based applications, but for private networks (such as kiosks) or CD-based multimedia applications it could offer some unique possibilities. Wacom was at the show and a few of the staff didn't get defensive when I brought up Linux (it all depends on how non-abrasively you bring up the subject). They were even quite apologetic about not having any info on which tablets were supported by XFree86. They now have a pad that is actually a full-color flat screen - you simply draw on it like you do with the tablets. Very cool, but currently runs > $2200. Cosmo Software (new division of SGI) staff were pleasant as well, mentioning that it might be possible to provide someone with the source to port the Cosmo Player to Linux. The player (which plays VRML 2.0 scenes) is free for various other platforms. I guess they just need someone to ask for it and provide some credentials to prove they could do a decent port. Unfortunately, I'm not certain who to talk to about this. Huge crowds formed around the Apple booth right at the entrance. One demo I caught caused an OS lockup, but for the most part people were quite excited about the products. I don't know much about Mac's so didn't stay long. However, like LInux, Mac is an underdog in the OS world and I can't help but hope they survive. The one thing about this trip that stood out for me was LA itself. It was Hot. Outside. Inside. In classes. In the car. In the hotel. Everywhere. Hot. LA also has an ugly downtown compared to others I've seen. It also apparently has very few restaurants anywhere near the Convention Center. A 6 block walk in Colorado is no big deal, but a 6 block walk in LA in August....*sigh*. Food was a big problem for me. I hope the same problem doesn't exist in Orlando next year. |
|||
 |
|
Linux Graphics mini-Howto Unix Graphics Utilities Linux Multimedia Page Some of the Mailing Lists and Newsgroups I keep an eye on and where I get much of the information in this column: The Gimp User and Gimp Developer Mailing Lists. |
 |
More...
|
| © 1997 |
 |
|
 |
|
 |
|
 |
|
 |
Thats it. You now have a metallic, or perhaps shiny plastic looking, frame. I added a white background and a adrop shadow to make it stand out a little more. You can use the curves filter again to add color to the frame. The curves filter does some amazing effects if you make the curves with drastic changes in direction (steep curves).
One other hint: if you look at the edges of the the frame where it is not straight, such as the right side along the curves, the frame is sort of rough. This problem can be reduced using better settings in the curves dialog box. Don't get confused - the problem I described happens on curves of the frame, but the curves dialog is just related to adjustments to colors in the image. The dialog isn't related to non-straight lines.
|
| © 1997 by |
This is the second article in a series of 4 articles on GNU/Linux Benchmarking, to be published by the Linux Gazette. The first article presented some basic benchmarking concepts and analyzed the Whetstone benchmark in more detail. The present article deals with practical issues in GNU/Linux benchmarking: what benchmarks already exist, where to find them, what they effectively measure and how to run them. And if you are not happy with the available benchmarks, some guidelines to write your own. Also, an application benchmark (Linux kernel 2.0.0 compilation) is analyzed in detail.
GNU/Linux is a great OS in terms of performance, and we can hope it will only get better over time. But that is a very vague statement: we need figures to prove it. What information can benchmarks effectively provide us with? What aspects of microcomputer performance can we measure under GNU/Linux?
Kurt Fitzner reminded me of an old saying: "When performance is measured, performance increases."
Let's list some general benchmarking rules (not necessarily in order of decreasing priority) that should be followed to obtain accurate and meaningful benchmarking data, resulting in real GNU/Linux performance gains:
These are some benchmarks I have collected over the Net. A few are Linux-specific, others are portable across a wide range of Unix-compatible systems, and some are even more generic.
doom -timedemo demo3. Anton Ertl has setup a Web page listing results for various architectures/OS's.All the benchmarks listed above are available by ftp or http from the Linux Benchmarking Project server in the download directory: www.tux.org/pub/bench or from the Links page.
We have seen last month that (nearly) all benchmarks are based on either of two simple algorithms, or combinations/variations of these:
We also saw that the Whetstone benchmark would use a combination of these two procedures to "calibrate" itself for optimum resolution, effectively providing a workaround for the low resolution timer available on PC type machines.
Note that some newer benchmarks use new, exotic algorithms to estimate system performance, e.g. the Hint benchmark. I'll get back to Hint in a future article.
Right now, let's see what algorithm 2 would look like:
initialize loop_count
start_time = time()
repeat
benchmark_kernel()
decrement loop_count
until loop_count = 0
duration = time() - start_time
report_results()
Here, time() is a system library call which returns, for example, the elapsed wall-clock time since the last system boot. Benchmark_kernel() is obviously exercising the system feature or characteristic we are trying to measure.
Even this trivial benchmarking algorithm makes some basic assumptions about the system being tested and will report totally erroneous results if some precautions are not taken:
You can substitute the benchmark "kernel" with whatever computing task interests you more or comes closer to your specific benchmarking needs.
Examples of such kernels would be:
For good examples of actual C source code, see the UnixBench and Whetstone benchmark sources.
The more one gets to use and know GNU/Linux, and the more often one compiles the Linux kernel. Very quickly it becomes a habit: as soon as a new kernel version comes out, we download the tar.gz source file and recompile it a few times, fine-tuning the new features.
This is the main reason for proposing kernel compilation as an application benchmark: it is a very common task for all GNU/Linux users. Note that the application that is being directly tested is not the Linux kernel itself, it's gcc. I guess most GNU/Linux users use gcc everyday.
The Linux kernel is being used here as a (large) standard data set. Since this is a large program (gcc) with a wide variety of instructions, processing a large data set (the Linux kernel) with a wide variety of data structures, we assume it will exercise a good subset of OS functions like file I/O, swapping, etc and a good subset of the hardware too: CPU, memory, caches, hard disk, hard disk controller/driver combination, PCI or ISA I/O bus. Obviously this is not a test for X server performance, even if you launch the compilation from an xterm window! And the FPU is not exercised either (but we already tested our FPU with Whetstone, didn't we?). Now, I have noticed that test results are almost independent of hard disk performance, at least on the various systems I had available. The real bottleneck for this test is CPU/cache performance.
Why specify the Linux kernel version 2.0.0 as our standard data set? Because it is widely available, as most GNU/Linux users have an old CD-ROM distribution with the Linux kernel 2.0.0 source, and also because it in quite near in terms of size and structure to present-day kernels. So it's not exactly an out-of-anybody's-hat data set: it's a typical real-world data set.
Why not let users compile any Linux 2.x kernel and report results? Because then we wouldn't be able to compare results anymore. Aha you say, but what about the different gcc and libc versions in the various systems being tested? Answer: they are part of your GNU/Linux system and so also get their performance measured by this benchmark, and this is exactly the behaviour we want from an application benchmark. Of course, gcc and libc versions must be reported, just like CPU type, hard disk, total RAM, etc (see the Linux Benchmarking Toolkit Report Form).
Basically what goes on during a gcc kernel compilation (make zImage) is that:
Step 2 is where most of the time is spent.
This test is quite stable between different runs. It is also relatively insensitive to small loads (e.g. it can be run in an xterm window) and completes in less than 15 minutes on most recent machines.
Do I really have to tell you where to get the kernel 2.0.0 source? OK, then: ftp://sunsite.unc.edu/pub/Linux/kernel/source/2.0.x or any of its mirrors, or any recent GNU/Linux CD-ROM set with a copy of sunsite.unc.edu. Download the 2.0.0 kernel, gunzip and untar under a test directory (tar zxvf linux-2.0.tar.gz will do the trick).
Cd to the linux directory you just created and type make config. Press <Enter> to answer all questions with their default value. Now type make dep ; make clean ; sync ; time make zImage. Depending on your machine, you can go and have lunch or just an expresso. You can't (yet) blink and be done with it, even on a 600 MHz Alpha. By the way, if you are going to run this test on an Alpha, you will have to cross-compile the kernel targetting the i386 architecture so that your results are comparable to the more ubiquitous x86 machines.
This is what I get on my test GNU/Linux box:
186.90user 19.30system 3:40.75elapsed 93%CPU (0avgtext+0avgdata 0maxresident)k
0inputs+0outputs (147838major+170260minor)pagefaults 0swaps
The most important figure here is the total elapsed time: 3 min 41 s (there is no need to report fractions of seconds).
If you were to complain that the above benchmark is useless without a description of the machine being tested, you'd be 100% correct! So, here is the LBT Report Form for this machine:
LINUX BENCHMARKING TOOLKIT REPORT FORM
CPU
===
Vendor: AMD
Model: K6-200
Core clock:208 MHz (2.5 x 83MHz)
Motherboard vendor: ASUS
Mbd. model: P55T2P4
Mbd. chipset: Intel HX
Bus type: PCI
Bus clock: 41.5 MHz
Cache total: 512 Kb
Cache type/speed: Pipeline burst 6 ns
SMP (number of processors): 1
RAM
===
Total: 32 MB
Type: EDO SIMMs
Speed: 60 ns
Disk
====
Vendor: IBM
Model: IBM-DCAA-34430
Size: 4.3 GB
Interface: EIDE
Driver/Settings: Bus Master DMA mode 2
Video board
===========
Vendor: Generic S3
Model: Trio64-V2
Bus: PCI
Video RAM type: 60 ns EDO DRAM
Video RAM total: 2 MB
X server vendor: XFree86
X server version: 3.3
X server chipset choice: S3 accelerated
Resolution/vert. refresh rate: 1152x864 @ 70 Hz
Color depth: 16 bits
Kernel
======
Version: 2.0.29
Swap size: 64 MB
gcc
===
Version: 2.7.2.1
Options: -O2
libc version: 5.4.23
Test notes
==========
Very light system load.
RESULTS
========
Linux kernel 2.0.0 Compilation Time: 3 m 41 s
Whetstone Double Precision (FPU) INDEX: N/A
UnixBench 4.10 system INDEX: N/A
Xengine: N/A
BYTEmark integer INDEX: N/A
BYTEmark memory INDEX: N/A
Comments
=========
Just tested kernel 2.0.0 compilation.
Again, you will want to compare your results to those obtained on different machines/configurations. You will find some results on my Web site about 6x86s/Linux, in the November News page.
This of course is pure GNU/Linux benchmarking, unless you want to go ahead and try to cross compile the Linux kernel on a Windows95 box!? ;-)
I expect that by next month you will have downloaded and tested a few benchmarks, or even started writing your own. So, in the next article: Collecting and Interpreting Linux Benchmarking Data
There are quite a few FTP clients available for Linux these days. Several of them are X programs, but why incur the overhead of running an X FTP client? Downloading a file is not a very interactive process. Usually an FTP download is a process running in the background, which just needs to be checked every now and then.
On the other hand, using the basic command-line FTP program is not much fun unless you enjoy typing complete pathnames and filenames. A great improvement is the classic ncurses-based client NcFtp, written by Mike Gleason. This program has a well-designed bookmarking facility and supports the FTP "reget" command, which allows resumption of interrupted downloads. Unfortunately, file and directory names still must be typed in, though NcFtp does support shell-like completion of filenames in both local and remote directories.
Recently I came across a new FTP client called cftp. It is being developed by Dieter Baron, and though it is still a relatively new program, it has been working superbly for me.
Cfpt isn't a showy application. It uses the termcap library, which allows it to show a reverse-video modeline displaying the current host and directory, as well as the number of bytes transferred. Otherwise it resembles a ls -l listing of files in the remote directory. The default keybindings are fairly intuitive: d downloads a file, v views a remote file using your default pager, and the left and right arrow keys function like they do in the Lynx text-mode web-browser: the left arrow-key takes you back to the previous directory, and the right arrow-key descends into the subdirectory under the cursor. The other key-bindings (as well as user options) can be viewed during a session by typing :help. The colon as a prefix to a command will be familiar to anyone who has used the vi editor or one its clones. Vi and Emacs motion-keys can also be used instead of the arrow-keys.
