
To advertise the efforts of http://www.dict.org and to provide the means by which any Linux user regardless of experience, can install a functional dictionary system either for local or network use.
I have been using Linux exclusively as my operating system for over three years now. One of the very few things I miss about "that other operating system" is the easy availability of cheap or even free versions of commercial encyclopedias and dictionaries.
So when I installed a recent version of S.u.S.E. linux I was both surprised and happy to find a package called Kdict had been installed on my machine. Reading the documentation that came with the package revealed that the program was only a front end to another program, and that though it is possible to install a dictionary server locally, if I wanted to do so I would have to get everything else I need from the Internet.
Note:- This section paraphrases the contents of ANNOUNCE in the dict distribution.
The DICT Development Group (www.dict.org) have both developed a Dictionary Server Protocol (as described in RFC 2229), client/server software in C as well as clients in other languages such as Java and Perl, and converted various freely available dictionaries for use with their software.
The Dictionary Server Protocol (DICT) is a TCP transaction based query/response protocol that allows a client to access dictionary definitions from a set of natural language dictionary databases.
dict(1) is a client which can access DICT servers from the command line.
dictd(8) is a server which supports the DICT protocol.
dictzip(1) is a compression program which creates compressed files in the gzip format (see RFC 1952). However, unlike gzip(1), dictzip(1) compresses the file in pieces and stores an index to the pieces in the gzip header. This allows random access to the file at the granularity of the compressed pieces (currently about 64kB) while maintaining good compression ratios (within 5% of the expected ratio for dictionary data). dictd(8) uses files stored in this format.
Available in separate .tar.gz files are the data, conversion programs, and formatted output for several freely-distributable dictionaries. For any single dictionary, the terms for commercial distribution may be different from the terms for non-commercial distribution -- be sure to read the copyright and licensing information at the top of each database file. Below are approximate sizes for the databases, showing the number of headwords in each, and the space required to store the database:
|
Database |
Headwords |
Index |
Data |
Uncompressed |
|
web1913 |
185399 |
3438 kB |
11 MB |
30 MB |
|
wn |
121967 |
2427 kB |
7142 kB |
21 MB |
|
gazetteer |
52994 |
1087 kB |
1754 kB |
8351 kB |
|
jargon |
2135 |
38 kB |
536 kB |
1248 kB |
|
foldoc |
11508 |
220 kB |
1759 kB |
4275 kB |
|
elements |
131 |
2 kB |
12 kB |
38 kB |
|
easton |
3968 |
64 kB |
1077 kB |
2648 kB |
|
hitchcock |
2619 |
34 kB |
33 kB |
85 kB |
|
www |
587 |
8 kB |
58 kB |
135 kB |
All of these compressed databases and indices can be stored in approximately 32MB of disk space.
Additionally there are a number of bi-lingual dictionaries to help with translation. Though I have not looked at these judging from their different sizes some will be more useful than others (i.e. English to Welsh is unfortunately not very good, whereas English to German is probably quite useful).
All the dictionaries seem to be under constant development so interested people should keep up with latest developments.
The Oxford English Dictionary this is not! It is however a very pleasant dictionary. It seems to be an American version of one of those Dictionary/Encyclopedias, so common at the time of its writing. Quite often in a definition you will find a poetic quote and it really is very informative and pleasant to use.
This dictionary seems to be under constant development. The aim seems to be to provide definitions of all the words people want to have definitions for! In practice it seems to miss some obvious words such as "with" and "without". I guess the idea is to simply provide necessary update to the definitions found in Webster's. Unfortunately this dictionary is neither as informative or as pleasant as Webster's. If you need a more up to date dictionary it is necessary.
FOLDOC is a searchable dictionary of acronyms, jargon, programming languages, tools, architecture, operating systems, networking, theory, conventions, standards, mathematics, telecoms, electronics, institutions, companies, projects, products, history, in fact anything to do with computing. The dictionary is Copyright Denis Howe 1993, 1997.
This is probably only of interest to people wanting information about America. The original U.S. Gazetteer Place and Zipcode Files are provided by the U.S. Census Bureau and are in the Public Domain.
These Dictionary topics are from M.G. Easton M.A., D.D., Illustrated Bible Dictionary, Third Edition, published by Thomas Nelson, 1897. Due to the nature of etext, the illustrated portion of the Dictionary has not been included.
This dictionary is from "Hitchcock's New and Complete Analysis of the Holy Bible," published in the late 1800s. It contains more than 2,500 Bible and Bible-related proper names and their meanings. Some Hebrew words of uncertain meaning have been left out. It is out of copyright, so feel free to copy and distribute it. I pray it will help in your study of God's Word. --Brad Haugaard
This dictionary database was created by Jay Kominek <jfk at acm.org>.
This somewhat typically short sighted view of the World (sorry I love America, I lived there for a while - its great, but it is not ALL THE WORLD!), really only becomes useful if you look in the index file and see that there are Appendix's, these are though of limited use to normal people, who think that the world ends at their keyboard.