What impressed me was the quickness with which the program starts up and makes the connection; before you know it a directory listing is displayed. This is a small and efficient little program which nevertheless has convenient keyboard commands. It's just the thing for making a quick check of an FTP site, perhaps reading a few *.lsm or README files, then pressing q which tells cftp to first log off, then quit. Directory listings displayed during a session are cached in memory, so returning to a previously-viewed directory is near-instantaneous.
Many FTP programs are in effect front-ends for the command-line FTP utility, just as many mail clients use sendmail to do the actual mail-handling. In contrast, cftp uses its own built-in FTP routines; this may be one reason for its speed. Instead of passing an FTP command through a GUI layer before handing it to the actual FTP executable, cftp is talking directly with the remote server.
There are two files which cftp reads when starting up, ~/.cftprc and ~/.netrc. The ~/.cftprc file can contain personal changes to default settings, such as keybindings. Aliases for oft-visited sites can be entered into this file as well. The line
alias sun ftp://sunsite.unc.edu/pub/Linux/Incoming
enables quick access to the site by merely typing cftp sun.
The ~/.netrc file is used by the default FTP program, as well as the FTP facilities provided by GNU Emacs' dired and XEmacs' EFS. Cftp refers to this file as well. An entry like this:
default login anonymous password [your e-mail address]
will save typing login info for sites which allow anonymous access, and if you access a site for which you have a username and password, lines like these:
machine [hostname] login [login-id] password [password] macdef init cd /[directory to change to]
When I began this review version 0.7 was the latest version; since then version 0.8 has been released, which contains several new features:
As I write this cftp-0.8.tar.gz is the current version; the latest release can be found at the cftp home FTP site, or via the WWW at this site.
I enjoyed trying this small application and find myself using it often. It's a small download and should compile easily if you have libtermcap installed. If you do try it, let know what you think of it.
The traditional form of unix documentation is the manual-page system, which uses the man command in conjunction with the Groff text formatter to display manual pages (with your default pager) on a terminal screen. This system is rather long in the tooth, but is still in widespread use because it both works well and doesn't require a windowing system. The man-page directory structure (with a directory corresponding to each directory of executables) is pretty well standardized, ensuring that when new software is installed the corresponding man-page(s) have a place waiting for them in the hierarchy.
For the past couple of years Thomas Phelps, of the University of California at Berkeley, has been writing and rewriting a Tcl/Tk based man-page reader called TkMan. As John Ousterhout has released the successive versions of Tcl and Tk TkMan has been updated to make use of the expanded capabilities of the two toolkits. Soon after the release of Tcl/Tk 8.0 this past August, TkMan 2.0 was released; it's a major release with several new features, thus this review.
TkMan is a super-charged reader which can access and search your man-pages in a variety of useful ways, and then display them in a nicely-formatted and very configurable fashion. Here is a sampling of what TkMan can do:
It is all too easy to end up with superfluous copies of man-pages on a Linux system. If your man-pages are gzipped, an upgrade to a new version of a program will install the new page, but the new one won't over-write the old because the old one has the .gz suffix, and thus the filename is different. TkMan offers a means of keeping track of duplicate man-pages; wnen a page is displayed, the title of the page in the menu-bar will have drop-down entries showing the paths of any other pages with the same name. Selecting one of these will load the page, and if it's an older version or just an exact duplicate it can be deleted. Here's a screenshot of a typical window:

This screenshot shows a man-page in its "folded" state; the right-pointing triangles are sections with hidden text. A mouse-click will expand them.
The latest version of TkMan relies on Tcl8.0 and Tk8.0, so if you want to try it out this may be a good time to upgrade. Recent versions of Tcl/Tk compile easily "out-of-the-box", so this shouldn't present too much of a problem. Unfortunately, especially if you've recently compiled and installed the 8.0 versions (and deleted the source), TkMan needs one patch to be applied to one of the Tk8.0 source files in order to function. The Tk source then needs to be recompiled. Thomas Phelps attempted to convince the Tk developers to include his patch in the distribution, but was unsuccessful. The patch adds outlining to the Tk text display functions. I've run several other applications which rely on Tk8.0 and the patch so far hasn't caused any problems.
TkMan also depends on the services provided by PolyglotMan (formerly Rman), also written by Thomas Phelps. PolyglotMan is a separate program which can reverse-compile or translate man-pages from their native Nroff or Groff format to a variety of other formats, such as HTML, SGML, LaTeX, TkMan's native format, and the Perl pod format, among others. This should be compiled and installed first, as the TkMan makefile needs to contain PolyglotMan's path.
TkMan is entirely a Tcl/Tk program, so it doesn't need to be compiled. The makefile instead rewrites several of the Tcl files, adapting them to your system's paths, before copying them to (by default) /usr/local. The makefile is well-commented and easy to adapt to your system.
The current versions of both TkMan and PolyglotMan can be downloaded from the home site.
TkMan isn't the sort of man-page reader you'd want to fire up just to check the syntax of a command, but if you're needing to refer to several man-pages in a session it can be a great convenience. A history of pages you have viewed is stored as you work, and it can be accessed from a dynamically updated drop-down menu. The overview of all man-pages in a section can be interesting, too. It's easy to forget just how many of these pages there are, and sometimes just seeing the title of a program or command in the listing can spark curiousity. It's easy to get in the habit of using just a small subset of a command's capabilities; several times I've noticed a page listed for a command I've used frequently but never thought to investigate. Even more times I've seen listings for programs I long ago deleted!
There are probably more features in TkMan than most people will ever use, but this increases the odds that the one which suits you is included. This seems to be a very high-quality program, and it will run on just about any flavor of unix out there.
Linux Programming Guide : Linux Documentation Project.
Kernel Hacker's Guide : Linux Documentation Project.
Pthreads posix threads html pages
Inside Windows NT, Helen Custer, Microsoft Press.
Readings on Microsoft Windows and WOSA, Microsoft Press.
Programming Windows NT Unleashed: Hamilton, Williams.
Operating Systems : William Stallings.
The Magic Garden Explained : Goodheart, Cox.
Windows NT Magazine : July 1997 : The NT Scheduler.
Linux Journal : April 1997 : Threads Programming, Martin McCarthy.
Linux man pages for : ps, vmstat, fuser, kill, procinfo, procmeter, free, readprofile, profil, nice, renice, pstree, top.
Linux source code.
Lecture notes for 85349 Operating Systems : David Jones / Steve Smith, CQU
Each time a process is removed from access to the processor, sufficient information on its current operating state must be stored such that when it is again scheduled to run on the processor it can resume its operation from an identical position. This operational state data is known as its context and the act of removing the process's thread of execution from the processor (and replacing it with another) is known as a process switch or context switch.
The distinction is made here between the condition where a process is removed from the processor completely and is replaced by another process (a process switch) and the case where the process state is stored while execution is interrupted temporarily (a context switch). Note that a process switch performs a superset of the operations required for the context switch. The latter case may be when an external interrupt is serviced or when a system call necessitates a switch from user mode to system mode. In the case of the process switch much more information must be saved in order to later restore the process context than in the second case where the process remains resident in memory while it's thread of execution is interrupted.
The context of a process includes its address space, stack space, virtual address space, register set image (e.g. Program Counter (PC), Stack Pointer (SP), Instruction Register (IR), Program Status Word (PSW) and other general processor registers), updating profiling or accounting information, making a snapshot image of its associated kernel data structures and updating the current state of the process (waiting, ready, etc).
This state information is saved in the process's process control block which is then moved to the appropriate scheduling queue. The new process is moved to the CPU by copying the PCB info into the appropriate locations (e.g. the program counter is loaded with the address of the next instruction to execute).
|
Linux
|
|
Windows NT
|
|
Each process's context is described by a task_struct structure. The task_struct holds data such as the scheduling policy, scheduler priority, real time priority, processor allowed time counter, processor registers, file handles (files_struct), virtual memory (mm_struct).
|
|
The kernel maintains a view of a process or thread known as a kernel process object or kernel thread object respectively. These contain just the information the kernel needs to effectively switch between processes or threads.
|
|
When a process switch is made the scheduler saves the process's task_struct and replaces the current tasks pointer with a pointer to the new process's task_struct, restoring its memory access and register context. This may be assisted by hardware.
|
|
The kernel makes a context switch by pushing context information onto the current kernel mode stack, for a process it also saves the address of it's page table directory so that it's address space is maintained.
|
Each process has some form of associated Process Identifier, (PID) through which it may be manipulated. The process also carries the User Identifier (UID) of the person who initiated the process and will also have group identifier (GID).
The UID is used to decide privilege to perform operations on resources such as files. Processes will normally belong to one or more process groups. A group identifier (GID) is used by the kernel to identify privileges allocated to a group of users and hence their created processes. Groups allow subsets of the available privileged operations (such as granting of access to files, printers, ability to create directories) to be restricted to members of a particular group only, with non members of the group being excluded from performing those operations.
| Linux | Windows NT | |
| On a Unix derivative system such as Linux the PID, UID and GID identifiers equate to simple integers which are associated with processors as part of their Process Control Block. |
A process handle is used for the process identifier. A process handle is a special case of an Object handle, where object handles may reference files, devices and processes.
|
|
|
On Unix processes maintain a parent-child relationship where the process that initiates a sub process becomes a parent to it?s child via a fork and optional exec operation to first clone the parent process and then replace it with a new executable process image. Due to this relationship it is possible to terminate all child processes by sending a KILL signal to the parent. All of the processes in the system are accessed via a doubly linked list whose root is the init process?s task_struct data structure.
|
Windows NT processes do not maintain a parent-child relationship. Instead a process maintains an Object table to hold handles of other processes.
When a new process is created it inherits all object handles from its creator that were previously marked with the inheritance attribute.
|
|
| Access to resources is decided as a result of the combination of resource defined permissions and a combination of the UID, GID (or effective UID and GID) under which a process is running. The owner of a resource or the administrator may grant access to a user or group of users. | The NT Object Manager attaches an access token to a process which is checked against a resource's permissions to decide what granted access rights the process is allowed. The owner of a resource or the administrator may grant access permissions to a user or group of users. |
Example : a Linux device may be allocated the bitmask permissions of crwxr-x---, may be owned by the root user (UID=0) and be allocated to the admin group. The allocated permissions of the device indicate that a process operating for the root user will have read, write and execute permissions on the device. A process operating with an effective GID of the admin group will have read and execute permissions, with other users being prevented from carrying out any operations on the device.
When a developer writes, compiles and links a programme it may be stored on a computer disk as a file in the disk file system. This file is created in a predefined format that the operating system or operating system shell will recognise as an executable programme.
When a programme is run it is instantiated in memory, taking up system resources such as memory for data structures, file descriptors and providing at least one thread of execution which defines the current state and subsequent required operations for the process. The current executing program, or process, has total use of the microprocessor while in it's run state. A process will use files within the filesystems and may access the physical devices in the system either directly or indirectly.
A process may operate in one of two modes which are known as 'user' mode and 'system' mode (or kernel mode). A single process may switch between the two modes, i.e. they may be different phases of the same process. Processes defaulting to user mode include most application processes, these are executed within an isolated environment provided by the operating system such that multiple processes running on the same machine cannot interfere with each other's resources. A user processs switches to kernel mode when it makes a system call, generates an exception (fault) or when an interrupt occurs (e.g. system clock). At this point the kernel is executing on behalf of the process. At any one time during its execution a process runs in the context of itself and the kernel runs in the context of the currently running process. This is shown in Figure 1.
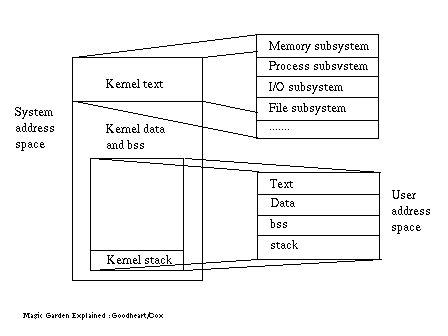
Processes operating in kernel mode are privileged and are granted access to all computer resources (such as all available memory) free of the restrictions applied to user mode processes. The distinction between a process in either user or kernel mode may be supported by the hardware which serves to enforce the privilege rule and so protect the computer system from undue damage or failure due to ill behaved user processes.
Though the basic concepts are similar, different operating systems implement process management in different ways.
| Linux | Windows NT | |
|
On the Linux operating system privileged services are largely implemented by a single monolithic kernel. The kernel provides the central services required to support the successful operation of the computer.
The Linux kernel can also have a number of loadable modules which may serve to supplement its central functions e.g. by the addition of a new file system. As the kernel carries out a number of responsibilities within a single entity it is commonly known as a macrokernel architecture. |
The Windows NT operating system is based on a derivative of a layered operating system (such as VAX VMS) and a true client/server operating (such as Mach) microkernel architecture, where the central kernel process carries out only the most basic tasks in the most efficient manner possible.
Associated with the microkernel are a number of privileged processes collectively known as the Executive which operate in their own separate process subsystems. These includes (amongst others) a dedicated Process Manager, Object Manager and Virtual Memory manager to provide specialised services as required to support the establishment of processes and their resources. |
Every user process runs in its own address space (typically 3Gbytes on a 32 bit processor) isolated from the address space of other active processes. From the point of view of the individual process it also has complete access to the processor(s) of the machine on which it is running i.e. it has it's own virtual machine on which it runs, under the control of the operating system but independent from other processes.
Processes operate within their own virtual address space and are protected by the operating system from interference by other processes. By default a user process cannot communicate with another process unless it makes use of secure, kernel managed mechanisms. There are many times when processes will need to share common resources or synchronise their actions. One possibility is to use threads, which by definition can share memory within a process. This option is not always possible (or wise) due to the many disadvantages which can be experienced with threads. Methods of passing messages or data between processes are therefore required.
Linux supports the following methods of communication. System V IPC refers to the version of Unix in which the concepts noted below were first introduced.
|
Signals
|
Signals are used to signal asynchronous events between processes. A process may implement a signal handler to carry out required when an event occurs or may use the system default actions. Most signals can be ignored or blocked, though the KILL signal cannot be ignored and will result in a non clean process exit. |
|
UNIX pipes
|
A pipe connects the standard output of one process to the standard input of another. They provide a method of one-way communication between processes in a parent-child relationship and for this reason may be called half duplex pipes. |
|
Named Pipes (FIFOs)
|
Named pipes appear similar to regular pipes but are implemented as device special First In-First Out (FIFO) files in the file system. It is not necessary for processes to maintain a parent-child relationship for them to communicate via named pipes. Named pipes are persistent and may be reused after their initial setup. |
| System V IPC Message Queues | Message queues consist of a linked list within the kernel's addressing space. Messages are added to the queue sequentially and may be retrieved from the queue in several different ways. |
| System V IPC Semaphores | Semaphores are counters used to control access to shared resources by multiple processes. They are most often used as a locking mechanism to prevent processes from accessing a particular resource while another process is performing operations on it. Semaphores are implemented as sets, though a set may have a single member. |
|
System V IPC Shared Memory
|
Shared memory is a mapping of an area of memory into the address space of more than one process. This is the fastest form of IPC as processes do not subsequently need access to kernel services in order to share data. |
| Full-duplex pipes (STREAMS) | STREAMS were introduced by AT&T and are used for character based I/O within the kernel and between it?s associated device drivers as a full duplex transfer path between processes. Internally pipes may be implemented as STREAMS. |
| Remote Procedure Call (RPC) | A network inter-process connection protocol based on Sun Microsystems' RPC standard. |
| Networking sockets (Berkeley style) | Sockets allow local or network connection between processes. Socket names are implemented within a domain. In the UNIX domain a socket is given a path name within the file system. Other processes may use that name to communicate. |
| Events or Event Pairs | Event handles may be inherited, passed on creation or duplicated for a process. Event handles may optionally have names and are signalled using the SetEvent call. |
| Anonymous Pipes | Used primarily for communication between related processes. Anonymous pipes cannot be used over a network. |
| Named Pipes (FIFOs) | Named pipes are similar to anonymous pipes but may be referenced by name rather than handle, may be used over a network and can use asynchronous, overlapped I/O. |
| Semaphores | Like Linux, Windows NT semaphore objects are implemented as counters which act as guardians over a section of code or resource. |
| Shared Memory | A section object is a Win32 subsystem object which is made available as a file mapping object which two or more processes may share. One thread creates the section object and other threads obtain handles to it. |
| Remote Procedure Calls (RPCs) | An implementation of the Distributed Computing Environment (DCE) standard for calling processes over a network. |
| Local Procedure Calls (LPCs) |
A facility similar in usage to RPC but in fact being a cut down version that can act only on a local computer to perform efficient message passing between client/server processes using kernel provided mechanisms. There are three basic choices :
|
| STREAMS | An implementation of the Unix System V driver environment used in networking. |
On Linux there are a number of utilities which allow the System Administrator to examine the status of processes and to adjust their relative priorities or change their operational status. Some of these capabilities can be demonstrated by examining one programme available for the Linux OS : the Apache httpd daemon : a freely available web server. In the following prints of screen outputs some columns have been ommitted where they do not affect the demonstration being given.
From the following it can be seen that the size of the http daemon is 142699 bytes on the disk. Within the ELF file there are 108786 bytes of code, 4796 bytes of initialised data and 19015 bytes of uninitialiased data.
orion-1:# ls -l httpd
-rwxr-x--- 1 root root 142699 Oct 5 1996 httpd*
orion-1:# size httpd
| text | Data | bss | dec | hex | filename |
| 108786 | 4796 | 19015 | 132597 | 205f5 | httpd |
orion-1:# objdump --headers httpd
httpd: file format elf32-i386
Sections: < Some sections excluded for clarity >
0 .interp 00000013 080000d0 080000d0 000000d4 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
8 .text 00014544 08001ce0 08001ce0 00001ce0 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
10 .rodata 000047ac 08016238 08016238 00016238 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
11 .data 00001050 0801b9e8 0801b9e8 0001a9e8 2**2
CONTENTS, ALLOC, LOAD, DATA
16 .bss 00004a47 0801ccb0 0801ccb0 0001bcb0 2**4
ALLOC
17 .stab 000004f8 00000000 00000000 0001bcb0 2**2
CONTENTS, READONLY, DEBUGGING
orion-1:# ldd -r httpd
libc.so.5 => /usr/local/lib/libc.so.5 (0x4000a0)
The daemon is started at system boot time and was sleeping (S) when its status was checked, it is consuming very little CPU time :
orion-1:# ps -fc | grep httpd
PID TTY STAT TIME COMMAND
90 ? S 0:00 httpd
A printout of the tree of all processes running on the computer and their interrelationships shows that the httpd has init as its parent process, this is typical of a Unix daemon process. It has also created three child processes which it now controls, presumably to listen for http connections.
orion-1:# pstree
|-bash--script--script--bash--script--script--bash--pstree
|-bash
|-crond
|-gpm
|-httpd--3*[httpd]
|-inetd
|-kflushd
|-klogd
|-kswapd
|-lpd
|-rpc.mountd
|-rpc.nfsd
|-rpc.portmap
|-sendmail
|-syslogd
`-update
It can be seen that the resident memory footprint (Resident Set Size (RSS)) of the httpd process is 528 kilobytes whereas its overall size in virtual memory is 1012 Mb. It can be seen that the process runs with a User ID of 0 (owned by the administrator (root)) and that it is running at the default priority of 0 (-20 being maximum real-time and 20 being the lowest priority). The SW< status for the kernel swap daemon (kswapd) process shows that it is sleeping, has no resident pages and has a priority less than 0.
orion-1:# ps -cl1,2,3,90
F UID PID PPID PRI NI SIZE RSS WCHAN STAT TTY TIME COMMAND
100 0 1 0 0 0 844 328 c01115c9 S ? 0:03 init [5]
40 0 2 1 0 0 0 0 c0111a38 SW ? 0:00 (kflushd)
40 0 3 1 -12 -12 0 0 c0111a38 SW< ? 0:00 (kswapd)
140 0 90 1 0 0 1012 528 c0119272 S ? 0:00 httpd
Looking at the virtual memory performances of the process it can be seen that the httpd has had 23 major page faults where a page fault represents an action to load a page of text from disk or buffer cache. The text (code) resident set size (TRS) is 24 kilobytes which suggests a code page size of 1024 bytes when viewed in association with the page fault number. The Data Resident Size is 108 kilobytes, giving a total SIZE of 132 kilobytes. The process shares 115 kilobytes with other processes (this may represent the standard 'C' shared library).
orion-1:# ps -cmp1,2,3,90
| PID | MAJFLT | MINFLT | TRS | DRS | SIZE | SWAP | RSS | SHRD | COMMAND |
|
|
|
|
|
|
|
|
|
|
kflushd |
|
|
|
|
|
|
|
|
|
|
kswapd |
|
|
|
|
|
|
|
|
|
|
init |
|
|
|
|
|
|
|
|
|
|
httpd |
The system administrator can re-prioritise the httpd process by changing it's NICE level. Here the priority of process 90 (httpd) is made higher by 10. Only the administrator can change priorities in a negative direction as shown. This prevents inexperienced users from overloading the CPU and also protects the system from hackers.
orion-1:# renice -10 90
90: old priority 0, new priority -10
The new priority level can now be seen, although on this system the httpd is idle, receiving no web access requests so it would not consume much more CPU.
orion-1:# ps -cl
| UID | PID | PRI | PPID | NI | SIZE | RSS | STAT | TIME | COMMAND |
|
|
|
|
|
|
844
|
328
|
S | 0:03 | init [5] |
|
|
|
|
|
|
0
|
0
|
SW | 0:00 | (kflushd) |
|
|
|
|
|
|
0
|
0
|
SW< | 0:00 | (kswapd) |
|
|
|
|
|
|
1012
|
528
|
S < | 0:00 | httpd |
The system is now loaded somewhat by running some CPU intensive shell scripts. The virtual memory statistics of the computer are examined every 5 seconds for five iterations.
The procs field shows that on average 2 processes are waiting for CPU run time (r) and on iteration 3 two processes are in uninterruptable sleep. There is no swapping activity going on as the processes are small enough to be fully resident in memory.
There is however I/O activity as blocks of data are brought in (bi) and sent out (bo) to I/O devices. The 'system' fields show that many interrupts are occurring per second (in) as well as many context switches (cs). The first iteration gives the average history since the last system reboot, whereas the subsequent four readings are for time now. It can be seen that the CPU is never idle (id) and is spending around 35% of its time in user mode and 65% of its time performing privileged operations in system mode.
This report is consistent with the known operations being performed : I/O intensive disk reads : the Linux 'find' command searching the disk.
orion-1:# vmstat 5 5
|
|
|
|
|
|
|
|||||||||||||
| r | b | w | swpd | free | buf | si | so | bi | bo | in | cs | us | sy | id | ||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
129 |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
It is possible to probe the Linux kernel and find which operations are consuming the most CPU load. When this is done it is seen that the kernel is spending most of it's time dealing with the directory cache, file system and writing to the console. The system scheduling process is only the twentieth most active process on the list.
To be able to read the profiling information from the kernel it must first be compiled with profiling enabled.
orion-1:# readprofile | sort -nr | head -20
| CLK_TCK | Function | Normalised load |
| 67649 | total |
0.0858
|
| 7796 | d_lookup |
54.1389
|
| 5425 | ext2_readdir |
3.5319
|
| 5034 | scrup |
7.8168
|
| 4573 | filldir |
14.8474
|
| 4481 | find_inode |
86.1731
|
| 2849 | ext2_check_dir_entry |
15.8278
|
| 2581 | getname |
7.9660
|
| 1885 | getblk |
2.2440
|
| 1665 | sys_newlstat |
6.8238
|
| 1546 | lookup_dentry |
5.1533
|
| 1542 | do_con_write |
0.3119
|
| 1425 | get_hash_table |
9.6284
|
| 1422 | cp_new_stat |
4.5577
|
| 1323 | __namei |
10.3359
|
| 1270 | system_call |
19.8438
|
| 1231 | ext2_getblk |
2.2140
|
| 1084 | raw_scan_sector |
1.8951
|
| 1077 | sys_getdents |
3.0597
|
| 973 | schedule |
1.2102
|
The Linux 'ps' command takes its information from the /proc virtual-file system (VFS) which is a disk image of the process structures as controlled by the kernel. Note that the VFS is a direct mirror of the kernel data structures and does not actually reside on disk, although it appears to do so when acessed with normal Linux commands.