The Jargon File is a comprehensive compendium of hacker slang illuminating many aspects of hackish tradition, folklore, and humor. This bears remarkable similarity to FOLDOC above.
_The Devil's Dictionary_ was begun in a weekly paper in 1881, and was continued in a desultory way at long intervals until 1906. In that year a large part of it was published in covers with the title _The Cynic's Word Book_, a name which the author had not the power to reject or happiness to approve. Users of the fortune program will already have some familiarity with this ;-).
Who Was Who: 5000 B. C. to Date: Biographical Dictionary of the Famous and Those Who Wanted to Be, edited by Irwin L. Gordon
OTHER DICTIONARIES
A number of other dictionaries have been made available, see the dict home page for details. In many cases you may find the program to convert dictionary data to the format dict requires has not been written yet ;-(
As mentioned elsewhere, there are a number of translation dictionaries also available (see below).
The links given here were correct at the time of writing. If it is a long time since this paper was published you should visit http://www.dict.org to see what has changed.
Unfortunately installation of the above mentioned software did not go quite as easily as it should have, which partly explains why I am writing this;-).
The first thing you will need is plenty of disk space. The largest dictionary available is Webster's 1913 dictionary, which will need about 85Meg to be re-built in.
Unarchive dictd-1.5.5.tar.gz in the normal manner.
IMPORTANT:- The HTML support has been turned off in this version of dict. You need to turn it back on if you want to take advantage of Kdict.
Load the file dict.c into your favorite editor and remove the comments from line 1069:-
{ "raw", 0, 0, 'r' },
{ "pager", 1, 0, 'P' },
{ "debug", 1, 0, 502 },
{ "html", 0, 0, 503 }, //Remove comments from this line
{ "pipesize", 1, 0, 504 },
{ "client", 1, 0, 505 },
so the file becomes as above.
Now you can run ./configure;make;make install. You will see a great many warnings produced by the compiler, but at the end you should have working client, server and compression program installed.
Unpack the files dict-web1913-1.4.tar.gz and web1913-0.46-a.tar.gz:
$ tar xvzf dict-web1913-1.4.tar.gz
$ tar xvzf web1913-0.46-a.tar.gz
$ cd dict-web1913-1.4
$ mkdir web1913
$ cp ../web1913-0.46-a/* web1913
$ ./configure
$ make
$ make db
Now go make a cup of tea, this takes over an hour on my 133MHz box. When done, decide on a place for your dictionaries to live and copy them there, I use /opt/public/dict-dbs as suggested:-
$ mkdir /opt/public/dict-dbs
$ cp web1913.dict.dz /opt/public/dict-dbs
$ cp web1913.index /opt/public/dict-dbs
Grab dict-wn-1.5.tar.gz
It is a great shame that one of the most useful dictionaries is also the one that refuses to compile correctly. To create a viable dictionary the original data must be parsed by a program. When you do make it is this program that is created. Unfortunately this package uses a Makefile created by ./configure which does not work. I am unable to correct the automake procedure but can assure you that the following will work:
$ tar xvzf dict-wn-1.5.tar.gz $ cd dict-wn-1.5 $ ./configure $ gcc -o wnfilter wnfilter.c $ make db
Again this process takes a considerable amount of time ( > 1 hour on my 133MHz). Once complete if you have not already created a directory for your dictionaries do so now and copy the dictionary and its index there:
$ cp wn.dict.dz /opt/public/dict-dbs $ cp wn.index /opt/public/dict-dbs
Grab dict-misc-1.5.tar.gz
$ tar xvzf dict-misc-1.5.tar.gz $ cd dict-misc-1.5 $ ./configure $ make $ make db $ cp easton.dict.dz /opt/public/dict-dbs $ cp easton.index /opt/public/dict-dbs $ cp elements.dict.dz /opt/public/dict-dbs $ cp elements.index /opt/public/dict-dbs $ cp foldoc.dict.dz /opt/public/dict-dbs $ cp foldoc.index /opt/public/dict-dbs $ cp hitchcock.dict.dz /opt/public/dict-dbs $ cp hitchcock.index /opt/public/dict-dbs $ cp jargon.dict.dz /opt/public/dict-dbs $ cp jargon.index /opt/public/dict-dbs
$ tar xvzf dict-jargon-4.2.0.tar.gz $ cd dict-jargon-4.2.0 $ ./configure $ make $ make db $ cp jargon.dict.dz /opt/public/dict-dbs $ cp jargon.index /opt/public/dict-dbs
Grab dict-gazetteer-1.3.tar.gz
$ tar xvzf dict-gazetteer-1.3.tar.gz $ cd dict-gazetteer-1.3 $ ./configure $ make $ make db $ cp gazetteer.dict.dz /opt/public/dict-dbs $ cp gazetteer.index /opt/public/dict-dbs
As with the language dictionaries below, the dictionary has already been created for you. Simply unpack this file in your dictionary directory.