Looking directly at the httpd process in the /proc file system, all of the information given by the administrative tools can be obtained, though often in a less user friendly format. The following is a direct dump of the httpd status table, with comments added for explanation :
orion-1:# cat /proc/90/status
State: S (sleeping)
Pid: 90 # Process ID
PPid: 1 # Parent Process (init)
Uid: 0 0 0 0 # User ID (root)
Gid: 65535 65535 65535 65535 # Group ID
VmSize: 1012 kB # Total virtual memory
VmLck: 0 kB # Total locked
VmRSS: 512 kB # Text Resident Set Size
VmData: 276 kB # Virtual Memory Data size
VmStk: 20 kB # Stack size
VmExe: 108 kB # Executable
VmLib: 576 kB # Library
SigPnd: 00000000 # Signals pending
SigBlk: 00000000 # Signals blocked
SigIgn: 80000000 # Signals ignored
SigCgt: 00006441 # Signals caught
The following are all the signals recognised by the Linux operating system, they are enumerated starting at zero (i.e. SIGHUP is 0, SIGKILL is 9, etc) :
orion-1:# fuser -l
So far we have considered machines which have only a single processor (known as the Central Processor Unit). Becoming more common these days are multi-processor machines which may have a number of processors (for example four or thirty two) which may provide true concurrency to multiple tasks running on the machine. On these machines the scheduler will arrange for the execution of processes to occur in a manner selected to take maximum advantage of the available processing capacity. Asymmetric multiprocessing (ASMP) operating systems typically select one processor to run operating system code, with the other processors running user jobs. Problems with such systems include a lack of portability of the operating system to other platforms. Symmetric multiprocessing systems (SMPs), which include Linux, Sun's Solaris and Windows NT each allow the operating system to run on any or all of the available processors, sharing memory between them. The central unit for execution on such machines is the thread, with multiple threads of a single process having the possibility to be spread across multiple processors. The scheduling task on an SMP computer can become extremely complex.
It would be extremely inefficient for a single process to have complete use of the processor from the time of its start-up to the completion of its operations. One reason for this is that most processes must pause very often to wait for input such as data from I/O devices, keyboard input or disk accesses. In the simplest case therefore a large amount of useable CPU time would be wasted due to this blocking. This would result in a large overall time to carry out a number of independent tasks. The processor must also handle asynchronous software or hardware interrupts which may require high priority service for a short period, requiring the currently active process to be displaced from the processor while the interrupt is handled before normal processing can be resumed. Such interrupts may be caused by events such as an input buffer becoming full which, if not serviced in a timely manner could result in an unrecoverable loss of data.
To increase throughput efficiency most modern operating systems implement a method to allow many processes to be available for running at any one time. Their access to the processor is interleaved and, as the speed of modern processors is high compared to slower I/O devices, it is possible to provide a pseudo real-time response to an active user of the system for any particular process when in reality many processes are being run. The total time to complete a number of tasks will also be less due to less time being wasted waiting for external inputs. Interrupt handling is facilitated as well as this round robin scheduling of normal processes.
This procedure is known as Multitasking (or Multiprogramming) and its sequencing is controlled by an operating system service called the scheduler. Some operating systems (e.g. Windows 3.1) just rely on the process itself giving up the processor at regular intervals or when waiting on I/O. This approach is known as co-operative multitasking and it can have many problems as, if the process does not give up the CPU at the expected time failure can occur. In this case all other processes will be blocked and there will be no way for the operating system to gain control of the processor, most likely resulting in a system lockup or crash.
A better approach, and that used in most operating systems designed for efficient multitasking is that of pre-emptive multitasking . In this case it is the operating system that decides which process gets access to the CPU. It can allocate CPU time to a process or remove the process from the CPU as required. Each candidate process gets access to the CPU for a short time (known as a quantum) based on their allocated priority, their process class and also their voluntary release of the processor as they wait for external input.
Allowing multiple processes access to the same resources in a time sliced manner or potentially consecutively in the case of multiprocessor systems can cause many problems. This is due to the need to maintain data consistency, maintain true temporal dependencies and to ensure that each thread will properly release the resource as required when it has completed its action.
Concurrent processes in multitasking and / or multiprocessing operating systems must deal with a number of potential problems
| Process starvation or indefinite postponement | A low priority process never gets access to the processor due to the higher effective processor access of other processes. Solution is to cause processes to 'age' or decline in priority as they use up CPU quanta. |
| Process deadlock | Two or more processes are competing for resources, each blocking the other. |
| Race Conditions | The processing result depends on when and how fast two or more processes complete their tasks. |
The data consistency and race condition problems may be addressed by the implementation of Mutual Exclusion and Synchronisation rules between processes whereas starvation is a function of the scheduler.
There are a number of synchronisation primitives :
| Events | A thread may wait for events such as the setting of a flag, integer, signal or presence of an object. Until that event occurs the thread will be blocked and will be removed from the run queue. |
| Critical Sections | These are areas of code which can only be accessed by a single thread at any one time. |
| Mutual Exclusions | mutexes are objects that ensure that only a single thread has access to a protected variable or code at any one time. |
| Semaphores | These are similar to mutual exclusions but may include counters allowing only a specified number of threads access to a protected variable or code at any one time. |
| Atomic operations | This mechanism ensures that an non decomposable transaction is completed by a thread before access to the same atomic operation is granted to another thread. The thread may have non-interruptable access to the CPU until the operation is completed. |
Deadlock is a permanent blocking of a set of processes that either compute for system resources or communicate with each other [MAEK87]. Deadlock may be addressed by mutual exclusion or by deadlock avoidance. Mutual exclusion prevents two threads accessing the same resource simultaneously. Deadlock avoidance can include initiation denial or allocation denial, both of which serve to eliminate the state required for deadlock before it arises.
Both Linux and Windows NT solve these problems in different ways. Windows NT has functions which equate to all of the above instances. Both implement multiprocessor mutual exclusion mechanisms called spin locks which effectively stall the processor until a lock is achieved for a critical section.
Executable files are stored in a defined format on the disk, different operating systems may have different definitions for the actual format but there are generally common elements in the way they are stored. A format commonly used on Unix systems such as Linux is called Extensible Linked Format (ELF). An ELF programme consists of an ELF header, a program header table, a number of sections and an optional section header table. The header contains all the information the kernel needs to create a process image (i.e. load the programme into memory and allocate resources to prepare it for execution).
Programme code on a multitasking operating system must be re-entrant. This means it can be shared by multiple processes. To be re-entrant the code must not modify itself at any time and the data must be stored separately from the instruction text (such that each independent process can maintain its own data space).
When a programme is loaded as a process it is allocated a section of virtual memory which forms its useable address space. Within this process image there are typically at least four elements :
| Program code (or text) | The program instructions to be executed. Note that it is not necessary for the processor to read the totality of a process into physical memory when a program is run, instead by a procedure known as ?dynamic paging? the next block of instructions is loaded as required and may be shared between processes. |
| Program data | May be distinguished as initialised variables including external global and static variables, uninitialised variables (known as a bss area on Unix derivative systems). Data blocks are not shared between processes by default. |
| Stack | A process will commonly have at least two last-in, first-out (LIFO) stacks, including a user stack for user mode and a kernel stack for kernel mode. |
| Process Control Block | Information needed by the operating system to control the process. |
A scheduler is responsible for the coordination of the running of processes to manage their access to the system resources such that each candidate process gets a fair share of the available process time, with the utilisation of the CPU being maximised. The scheduler (dispatcher) must ensure that processes gain access to the CPU for a time relative to its designated priority and process class and that no process is starved of access to the CPU, no matter if it is the lowest priority task available.
A process may choose to voluntarily give up it's use of the microprocessor when it must wait, usually for some system resource or for synchronisation with another process. Alternatively the scheduler may pre-emptively remove the thread or process from the CPU at the expiry of it's allocated time quantum. The scheduler chooses which is the most appropriate process to run next.
Scheduling is an operation of the kernel, which defines the following process states :
| Linux | Windows NT | |
| Running : The process is the current system process and is on the CPU carrying out it's execution. | Running : The process (thread) is the currently active process on the CPU. | |
| Running : Ready to Run : The process is in a run queue ready to use the CPU when available. | Standby : The thread has been selected to run next by the processor, only one thread can be in this state. | |
| Waiting : interruptable : The process is waiting for a resource or event but signals are not blocked and it may be interrupted. | Ready : The thread is simply waiting to execute and is a candidate for selection by the scheduler for entering standby at the next scheduling cycle. | |
| Waiting : uninterruptable : The process is waiting for a resource or event but has disable signals such that it cannot be interrupted. | Waiting : The thread is waiting for synchronisation events, it has been directed to suspend by the environment subsystem or is waiting on I/O. | |
|
Stopped : The process has been stopped, usually by a SIGSTOP signal such as when performing debugging.
|
Transition : The thread is ready to execute but the resources it needs are not available. (e.g. the thread's kernel stack is paged out of memory). | |
| Zombie : The process has completed and is ready to die, the scheduler has not yet detected this so it?s task_struct structure is still present. | Terminated : The thread has finished executing and the object manager decides whether the thread is deleted. If the executive has a pointer to the thread it may be reinitialised and reused. |
The scheduling of tasks on the different operating systems is similar, but each OS solves the problem in it's own way :
|
Linux
|
|
Windows NT
|
|
Tasks have a priority which ranges from a setting of -20 to +20. The default priority of a task is 0 with -20 being the highest. Only the administrator can reset a process's priority to be less than 0, but normal users can adjust priorities in the positive range. This is done using the 'renice' command, though internally Linux uses a time quantum counter (in 'jiffies') to record this in the task_struct.
New processes inherit the priority of their parent. |
|
Threads have a priority which ranges from 1 to 31 with 8 being the user default and 31 being the highest. Priority 0 is reserved for system use. Only the administrator can set a processes priority to be above 15, normal users can set a process's priority in the 1 to 15 range in a two step process by first setting the process class and then setting the relative priority within the class. This is done using the Task Manager.
New processes inherit the priority of their creating process. |
|
Real time processes are supported. Any real time process will have higher priority than all non real-time processes.
|
|
Processes having priorities between 16 and 31 are real-time processes which are members of the realtime class.
time-critical and idle modifiers may move a dynamic thread's priority to the top or bottom of it's dynamic range respectively. |
|
Threads that have already received some CPU time will have lower priority than other of the same priority which have not.
|
|
Non real-time threads may be boosted in priority should (e.g.) a blocked thread receive an event if was waiting for. This boost decays over time as the thread receives CPU time.
|
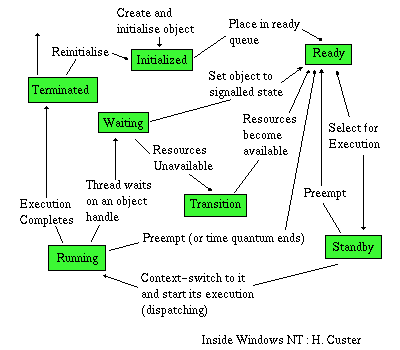
The majority of processes seen on operating systems today are single threaded, meaning there is a single path of execution within the process. Should a process have to perform many sub tasks during it's operation then a single threaded process would sequence these tasks in a serial manner, with each sub task being required to wait for the completion of the previous sub task before commencement. Such an arrangement can lead to great inefficiency in the use of the processor and in the apparent responsiveness of the computer.