Grab http://www.hawklord.uklinux.net/dict/www-1.0.tgz
$ tar xvzf www-1.0.tgz $ cd www-1.0 $ ./configure $ make $ make db $ cp www.dict.dz /opt/public/dict-dbs $ cp www.index /opt/public/dict-dbs
Visit ftp://ftp.dict.org/pub/dict/pre/www.freedict.de/20000906
Installing a language dictionary does not involve re-building the dictionary from original data, so you just need to unpack each file into you dictionary directory.
dictd expects to find the file /etc/dictd.conf, though an alternative file may be specified on the command line. Each dictionary needs to be specified in this file so dictd can find the dictionary and its index. For example if you just want to use Webster's, WordNet and The Devils Dictionary, then the following entries will be required (assuming you use /opt/public/dict-dbs as your dictionary directory):
database Web-1913 { data "/opt/public/dict-dbs/web1913.dict.dz"
index "/opt/public/dict-dbs/web1913.index" }
database wn { data "/opt/public/dict-dbs/wn.dict.dz"
index "/opt/public/dict-dbs/wn.index" }
database devils { data "/opt/public/dict-dbs/devils.dict.dz"
index "/opt/public/dict-dbs/devils.index" }
It seems it is possible to implement user access control and other security measures. I have not tried this. If I were into security issues the current state of the software gives me no reason to trust any security feature it might have. But why anyone would want to restrict access to these dictionaries is completely beyond me, this is stuff any user has a right to use.
You should be aware of a number of security issues if you intend to make dictd available over a local network since not being aware will leave your server vulnerable to a number of possible attacks.
Unless you are installing dictd on a server for a school/college or for some other large network these issues will probably be of no concern to you. If you are installing on such a network then you should already be aware of the issues below.
All these symptoms can occur if a number of users send queries like MATCH * re . at the same time. Such queries return the whole database index and each instance will require around 5MB buffer space on the server.
Possible solutions include limiting the number of connections to the server, limiting the amount of data that can be returned for a single query or limiting the number of simultaneous outstanding searches.
The server can be driven to a complete stand still by any evil minded cracker that wants to connect to the server 1,000,000 times.
To prevent such anti-social behavior simply limit the number of connections based on IP or mask.
If you experience this kind of problem you should make your logging routines more robust, use strlen and examine daemon_log.
dict expects to find the file /etc/dict.conf. This file should contain a line with the name of the machine you wish to use as your dictd server, though this can be overridden at the command line.
The current version of dict is a little disappointing as a users front-end for dictd. If all you have is a console and you can't use Kdict then you will just have to get used to dict. The worst thing about dict is that it can trash your console and you will need to take action (such as logging out and back in) to restore the keyboard to normal! This typically occurs if there is a problem with dictd; such as when it is not running and you try to use dict.
Since dict is just a console program, it just sends output to less. So unless you have a very good memory you will need to use `cut and paste' to transfer referenced words or phrases back to the command line.
There is an option to send output to a pager program. I tried the command dict -html -P lynx luser, the result was not a happy one! Lynx went mad, referencing random help and configuration files in a manner that reminded me of certain viruses in MS operating systems.
Personally I would say if you can avoid using dict directly, avoid it! It is necessary to have it if you want to use Kdict, and you do want to use Kdict.
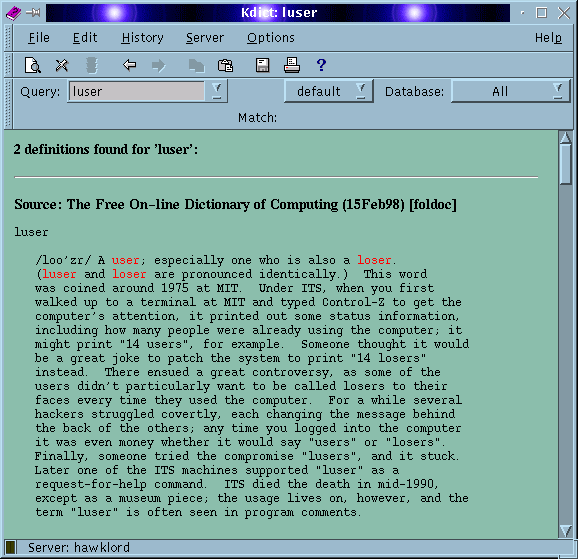
To take full advantage of dict you really need Kdict from http://www.rhrk.uni-kl.de/~gebauerc/kdict. I have used version 0.2 and cannot speak for any other version.
To use Kdict you must turn HTML support back on for dict as described above.
The screen shot above shows Kdict in use. Kdict makes good use of the limited HTML tags provided by dict, and inserts extra tags so that you can easily cross-reference words. Any phrase or word shown in red can be clicked on with the mouse to show its definition.
What makes Kdict so good is the fact that you can use the clipboard to highlight a word from any window on the desktop and paste it into Kdict as a query.
This is a great project that can only get better, so it is a lot like Linux and gnu software in general... Give it your full support!
If you get xscrabble from Matt Chapman's homepage, you can enhance your enjoyment of the game by looking up the definitions of words you don't know, - as the computer beats the sh*t out of you;-).