An example can illustrate the advantages of having multiple threads of execution as shown in the figure. Suppose a user wants to print a document, a user process can be initiated to accept input from the operator to select the print action and start the printing action. Should the user process be required to check for further user commands subsequent to initiating the print there are two options :
(i) the process can stop the printing periodically, poll for user input, then continue printing, or
(ii) wait until printing has completed before accepting user input.
Either of these alternatives slow down printing and/or decrease responsiveness. By contrast a multi-threaded process can have many paths of execution. A multi-threaded application can delegate the print operation to a different thread of execution. The input thread and print thread then run in parallel until printing is completed.

Threads within the same task share resources such as file pointers and code segments. Swapping between threads within a process presents a much smaller overhead to the scheduler than swapping between processes. This is because less context related data must be saved to enable successful restoration of that context later. For this reason threads are often known as 'light weight processes' (LWPs) with normal processes being correspondingly known as heavyweight processes. Typically, when a thread context switch is performed, only the program counter and register set need to be saved in the PCB. Heavy-weight processes typically don?t share such resources so when heavy-weight processes context switch, all this additional info must be saved.
Although threads have many advantages as described above, they also have disadvantages, one of these being that any single 'rogue' thread within the process can cause the whole process to fail. Programming threads is also more complex than for simple processes as kernel code and libraries must have 100% re-entrant code. Special care must be taken to ensure that pre-emption cannot occur within critical sections of code within which inconsistencies could occur should another thread gain access at the wrong time. Other such problem is "what happens if a thread forks another process ?", it must be defined how threads within a process are affected in this case.
|
Linux
|
|
Windows NT
|
|
There are two types of threads: user-space and kernel-space.
User space threads consist of internal cooperative multitasking switches between sub tasks defined with a process. A thread may send a signal, perform it?s own switch or be invoked by a timer to give up the thread of execution. The user stack is then manipulated to save the thread context Switching is typically faster for user threads than kernel threads.
User threads have disadvantages in that starvation can occur if one thread does not give up the CPU. Also should a thread become blocked waiting on a resource, all other threads will be blocked as well. User threads cannot take advantage of SMP systems should such a multi processor environment be available. |
|
Similarly to its implementation of processes, Windows NT threads are implemented as Objects.
Certain attributes of a thread may restrict or qualify the attributes applicable to the overall process. The thread has a context attribute which allows the operating system to correctly perform context switching as required.
The Windows NT Posix subsystem does not support multi-threading, though the OS/2 and Win 32 subsystems do. All threads are subject to manipulation by the kernel, which will schedule their priority for access to the CPU. The kernel is concerned with its own view of a thread called a kernel thread object. The kernel does not use thread handles but instead accesses threads directly from it's kernel process object. Windows NT threads support SMP, with individual threads (and processes for that matter) having a defined processor affinity which can define on which of a selection of available processors the thread may be run. |
|
Kernel-space threads may be implemented in the kernel by allocation of a thread table to a process. The kernel schedules threads within the time quantum allocated to the process.
This method requires slightly more overhead for context switching but advantages include true pre-emption of tasks, thus overcoming the starvation problem. I/O blocking is also no longer a problem. Threads can automatically take advantage of SMPs with run time efficiency improving linearly as CPUs are added. |
|
|
Linux
|
|
Windows NT
|
|
The kernel records a process's creation time and the CPU time it has consumed including the time spent in user mode and time spent in system mode.
Processes may also have their own interval timers, which may be single shot or periodic. These can use signals to notify the process when timers expire. |
|
Timer objects exist as an Executive support service which will record the passage of time. After a set time or on expiry of a time interval the object becomes 'signalled' which will release all waiting threads.
|
Virtual memory provides a way of running more processes than can physically fit within a computer's physical address space.
Each process that is a candidate for running on a processor is allocated it's own virtual memory area which defines the logical set of addresses that a process can access to carry out it's required task. As this total virtual memory area is very large (typically constrained by the number of address bits the processor has and the maximum number of processes it supports), each process can be allocated a large logical address space (typically 3Gb) in which to operate.
It is the job of a virtual memory manager to ensure that active processes and the areas they wish to access are remapped to physical memory as required. This is achieved by a method of swapping or paging the required sections (pages) into and out of physical memory as required. Swapping involves replacing a complete process with another in memory whereas paging involves removal of a 'page' (typically 2-4kbytes) of the process's mapped memory and replacing it with a page from another process. As this may be a computer intensive and time consuming task, care is taken to minimise the overhead that it has. This is done by usage of a number of algorithms designed to take advantage of the common locality of related sections of code and also only carrying out some operations such as memory duplication or reading when absolutely required ( techniques known as copy on write, lazy paging and demand paging).
The virtual memory owned by a process may contain code and data from many sources. Executable code may be shared between processes in the form of shared libraries, as these areas are read-only there is little chance of them becoming corrupted. Processes can allocate and link virtual memory to use during their processing,
Some of the memory management techniques used by many operating systems, including Linux and Windows NT include :
| Page based protection mechanism | Each virtual page has a set of flags which determine the types of access allowed in user mode or kernel mode. |
| Demand paging / lazy reading | the virtual memory of a process is brought into physical memory only when a process attempts to use it. |
| Kernel and User modes of operation | Unrestricted access to process's memory in kernel mode but access only to it's own memory for a process in user mode. |
| Mapped files | Memory is extended by allowing disk files to be used as a staging area for pages swapped out of physical memory. |
| Copy on write memory | When two processes require access to a common area of code the virtual memory manager does not copy the section immediately as if only read access is required the section may be used safely by both processes. Only when a write is requested does the copy take place. |
| Shared memory | An area of memory may be mapped into the address space of more than one process by the calling of privileged operations. |
| Memory Locking | To ensure a critical page can never be swapped out of memory it may be locked in, the vritual memory manager will not then remove it. |
| For Windows NT : Object based Memory Protection | The NT security reference checks access permissions for any process attempting to open a handle to that memory section or map a view of it. |
![]()
![]()
![]()
Next: Introduction
Roll your own DBMS?!?
Author: Idan Shoham
Document release date: May 28, 1997
![]()
![]()
![]()
Next: A little history Up: Build your own DBMS!! Previous: Build your own DBMS!!
This article describes a project, recently completed at M-Tech, for which we constructed a client/server database management system (DBMS), from the ground up. This DBMS was built using off-the-shelf components, some tools recycled from previous projects and a modest amount of new code.
You might ask why we developed a new DBMS, considering the diversity and quality of commercial DBMS-s already on the market. The answer lies in the stringent demands of a project we had contracted for. This project required an inexpensive, fast, reliable DBMS that could support highly secure transactions over a slow public network. There are commercial DBMS products that are inexpensive, fast, or secure, but we are not aware of any that combine all of these merits, as well as responsive performance over something as slow as a modem.
This article is of particular interest because the technology we developed for this project can be utilized to construct systems that carry any of the stringent demands of our original project, such as:
Over the course of about six months, we implemented the entire client/server architecture. With all the building blocks in place, we could implement some extra features with relative ease:
We already had a system (from a previous project) that could convert a high-level description of a report into C source code, to be linked against CodeBase. We integrated stand-alone executable reports written using this tool into the server, so that a client could request a report and the server would deliver only the output.
We built the infrastructure and used it to build a mental health clinical information database - which is now used by qualified, authorized clinicians throughout Calgary to share clinical data about patients. The system is ``live,'' the feedback from users has been positive and there are already hundreds of trained, active users.
The MHCID system as currently implemented allows users to enter data about new patients, find clinical records about existing patients, send each other e-mail as well as read and post bulletins. There is a friendly interface by which an authorized user can add and delete users, update lookup tables and change the access control model.
All these tools .. all this infrastructure .. just one application? We are already using the same infrastructure to develop two additional applications - one in a mental health outcomes measurement study, and another for a palliative care system.
There is nothing specific to health applications about the technology, though! Any system that requires one or more of the key features of the technology: fast response over a low-bandwidth, high-latency network; strong security; low licensing cost; low administration / support costs can benefit from this architecture.
(c) 1996,7 M-Tech Mercury Information Technology, Inc.
As mentioned earlier, the DBMS architecture described in this article grew out of the demanding requirements for a system we were contracted to develop. That system is now the Mental Health Clinical Integrated Database (MHCID). It allows clinicians in the mental health sector in Calgary to share clinical data about patients throughout all CRHA-sanctioned mental health clinics and hospitals in the city.
The MHCID system presented us with these difficult requirements:
In order to minimize the development and debugging efforts, a project like this would ideally use as much ``off-the-shelf'' technology as possible.
We first considered using a commercial DBMS, due to the many available options: file/server systems such as FoxPro or MS-Access and client/server systems such as Oracle, Sybase or SQL-Server. However, it soon became apparent that a file-server solution would not perform adequately in a modem-based network. Also, of the client/server technologies, only Oracle offered a cryptographically secured solution (Secure Oracle). While this appeared to be a sound technology, the licensing costs alone would have exceeded the total project budget.
Not only was price a significant problem, but we were also unsure of the performance implications of running Oracle's SQL*Net protocol over a 30kbps link. SQL*Net is designed for a LAN environment, where 1Mbps can usually be sustained for the life of a transaction.
There had to be a better way!
To summarize, we had to build a system that met the following requirements. To succeed, every criteria had to be met in full:
The last criterion makes the preceding ones even harder to achieve!
To address the aforementioned requirements, we clearly had to use a client/server database technology. To defend against eavesdropping, we had to encrypt all communications.
At the time, IPsec and virtual private networks were not available. Even today, these are young technologies and VPNs are not yet suitable for implementation on client workstations. The solution had to be encryption in the DBMS protocol. To do this, we could either buy Secure Oracle (which would put the project over budget), or roll our own solution.
We had to write a DBMS engine which would encrypt all communication, be responsive when the bandwidth was low and the latency high, support strong authentication, access controls and auditing features. On the bright side, we really didn't need an SQL engine, or a generalized query engine at all. (More on queries and reports later, though!)
A client/server architecture consists of several parts:
To implement a client/server database, each of the components above must be implemented; either using existing software or by writing new code. We designed a new client/server system primarily in order to implement our own secure protocol. Accordingly, we wrote our own code to handle the database communication protocol. The other components are off-the-shelf, in order to reduce the programming work.
The following are the components used in our system:
| Location | Component | Technology |
| Client | operating system | Win32 |
| network communication package | TCP/IP + SSL | |
| client DBMS communication package | Our own code | |
| graphical user interface | Zinc | |
| Network | protocol | TCP/IP |
| Server | operating system | Linux |
| network communication package | TCP/IP + SSL | |
| database protocol + support code | Our own code | |
| authentication module | Our own code | |
| access control / logging module | Our own code | |
| package for physical DBMS access | CodeBase |
The architecture is illustrated in Figure 1.
We chose Win32 for the client interface because it is common, well-accepted and friendly.
We used the Zinc platform-independent graphical user interface library to develop the user interface of the client software. Zinc allowed us to save time writing Windows screen code and be sure that future versions of the software could easily be ported to other operating systems (e.g., Motif, Curses, NextStep, MacOS, OS/2 PM).
We used TCP/IP as the communication protocol because it is also common, well supported and independent of physical media. Although modems are used in the MHCID system today, we anticipate other media in the future.
In order to secure the database communications, we needed an efficient, robust and proven encryption protocol. Developing encryption algorithms and secure protocols is a complex task, fraught with danger. Rather than invent our own, it was preferable to use something ``tried and true.'' SSL, developed by Netscape, is just such a protocol. It can use public-key cryptography to authenticate the server and to exchange a secret session key in a secure fashion.
Fortunately, an efficient implementation of SSL is available on the Internet, courtesy the hard work of Eric Young and Tim Hudson - SSLeay.
We developed our own DBMS protocol using a simple syntax, on top of SSL sockets. A set of three-letter commands was defined, which supports everything from logging in, to multi-record read and write operations. The client sends commands to the server, and the server replies with any relevant data, plus a status code. The protocol was designed to be terse, simple and to support every operation required by our client software in a single operation.
Some examples of how the protocol speeds up the client/server interaction are:
We chose to implement the server on Linux for a number of reasons:
Once the operating system and database protocol design were fixed, all we needed was a physical database access system. Rather than write our own, we used CodeBase, which allows programs written in C to manipulate xBase-compatible database files. We used CodeBase because we were familiar with it from previous projects and have found it to be fast and reliable.
Two year ago the Internet was exploding in Italy. A lot of newspaper reported wishfull informations about it:
the Net is over 40 million of people looking for your information;
the Net is cheap and fast
the Net is growing so fast that you can't keep up.
Unioncamere is the regional association of Chamber of Commerce of The italian region Emilia-Romagna (Bologna is the capital, but Rimini is the well-world-wide-know city). Chambers of Commerce in Italy are public bodies, and all the firm must be associated to the Chamber of Commerce and have to pay an annual tax.
As you can easily understand firms are not so happy to pay tax, so we are always under a big pressure from them. They want to have a lot of data about economy, markets and financial tools in a fast and viable way and without a lot of cost of maintenance.
Internet was the choiche and Linux was the system of choiche! At the beginning of september 1995 we was starting the project of establishing a server , at the end of october we was on line with the www server.
To give a fast stratup has been very important the contribution of Massimo Poli, and indipendent consultant running a lot of sites and using Linux only; you che reach him at www.sextant.it, the little firm he is managing.
When you pay a consultant using Linux you are sure to pay his work only, and not a bogus "assistance service" or "online help". This is very important in establishing a good and clear contract.
When we started whith the site we was using a coax-ethernet based LAN with 30 users about. The 2 internal servers was (and they are working too) Novell 3.12 based. Novell is IMHO a good NOS for two tasks: printing and sharing disks. Novell tecnology is quite stable: our server BOSS is up and running without shutdown from 6 of january 1997. But we was needing a good e-mail server and a workgroup solution.
We decided to move to Linux for internal E-mail as for Internet E-mail. In this way you have an affordable solution with low costs and no standard problems.
The site is growing fast. Using Apache solution and virtual server capacibility we are hosting two Chamber of Commerce and we are going to host the other 7 in the region in the next future. Mailing lists, restricted users areas, on-line database with www interfaces and other usefull instruments are all in use in our server box. Security was another big problem, but not so big using Linux firewalls. In 1996 we have installed a second server cruncing the Lan in two segments.
Whit Linux we have solved a lot of problem at low cost, but Linux is excellent in networking and network management. Now I'm administrating the full network (SMB servers included) with my Linux box. I'm now mounting volumes from Novell and fron NT 4 workstations, I'm already printing from Novell printer server. Because I'm not a full time administrator (I'm really working here as Chief of the Research and develpment office, and I'm not an hacker, but a Senior Economist) I use Linux for Office work too. Applixware is the solution I prefer, the only 200 $ I've spent for software whith Linux. The solution provided by Applixware is good because I share my work with Microsoft maniac in my office, and I need the filters for Word and Excel that Applixware is providing with version 4.3.
Workgroup solutions are now provided by a linux box with BSCW software, a not well know piece of software in the linux world, but a vary usefull one if you plan to establish an intranet whit workgroup solutions.
For all the 4 linux boxex running in our network we use standard pc's. 2 of the four machines running are old Pentium 90 and 133 Mhz that people with Win95 wants no more, because those are "weak machines".
As you have already understood reading this article, we are not linux-religious or linux-maniac or linux-fanatic. In our offices we run Novell and Os/2 and Win* machines as well. But we use linux because for some tasks is the best solution, only the best solution. Is stable, well supported and documented. If you want to run a new project where the Internet or the Intranet is involved and your boss is not able to understand or you have no more money, go to the room were the old-and-disrupted-pc's are and set-up a linux box.
AKA Monty
Abstract
The Midnight Commander is a directory browsing and file manipulation program that provides a flexible, powerful, and convenient set of file and directory operations. It is capable of running in either a console or an xterm under X11; mouse support is native under X11 and is provided by the gpm mouse server when used in a Linux console. A sophisticated Virtual File System (VFS) supports directory-like browsing and file operations for a variety of common archive formats as well as FTP and network connections. Its basic operation is easily mastered by the novice while providing a rich feature set and extensive customization.
The last couple years has seen the release of a bevy of well designed, X based file managers including FileMan, FileRunner, Linux Explorer, TkDesk, X-Files, and Xplorer to name a few. Some of these are "works in progress" but all show promise and are well worth having a look at.
Despite this, one of my favorites, and now old enough in the "Linux Epoch" to be called venerable, is Miguel de Icaza's Midnight Commander (mc). The README describes mc as:
Its stability, ease of use, flexibility, and rich feature set make it quite a powerful tool. Its simplicity makes it easy for novices to quickly master the basics. Among the capacities it boasts are:a free Norton Commander Clone with many useful features... The Midnight Commander is a directory browsing tool which bears a certain remote resemblance to John Socha's Norton Commander for DOS.
The manual page for mc is well over 50 pages in length, giving some indication of its complexity. In this short article I won't be able to cover mc in this depth, but will try to touch on the basics: getting the sources, compiling and installation, and basic use and features. This is probably best read while sitting at your computer and experimenting with the various features as you go. Let's start by compiling and installing mc.
Sources and precompiled binaries are available at a number of locations including the canonical GNU FTP archive prep.ai.mit.edu/pub/gnu/ and the sunsite FTP archive at sunsite.unc.edu/pub/Linux/utils/file/managers/mc/. The official web page is http://mc.blackdown.org/mc/ where the most recent public and development releases may also be found. There are, additionally, mailing lists for both users and developers to which you can subscribe from this site.
In addition, most Linux distributions including Debian, RedHat, Slackware, and their derivatives provide precompiled packages in *.deb, *.rpm, or *.tgz formats. If you feel a bit shaky at the prospect of compiling your own programs, or are in a hurry to get going, then these provide an easy means of obtaining and installing mc. Check the documentation that came with your distribution as to the specifics of using the package management system they provide. At a minimum you could try:
$ installpkg mc-xxx.tgz
-OR-
$ rpm -i mc-xxx.rpm
for Slackware or RedHat based systems in which "mc-xxx.{tgz,rpm}" is the name of the package.
In the pioneering spirit of Linux's "Do It Yourself And Learn", I'd like to suggest that you compile and install mc from its sources. It's not that difficult and if you've not done much of this then mc is an ideal program on which to start since it is quite well behaved.
For the purposes of this article I'll be using mc version 4.1.5 which is the most current at the time of this writing. If you ftp the sources from sunsite or one of its mirrors then you might also want to retrieve a couple other useful packages that support mc: the rxvt X window terminal, Allesandro Rubini's gpm mouse server, and Theodore T'so and Remy Card's e2fsprogs package which allows file undelete capacity to be compiled into mc. All of these are available at sunsite or its mirrors in the /pub/Linux/utils/file/managers/mc/ directory.
In this section, I'll assume that you've gotten the *.tar.gz source file, that you'll unarchive the sources into /usr/src, and that you'll install mc and its support files under /usr/local. You can obvious compile and install mc in any directory you wish: just change the pathnames to suit your preferences. To unarchive the sources do:
$ cd /usr/src
$ tar -xvzf /path/to/mc-4.1.5.tar.gz
in which "/path/to/mc-4.1.5.tar.g" is the path to the source file -- i.e., if you downloaded the file to your home directory you'd use:
$ tar -xvzf ~/mc-4.1.5.tar.gz
This assumes that you're using the GNU version of tar which handles gzipped files using the "-z" option. If you are using a different version of tar you can also do:
$ gzip -dc /path/to/mc-4.1.5.tar.gz | tar -xvf -
After unarchiving the file change to the mc-4.1.5 directory where you'll find both the sources and program documentation. The mc distribution comes with two files outlining the installation process: INSTALL and INSTALL.FAST. If you're not used to compiling programs from source then read INSTALL.FAST which gives a concise explanation of the process as well as options that you can use to customize where mc gets installed and what features it includes. If you're a bit more adventurous, then have a look at the INSTALL document which goes into a good deal more detail. For our purposes, I'll go through the process of compiling mc with Virtual File System, SLang, and gpm mouse support (which is very little work since these are the defaults). We'll install the mc executable under /usr/local/bin and its support files under /usr/local/lib/mc. You should log in as root in order to compile and install mc.
As with many other GNU programs, mc uses an autoconf script to detect the various features of your system and then create the needed makefiles. This greatly simplifies the build process. An additional feature that this supports is the ability to declare compilation options such as what features to include and where the program will be installed. Both INSTALL and INSTALL.FAST give a listing of these features. We'll use:
$ ./configure --prefix=/usr/local --with-slang > configure.log 2>&1 &
$ tail -f configure.log
The mc configure script defaults to compiling in SLang, mouse, and X Window support (so the --with-slang option wasn't really necessary). So as to have a record of what happened use > configure.log 2>&1 which saves all the output to configure.log. Use tail -f configure.log to view the log file as the configure script progresses. When configure is finished it prints a summary of the features and compile options that will be used. Use Control-C to exit out of tail.
If there were no error messages (and there should be none) then compiling and installing is as simple as:
$ make
$ make install
If you want to create a log file of the build and installation process you can use:
$ make > make.log 2>&1 &
$ tail -f make.log
$ make install > install.log 2>&1 &
$ tail -f install.log
And that should do it! To ensure that mc was installed properly type:
$ mc -V
Midnight Commander 4.1.5
with mouse support on xterm and the Linux console.
Edition: text mode
Virtual File System: tarfs, extfs, ftpfs, mcfs, undelfs.
With built in Editor
Using system-installed S-lang library with an unknown terminal database
With subshell support: as default
With DUSUM command
With support for background operations
This returns version and compilation information. If you've compiled and installed the 4.1.5 version but mc -V returns a previous version then you'll need to find and uninstall or rename the previous version. If you use the bash shell, type:
$ type -a mc
This should return the paths to all mc executables. At this point, you can either use your distribution's package manager to uninstall the previous version or temporarily rename it to something like mc.old. You should now be ready to start exploring mc!
Without trying to be exhaustive I'd like to touch on the following topics:
$ echo $TERM
linux
(if this returns "linux" as above, then do the following:)
$ export TERM=xterm
$ echo $TERM
xterm
$ mc
At this point, you should see something like:
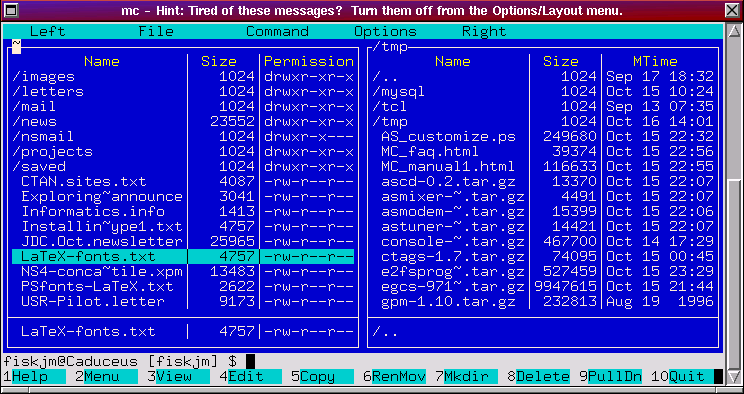
This main screen is similar to what you'd see at the console (the window has been sized to 80x24). It's main components are:
If you move the mouse around you should also see a pointer on the screen. If you don't see a cursor when using mc at the console then make sure that the gpm mouse server is running:
$ ps -ax | grep gpm
73 S0 S 0:00 /usr/bin/gpm -t ms
104 ? SW 0:00 (gpm-root)
5465 ? D 0:00 grep gpm
If it isn't then (assuming you're using a Microsoft-compatible serial mouse) start it using gpm -t ms. The "-t" option specifies the type of mouse; if you're using a different kind of mouse then consult the gpm manual page for the command line option to use.
To activate one of the menus you can either click on it with the mouse or hit the F9 key and use the arrow keys to move the desired menu item. This brings up one of the important features of mc: almost all operations can be performed using either the mouse or via keystrokes. Which method you use is a matter of personal style and preference although, as we'll see in a bit, using keystrokes can be a considerable time saver especially if you are a touch typist.
The directory panels are where most of the action takes place. mc is normally run in this two-panel mode although single panel mode is also supported. The panels provide a view of two directories at once with one of them being the "current directory." Most all file operations are performed on files in this current directory (although copy, rename, and move operations default to using the non-current directory as the "target" directory). To select one directory panel simply click the mouse anywhere in the panel. You can also use the TAB key to switch the current directory from one panel to the other.
The command line at the bottom functions just as you'd expect: simply type the command to execute and mc runs it just as if you'd entered it at the shell prompt. Just above the command line is the hint line (at the console; in an xterm it uses the title bar) which displays a series of hints and suggestions.
Finally, the bottom line of the window display the function key mappings. Pressing F1 brings up the Help menu, F2 brings up the User Menu, F3 let's you view a file, and so forth. Note that clicking on any of these with the mouse results in the same action.
In addition to this main window there are a number of popup dialog boxes which are used for specific operations. I'll cover several of these shortly. For now, let's turn to issues of navigation.
One other navigation aid to keep in mind is that movement within the directory panels can be accomplished using a variety of keystrokes, many of which are modeled after the emacs text editor. These include:
Once you know how to move from one directory to another the next thing to do is learn how to perform basic file operations. But before doing that we'll need to take a quick detour.
First, we need to make a distinction between the currently selected file or directory and marked or tagged files. The currently selected file is simply the one that is highlighted in the current directory panel. If you want to delete foo.txt simply move the highlight bar to that file and hit F8 to delete it. However, if you want to delete a group of files then you'll need to tag them.
Tagging can be done in a couple ways. The simplest is to either click on the file or directory using the right mouse button or move the highlight bar to the file and hit Ctrl-t (that is, hold down the control key and hit t). In this way you can tag any number of files for copy, deletion, moving, and so forth.
If the files you want can be specified by a shell pattern (such as *.tar.gz for all the gzipped tar files or foo_??.txt for foo_01.txt, foo_02.txt, foo_03.txt, etc., then you can use the following shortcuts:
Using pathname expansion (also known as filename globbing) is a fast and powerful way to select a group of similar files. Having now selected your files, let's see what you can do with them.
Below is a short summary of the file operations. In the next section we'll look specifically at file viewing and editing. Keep in mind that while the summary below indicates the keystrokes for the various operations, all of these can be accessed using the "File" menu.
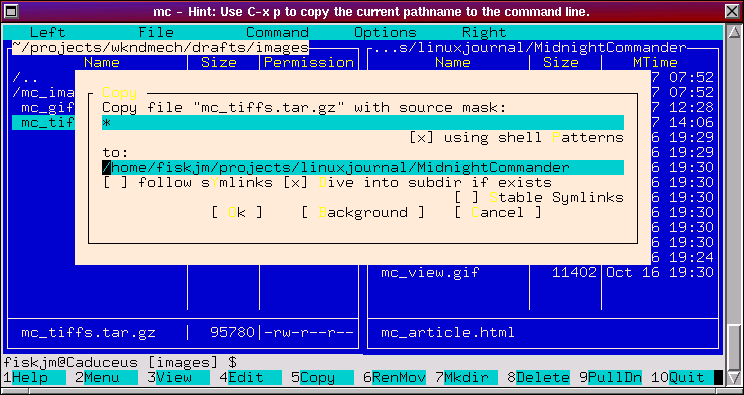
If you want to use a different directory than the one in the other panel or if you want to change the file name then you can use the to: entry box to do so.
Also, when you perform a copy (and move or delete) operation mc displays a dialog box with a progress meter indicating the progress on the current file as well as the overall progress if a set of files has been selected.
Note that at any time you can cancel an operation by hitting the Escape key twice.
Note that an "Advanced Chown" facility is available under the "File" menu. Until you're rather sure of what you're doing, this is probably best left alone.
With these basic facilities you'll be able to do a good deal of day to day file system maintenance. To round things out, though, we'll need to add a couple other features.
For example, to view a manual page (even a gzipped page!) simply select the file and hit F3. If you have the mc source distribution handy, change to the doc directory and select the mc.1 file. Hit F3 to see:
You can do similar things with HTML or mail files. In the case of HTML files it is worth noting that "viewing" the file is probably not what you expect as mc will strip out the hypertext tags leaving just the text. If you want to view an HTML file it is best to select the file and hit the RETURN key. Doing so "opens" the file and automatically executes (by default) lynx if you are at a console or netscape if you are running under X.
The internal file view allows you to view files in one of two modes: ASCII or hex. When using the file viewer you'll notice that the function keys at the bottom change to a new set which are specific to the viewer. These include:
In addition Ctrl-s and Ctrl-r can be used for normal or reverse searches. Once you've started a search, hit the letter n to find the next match. Ctrl-l will repaint the screen; Alt-r will toggle the display of a ruler.
In terms of moving around the viewer, mc has a rather egalitarian attitude and will accommodate almost any set of movement keystrokes that you've gotten used including those for emacs, less, and even some vi. Some of these are:
One very handy feature is that, if you are in View mode and hit Ctrl-f then the viewer will move to the next file in the directory and display it. In this way you can easily move through a set of files, viewing one right after the other.
The internal file editor provides a full set of editing features and can be used to edit both text and binary files up to a size of 16 megabytes. As with the Viewer, function keys have been remapped to provide common file editing functions. In addition, a popup menubar provides extensive editing operations including file insertion, save, copy, and load; block operations (copy, move, etc); search/replace functions; command macro recording and execution; and the capacity to pipe selected text through various shell commands such as indent or fmt. When not active, the menubar is hidden and file information is displayed in the topmost line. Here's a screen dump of the editor in action:
Both the internal Viewer and Editor are designed to be fast and easy to use. You may, however, wish to use an external viewer (such as more, less, or most) or editor. To do so, you'll need to set your PAGER and EDITOR environment variables to the appropriate program and then use the Options->Configuration menu to unselect "use internal edit" or "use internal view". If you were using the bash shell and wanted to set the pager to "less" and the editor to "emacs", then use something like:
$ export PAGER=less
$ export EDITOR=emacs
To make this change permanent you'd probably want to add these lines to your ~/.bashrc or ~/.bash_profile file. Having looked at the basic file operations let's return to mc itself and take a look at some of its other features.
As previously noted, you can quickly switch from one panel to the other using the TAB key (or Ctrl-i). You can also swap panels using Ctrl-u; note that the currently active directory panel does not change. Use Ctrl-r to refresh the directory display.
To change the sort order of the files being displayed, use the (Left|Right)->Sort Order... menu item. This allows you to sort files by name, size, various time stamps, inode number, and so forth. You can also specify whether sorting should be case (in)sensitive or reversed. Sorting by size is very useful when trying to cull out files to recover disk space; sorting by date is useful when you are searching for a recently installed, created, or modified file in a directory with many files or are looking for ancient files that can safely be warehoused.
As with sorting, use the (Left|Right)->Filter... menu item to filter the directory listing using shell patterns. For instance, suppose that you wanted a listing containing only files with a .c extension. In the Filter dialog simply enter "*.c" and all other files are removed from the listing. This is very useful when you wish to work with only a subset of files in a directory in an uncluttered setting.
You can also cycle from two-panel to single-panel modes using Alt-t. This is particularly useful when you need to see the full directory information for a particular file. Note that you can also use the (Left|Right)->Listing Mode... menu item to customize what file information the panel lists. In addition, resize the panels using the Options->Layout... menu item. This allows you to split the panels either vertically or horizontally as well as set the number of columns for each panel using the ">" and "<" keys.
One final shortcut to be aware of is Alt-o which makes use of both panels: by selecting a directory in the active panel and hitting Alt-o, its directory listing is displayed in the other panel. Hitting Alt-o repeatedly lets you quickly preview through a series of directories.
Another powerful feature of mc is its ability to handle a multitude of archive types: this feature alone makes it a "must have" utility!
VFS refers to the "Virtual File System" which mc implements. It is a powerful abstraction that allows you to view archives as though they were a directory: all the basic file manipulation operations can then be applied. The VFS file system handles an extraordinary number of archive types including tar, gzipped or compressed tar, RedHat's rpm package archives, Debian's deb package archives, gzip, zip, zoo, cpio, rar, and lha.
To use it either select the file and hit RETURN or double click on the file. It's contents are then displayed as a directory listing. Navigation through the archive is the same as you'd use for a directory. This is a very useful feature when you need a single file or set of files from an archive. Note that if the archive is a compressed single file -- i.e., a gzip, zip, zoo, or lha compressed file -- then it is uncompressed and displayed.
The VFS also supports its own FTP capacity which allows you to transparently manipulate files via FTP as though they were local to your machine. To log into an FTP server use the (Left|Right)->FTP Link... menu item and enter the URL or simply enter cd ftp://"URL" at the command line. For example, to ftp to the Linux Incoming directory at sunsite you would enter:
$ cd ftp://sunsite.unc.edu/pub/Linux/Incoming/
The hintbar at the console or the title bar under X will display progress information (e.g., logging in, retrieving directory listings, and so forth). You can now view and copy files just as you would using ftp. On file transfer (use F5 to "Copy" the file to your local machine) a progress meter displays percent transfer completed, ETA (estimated time of arrival), transfer rate, and the now commonplace "stalled" flag. Use the Options->Virtual FS... menu item to customize the VFS features such as anonymous login name and so forth.
Note that mc also provides FTP service via a proxy server as well as network VFS. Having no experience with either of these I'll defer comment and simply refer you to mc's manual page if you are interested.
In this last section let's look at a few more shortcuts and suggestions for using mc effectively.
A number of popups are built into mc that considerably speed up various operations. These include:
If you use mc as an ftp client then you can use the directory hotlist to keep the URL's for your frequented sites! To edit (add, modify, or delete entries) the list type in Ctrl-\ and then use "New Entry" to create a new entry: enter the URL for the site, including the path to the directory that you're interested in and then fill in the alias. Now, anytime that you need to ftp just popup the hotlist and select the site!
Alternatively, if you were looking for all files with "announce" in the filename simply enter "*announce*" in Filename: (and leave the Content: entry box empty).
Another very handy feature which mc provides is subshell support. The way this works is by hitting Ctrl-o which creates a non-login interactive shell. This works for bash, tcsh, and zsh shells. Use this shell just as you would any ordinary shell. To immediately switch back to mc hit Ctrl-o once again, which allows you to toggle back and forth easily.
If you are using the bash shell, keep in mind that non-login interactive shells only source your ~/.bashrc file (and not the ~/.bash_profile file) which means that if you have aliases or other customizations that you want to use then you should put these in ~/.bashrc. For example, if you use color-ls and find that file listings are not colorized, then you'll need to add alias ls='ls --color=tty' to your ~/.bashrc.
One way to quickly create the "all-in-one-command-center" is execute mc and then start a subshell. From here, you can execute your favorite editor (emacs, xemacs, vim, etc.) and hit Ctrl-z to stop its execution and put it in the background. This returns you to the shell. Now, if you need to run mc then hit Ctrl-o; if you need to use your editor, type in fg which will resume the stopped program; and if you need to run any other program then use the shell as normal. This is a powerful means of keeping productivity tools readily available.
One last feature I'd like to mention is mc's ability to help you sync the contents of two directories. This is particularly useful if you are keeping a backup set of files on another partition, a floppy, zip drive, etc. To use this list the "source" directory in one panel and the "target" directory in the other then hit Ctrl-x d. This will pop up a dialog box that allows you to select the type of directory comparison: Size simply compares files by size; Quick compares files by size and date; and Thorough does an exhaustive byte-by-byte comparison. After the comparison operation is complete (and after ensuring that the source directory is in the active directory panel) hit F5 (Copy) to copy files from your source directory to the target (backup) directory.
While I've attempted to cover most of the important features which mc offers there are many more that I've not had time to cover that I'll leave for you to discover! One suggestion would be to print out a copy of the mc manual page:
man mc | col -b | lpr -
-OR-
man mc | col -b > mc.txt
will print a copy of the manual page or save it to a text file which can be further processed. Since the manual is quite long you might want to use a program such as a2ps which converts ASCII files into Postscript. As with most UNIX-type programs, a2ps has a slew of command line options including the -f option which lets you specify the font size: select something in the range of 7.0 to 9.0 to get a small font which cuts down on the number of pages and leaves large margins in the sides for you to scrawl notes in.
Also, while you are exploring, look through the Options menu for various items which will let you customize mc. Menus are a great place to poke around and see what facilities mc offers: most of the shortcut keystrokes I've mentioned are menu items (so you don't have to memorize the entire list of keystrokes!). For the adventurous:
Finally, enjoy mc! As with many powerful programs, you'll most likely learn it incrementally, often just through the process of exploration and "playing with it." I've found mc to be indispensable and, with a bit of experience, I suspect that you will as well. Have fun!
Date Last Modified: $Date: 1997/10/19 01:33:27 $


Hello y'all! Thanks for dropping in. I'm afraid that this month's weekend mechanic is going to be a bit sparser that usual. This semester has been a good deal more challenging than previous. I've been taking Compiler Design, Database Design, Computer Graphics (X Window based course), and Differential Equations and I'm really starting to "suck wind" about now (and I see lots of knowing smiles and folks waving white hankies out in the audience :-). To all of you in school, my sincerest best wishes!
And once again, my 'ol Linux box has pulled though in the clutch. I've been leaning on it pretty heavily this semester and it's shown what a fantastic work horse it really is.
In the compiler class we're building a "baby Pascal-like" compiler using C++ and while others sit for endless hours in the computer lab hacking away on the HP system at school, I've been sitting for endless hours hacking comfortably at home on my Linux box! It doesn't make the hours fewer, but it sure makes them more enjoyable! I've also been playing around with PostgreSQL 6.2 and MySQL RDBMS's and they have been a HUGE amount of fun and a great means of learning SQL and database design. When things here settle down a bit I'll be writing a bit about these.
For my DiffEq class I finally broke down and purchased the venerable Mathematica 3.0 for Linux from the good folks at Wolfram Research. This has been a godsend and a wonderful toy to tinker with! I'll refrain from getting on the soap box about this one, but will say that it is a fantastic program and would HIGHLY encourage anyone in a mathematics-oriented discipline to invest in it. For the curious, here's a "hot off the press" screen-shot of what I've been up to this weekend: plowing through a DE take-home exam (and don't worry, our instructor, who's a delightful and brilliant guy, gave us the OK to use "whatever technology you have at your disposal..." :-)
Here's the obligatory thumbnail: click on it to get the full (~88K) 1024x768 effect - kinda like being there...!
For the curious, this was the question about a damped oscillator whose angle of deflection was given by the equation:
Ø'' + 0.25 Ø' + sinØ = 0
In which Ø is meant to be theta, the angle of deflection. The graph is the time series plot of the corresponding system of non-linear differential equations with starting values at (0,2), (0,3), and (0,4). Mathematica has been fantastic and, more to the point, they provide a Linux Student Version. If you're serious about wanting to see high quality software for Linux, then "speak with your feet" (or rather, your wallet :-). If I were doing the Tucows thing, these guys would get the whole herd!
And finally, I've been doing a slew of X window based programming using Xlib and now Motif for my Computer Graphics course. Once again, Linux has meant being home at night rather than 40 miles away sitting in the student lab hacking on the X system at school. I've mentioned it before but it's worth repeating good praise: I bought RedHat Motif 2.0 a couple years ago at the Linux Expo and haven't had a single problem with it despite a good deal of use. If you're shopping for Motif then I'd definitely have a look at this product. On the other hand, I've heard reports that the "Hungry Programmers" have been making serious strides in bringing the LessTif product to maturity. Here's a quote from a recent 0.81 distribution:
LessTif 0.81 has just been released. LessTif is a freely available Motif clone. It is going to be source level compatible with Motif 1.2. It is distributed under the terms of the GNU Library General Public License (LGPL). LessTif is available from the following URL's http://www.hungry.com/products/lesstif/ ftp://ftp.hungry.com/pub/hungry/lesstif/ or http://www.lesstif.org/products/lesstif/ ftp://ftp.lesstif.org/pub/hungry/lesstif/I haven't had a chance yet to compile and install it but a number of programs, such as the latest DDD debugger, claim to be compilable using Lesstif.
As I mentioned above, time has been a bit short here recently although over a short Fall Break a couple weeks ago I did manage to write up a short article for the Linux Journal on the Midnight Commander file manager. They have very graciously allowed me to include the full text of this here. This is the unedited, first-draft copy that was sent to them, so all the typos and other egregiosities are solely mine. I have long wanted to write about this fantastic file manager which, in my book, is a definite "must have" app on every Linux system. This is geared towards an introduction/overview, and while admittedly not encyclopedic, it does cover most of the highlights (I think... :-) Here it is:
Again, I apologize for such a short column after so long a hiatus. As all of the graduating seniors will attest, the final semester usually packs quite a wallop and mine has been no different. Good news is, by the time you read this I'll be nearly done: GRE Comp Sci Subjects are on December 13th at 2:00 PM.
And then... sleep :-)
I'll be working with the good folks in Biomedical Informatics at the Vanderbilt University Medical Center here in Nashville for the following six months or so and then, hopefully, I'll be starting a Medical Informatics fellowship or MS program in Comp Sci somewhere. In the interim, I have a large and growing list of backlogged projects and things I'd like to read up on, tinker with, and learn about. By January, I'm hoping to have the Weekend Mechanic column back up to speed.
My deepest and sincerest thanks to Marjorie Richardson and the rest of the crew at Specialize Systems Consulting who have worked extraordinarily hard at providing the Linux Gazette. Special thanks are also deserving to Mr. Richardson, who has shouldered the burden of "Linux Gazette Editor" this month!
Finally, from our home to yours, we want to wish y'all a very wonderful and joyous Christmas Season.
John & Faith Fisk
Nashville, TN

Got any comments, suggestions, criticisms or ideas?
Feel free to drop me a note at:
Document Information:
$Id: wkndmech_dec97.html,v 1.3 1997/11/24 00:18:51 fiskjm Exp fiskjm $
Everyday I have to logon to The MVS (Multiple Virtual Storage) Operating System and edit COBOL (Common Business Oriented Language) program source code. When I first started being a COBOL programmer in 1985, we all used dumb terminals such as the IBM 3278. As time passed, people starting getting IBM PC compatibles and such things as IRMA cards were used to connect the IBM PC to the Mainframe and make it look like a dumb terminal.
After receiving an IBM PC compatible myself, I added an extra SCSI harddisk and installed Linux. Using Linux's TCP/IP capability, and the driver for the 3COM ethernet card in the computer, I was able to connect Linux to the network.
I began to try to logon to the IBM Mainframe. I found that there were several differences between the standard Telnet VT100 terminal model and the IBM 3270 terminals. I needed a new tool so that I could use the features of the IBM 3270 such as function keys.
Fortunately, there are two tools to emulate the IBM 3270 type terminal. One is known as tn3270, and the other is x3270.
X3270 is a program that is available with man Linux distributions and is available on ftp.x.org and other mirror sites.
As a mainframe programmer, I have noticed the following advantages over a dumb terminal:
X3270 comes with various resources that can be configured by the user. Here is contents of my .Xdefaults file apropos x3270:
! Set the font used in the x3270 screen: x3270.emulatorFont: 3270-12 ! Set the model of 3270 family terminal x3270.model: 3 ! Set the default print command: x3270.printTextCommand: lpr -Psmb ! Set the keymap translation to use. I found hp-pc to be the most ! compatible: x3270.keymap: hp-pc ! The below is a user keymap which allows me to override the ! default keymapping. This way I can set the previous (page up) ! key to PF7 which is set to PREV on most ISPF edit panels, ! and page down to PF8 which is DOWN on edit ! EraseEOF is a function to erase a field to end of field ! here I map both ctrl delete and alt delete to this function. x3270.keymap.hp-pc.user: \ <Key>Prior: PF(7)\n\ <Key>Next: PF(8)\n\ Ctrl<Key>Delete: EraseEOF()\n\ Meta<Key>Delete: EraseEOF()\n
X3270 has several other features. One nice feature is the file /usr/lib/X11/x3270/ibm_hosts which contains a list of IBM hosts to appear on a logon menu.
I would say that this is a great program and makes logining on to an IBM Mainframe a breeze.
X3270 comes with manual pages and some documentation. Here are the copyrights from the x3270 manual page:
COPYRIGHTS
Modifications Copyright 1993, 1994, 1995, 1996, 1997 by Paul Mattes. Original X11 Port Copyright 1990 by Jeff Sparkes. Permission to use, copy, modify and distribute this software and its documentation for any purpose and without fee is hereby granted, provided that the above copyright notice appear in all copies and that both that copyright notice and this permission notice appear in supporting documentation.
Copyright 1989 by Georgia Tech Research Corporation, Atlanta, GA 30332. All rights Reserved. GTRC hereby grants public use of this software. Derivative works based on this software must incorporate this copyright notice.

 Wayde AllenLarry AyersAndré D. BalsaChris BaronJim DennisCarlie FairchildJohn M. FiskMichael J. HammelMike ListGiampaolo MontalettiJesper Pedersen
Wayde AllenLarry AyersAndré D. BalsaChris BaronJim DennisCarlie FairchildJohn M. FiskMichael J. HammelMike ListGiampaolo MontalettiJesper PedersenThanks to all our authors, not just the ones above, but also those who wrote giving us their tips and tricks and making suggestions. Thanks also to our new mirror sites.
 While I'm passing out thanks I must include Amy Kukuk and Margie Richardson, who have done much of the work to get this issue out. Margie has been working hard to get me up to speed on this task, but I've still a ways to go. My professional background has been in the oil business as a geophysicist, where I usually worked on dumb terminals connected to IBM mainframes or Digital minicomputers. At home I've been a Macintosh man for many years, so learning Linux/Unix, vi and HTML all at once has been, shall we say, exciting.
While I'm passing out thanks I must include Amy Kukuk and Margie Richardson, who have done much of the work to get this issue out. Margie has been working hard to get me up to speed on this task, but I've still a ways to go. My professional background has been in the oil business as a geophysicist, where I usually worked on dumb terminals connected to IBM mainframes or Digital minicomputers. At home I've been a Macintosh man for many years, so learning Linux/Unix, vi and HTML all at once has been, shall we say, exciting.
As Margie has indicated in the past, we share a passion for the outdoors which we satisfy via camping and motorcycling. With winter close upon us now my adult son, Keith, and I will likely turn to cross country skiing in favor of motorcycling. Although I've not done so lately, I also fly as a private pilot and am rated for both single engine land and sea planes.
 This last week of the month of November Margie and I indulged in that most American of pastimes--eating too much at the Thanksgiving table. We split cooking duties with my sister, Roxanne, who also hosted. The afternoon was grand, the food great, and we even came home with enough leftover turkey meat for several days worth of sandwiches.
This last week of the month of November Margie and I indulged in that most American of pastimes--eating too much at the Thanksgiving table. We split cooking duties with my sister, Roxanne, who also hosted. The afternoon was grand, the food great, and we even came home with enough leftover turkey meat for several days worth of sandwiches.
As a final note, Margie and I will be out of town for the Christmas holidays, so expect the next issue of Linux Gazette to be a little late coming out.
Have fun!
Riley P. Richardson
Editor, Linux Gazette
Linux Gazette Issue 23, December 1997, http://www.linuxgazette.com/
This page written and maintained by the Editor of Linux Gazette,



 The Mailbag!
The Mailbag!
